5 Linguistic Sorting and Matching
This chapter explains linguistic sorting and searching for strings in an Oracle Database environment. The process of determining the mutual ordering of strings (character values) is called a collation. For any two strings, the collation defines whether the strings are equal or whether one precedes the other in the sorting order. In the Oracle documentation, the term sort is often used in place of collation.
Determining equality is especially important when a set of strings, such as a table column, is searched for values that equal a specified search term or that match a search pattern. SQL operators and functions used in searching are =, LIKE, REGEXP_LIKE, INSTR, and REGEXP_INSTR. This chapter uses the term matching to mean determining the equality of entire strings using the equality operator = or determining the equality of substrings of a string when the string is matched against a pattern using LIKE, REGEXP_LIKE or REGEXP_INSTR. Note that Oracle Text provides advanced full-text searching capabilities for the Oracle Database.
The ordering of strings in a set is called sorting. For example, the ORDER BY clause uses collation to determine the ordering of strings to sort the query results, while PL/SQL uses collations to sort strings in associative arrays indexed by VARCHAR2 values, and the functions MIN, MAX, GREATEST, and LEAST use collations to find the smallest or largest character value.
There are many possible collations that can be applied to strings to determine their ordering. Collations that take into consideration the standards and customs of spoken languages are called linguistic collations. They order strings in the same way as dictionaries, phone directories, and other text lists written in a given language. In contrast, binary collation orders strings based on their binary representation (character encoding), treating each string as a simple sequences of bytes.
This chapter contains the following topics:
Overview of Oracle Database Collation Capabilities
Different languages have different collations. In addition, different cultures or countries that use the same alphabets may sort words differently. For example, in Danish, Æ is after Z, while Y and Ü are considered to be variants of the same letter.
Collation can be case-sensitive or case-insensitive. Case refers to the condition of being uppercase or lowercase. For example, in a Latin alphabet, A is the uppercase glyph for a, the lowercase glyph.
Collation can ignore or consider diacritics. A diacritic is a mark near or through a character or combination of characters that indicates a different sound than the sound of the character without the diacritic. For example, the cedilla (,) in façade is a diacritic. It changes the sound of c.
Collation order can be phonetic or it can be based on the appearance of the character. For example, collation can be based on the number of strokes in East Asian ideographs. Another common collation issue is combining letters into a single character. For example, in traditional Spanish, ch is a distinct character that comes after c, which means that the correct order is: cerveza, colorado, cheremoya. This means that the letter c cannot be sorted until Oracle Database has checked whether the next letter is an h.
Oracle Database provides the following types of collation:
-
Binary
-
Monolingual
-
Multilingual
-
Unicode Collation Algorithm (UCA)
While monolingual collation achieves a linguistically correct order for a single language, multilingual collation and UCA collation are designed to handle many languages at the same time. Furthermore, UCA collation conforms to the Unicode Collation Algorithm (UCA) that is a Unicode standard and is fully compatible with the international collation standard ISO 14651. The UCA standard provides a complete linguistic ordering for all characters in Unicode, hence all the languages around the world. With wide deployment of Unicode application, UCA collation is best suited for sorting multilingual data.
Using Binary Collation
One way to sort character data is based on the numeric values of the characters defined by the character encoding scheme. This is called a binary collation. Binary collation is the fastest type of sort. It produces reasonable results for the English alphabet because the ASCII and EBCDIC standards define the letters A to Z in ascending numeric value.
Note:
In the ASCII standard, all uppercase letters appear before any lowercase letters. In the EBCDIC standard, the opposite is true: all lowercase letters appear before any uppercase letters.When characters used in other languages are present, a binary collation usually does not produce reasonable results. For example, an ascending ORDER BY query returns the character strings ABC, ABZ, BCD, ÄBC, when Ä has a higher numeric value than B in the character encoding scheme. A binary collation is not usually linguistically meaningful for Asian languages that use ideographic characters.
Using Linguistic Collation
To produce a collation sequence that matches the alphabetic sequence of characters, another sorting technique must be used that sorts characters independently of their numeric values in the character encoding scheme. This technique is called a linguistic collation. A linguistic collation operates by replacing characters with numeric values that reflect each character's proper linguistic order.
This section includes the following topics:
Monolingual Collation
Oracle Database compares character strings in two steps for monolingual collation. The first step compares the major value of the entire string from a table of major values. Usually, letters with the same appearance have the same major value. The second step compares the minor value from a table of minor values. The major and minor values are defined by Oracle Database. Oracle Database defines letters with diacritic and case differences as having the same major value but different minor values.
Each major table entry contains the Unicode code point and major value for a character. The Unicode code point is a 16-bit binary value that represents a character.
Table 5-1 illustrates sample values for sorting a, A, ä, Ä, and b.
Table 5-1 Sample Glyphs and Their Major and Minor Sort Values
| Glyph | Major Value | Minor Value |
|---|---|---|
|
a |
15 |
5 |
|
A |
15 |
10 |
|
ä |
15 |
15 |
|
Ä |
15 |
20 |
|
b |
20 |
5 |
Note:
Monolingual collation is not available for non-Unicode multibyte database character sets. If a monolingual collation is specified when the database character set is non-Unicode multibyte, then the default sort order is the binary sort order of the database character set. One exception isUNICODE_BINARY. This collation is available for all character sets.See Also:
"What is the Unicode Standard?"Multilingual Collation
Oracle Database provides multilingual collation so that you can sort data in more than one language in one sort. This is useful for regions or languages that have complex sorting rules and for multilingual databases. As of Oracle Database 12c, Oracle Database supports all of the collations defined by previous releases.
For Asian language data or multilingual data, Oracle Database provides a sorting mechanism based on the ISO 14651 standard. For example, Chinese characters can be ordered by the number of strokes, PinYin, or radicals.
In addition, multilingual collation can handle canonical equivalence and supplementary characters. Canonical equivalence is a basic equivalence between characters or sequences of characters. For example, ç is equivalent to the combination of c and ,. Supplementary characters are user-defined characters or predefined characters in Unicode that require two code points within a specific code range. You can define up to 1.1 million code points in one multilingual sort.
For example, Oracle Database supports a monolingual French sort (FRENCH), but you can specify a multilingual French collation (FRENCH_M). _M represents the ISO 14651 standard for multilingual sorting. The sorting order is based on the GENERIC_M sorting order and can sort diacritical marks from right to left. Multilingual linguistic sort is usually used if the tables contain multilingual data. If the tables contain only French, then a monolingual French sort might have better performance because it uses less memory. It uses less memory because fewer characters are defined in a monolingual French sort than in a multilingual French sort. There is a trade-off between the scope and the performance of a sort.
Multilingual Collation Levels
Oracle Database evaluates multilingual collation at three levels of precision:
Primary Level Collation
A primary level collation distinguishes between base letters, such as the difference between characters a and b. It is up to individual locales to define whether a is before b, b is before a, or if they are equal. The binary representation of the characters is completely irrelevant. If a character is an ignorable character, then it is assigned a primary level order (or weight) of zero, which means it is ignored at the primary level. Characters that are ignorable on other levels are given an order of zero at those levels.
For example, at the primary level, all variations of bat come before all variations of bet. The variations of bat can appear in any order, and the variations of bet can appear in any order:
Bat bat BAT BET Bet bet
See Also:
"Ignorable Characters"Secondary Level Collation
A secondary level collation distinguishes between base letters (the primary level collation) before distinguishing between diacritics on a given base letter. For example, the character Ä differs from the character A only because it has a diacritic. Thus, Ä and A are the same on the primary level because they have the same base letter (A) but differ on the secondary level.
The following list has been sorted on the primary level (resume comes before resumes) and on the secondary level (strings without diacritics come before strings with diacritics):
resume résumé Résumé Resumes resumes résumés
Tertiary Level Collation
A tertiary level collation distinguishes between base letters (primary level collation), diacritics (secondary level collation), and case (upper case and lower case). It can also include special characters such as +, -, and *.
The following are examples of tertiary level collations:
-
Characters
aandAare equal on the primary and secondary levels but different on the tertiary level because they have different cases. -
Characters
äandAare equal on the primary level and different on the secondary and tertiary levels. -
The primary and secondary level orders for the dash character
-is 0. That is, it is ignored on the primary and secondary levels. If a dash is compared with another character whose primary level weight is nonzero, for example,u, then no result for the primary level is available becauseuis not compared with anything. In this case, Oracle Database finds a difference between-anduonly at the tertiary level.
The following list has been sorted on the primary level (resume comes before resumes) and on the secondary level (strings without diacritics come before strings with diacritics) and on the tertiary level (lower case comes before upper case):
resume Resume résumé Résumé resumes Resumes résumés Résumés
UCA Collation
The Unicode Collation Algorithm (UCA) is a Unicode standard that is fully compatible with the international collation standard ISO 14651. The UCA defines a Default Unicode Collation Element Table (DUCET) that provides a reasonable default ordering for all languages that are not tailored. To achieve the correct ordering for a particular language, DUCET can be tailored to meet the linguistic requirements for that language. There are tailorings of DUCET for various languages provided in the Unicode Common Locale Data Repository. For details of the UCA and related terminologies, see the Unicode Collation Algorithm at http://www.unicode.org.
Oracle Database provides UCA collation that fully conforms to the UCA 6.2.0 as of Oracle Database 12c (12.1.0.2). In addition to the collation based on DUCET, it provides tailored collations for a number of commonly used languages. For example, you can specify the UCA collation, UCA0620_SCHINESE, to sort multilingual data containing Simplified Chinese. The collation will make Simplified Chinese data appear in the PinYin order.
For sorting multilingual data, Oracle Corporation recommends UCA collation.
UCA Comparison Levels
Similar to multilingual collation, UCA collations employ a multilevel comparison algorithm to evaluate characters. This can go up to four levels of comparison:
Primary Level
The primary level is used to distinguish between base letters, which is similar to the comparison used in the primary level collation of the multilingual collation.
See Also:
"Primary Level Collation" for examples of base letter differencesSecondary Level
The secondary level is used to distinguish between diacritics if base letters are the same, which is similar to what is used in the secondary level collation of the multilingual collation to distinguish between diacritics.
See Also:
"Secondary Level Collation" for examples of diacritic differencesTertiary Level
The tertiary level is used to distinguish between cases on a given base letter with the same diacritic, which is similar to what is used in the tertiary level collation of the multilingual collation to distinguish between cases. Moreover, UCA DUCET collation treats punctuations with primary or quaternary significance based on how variable characters are weighted, which is different from the tertiary level collation of the multilingual collation that treat punctuations with tertiary level of significance.
See Also:
"Tertiary Level Collation" for examples of characters with case differencesQuaternary Level
The quaternary level is used to distinguish variable characters from other characters if variable characters are weighted as shifted. It is also used to distinguish Hiragana from Katakana with the same base and case. An example is illustrated in Figure 5-1.
Figure 5-1 Hiragana and Katakana Collation
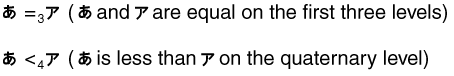
Description of ''Figure 5-1 Hiragana and Katakana Collation''
See Also:
"UCA Collation Parameters"UCA Collation Parameters
Table 5-2 illustrates the collation parameters and options that are supported in UCA collations in Oracle Database 12c.
Table 5-2 UCA Collation Parameters
| Attribute | Options | Collation Modifier |
|---|---|---|
|
|
primary secondary tertiary quaternary |
|
|
|
non-ignorable shifted blanked |
|
|
|
on off |
|
|
|
on |
|
|
|
off |
|
|
|
upper off |
|
|
|
on off |
|
|
|
off |
|
|
|
minimal |
|
Footnote 1 _S4: Applicable only when alternate is shifted
Footnote 2 _FU: Only valid for Danish
Footnote 3 _FN: Only valid for other languages
The parameter strength represents UCA comparison level (see "UCA Comparison Levels"). The parameter alternate controls how variable characters are weighted (see "Variable Characters and Variable Weighting"). The parameter backwards controls if diacritics are to be sorted backward (see "Reverse Secondary Sorting"). Users can configure these three UCA parameters using the options listed in Table 5-2. The options for the other parameters listed in Table 5-2 are currently fixed based on tailored languages and not configurable as of Oracle Database 12c.
For a complete description of UCA collation parameters and options, see the Unicode Collation Algorithm standard at: http://www.unicode.org.
Linguistic Collation Features
This section contains information about different features that a linguistic collation can have:
You can customize linguistic collations to include the desired characteristics.
See Also:
Chapter 12, "Customizing Locale Data"Base Letters
Base letters are defined in a base letter table, which maps each letter to its base letter. For example, a, A, ä, and Ä all map to a, which is the base letter. This concept is particularly relevant for working with Oracle Text.
See Also:
Oracle Text ReferenceIgnorable Characters
In multilingual collation and UCA collation, certain characters may be treated as ignorable. Ignorable characters are skipped, that is, treated as non-existent, when two character values (strings) containing such characters are compared in a sorting or matching operation. There are three kinds of ignorable characters: primary, secondary, and tertiary.
Primary Ignorable Characters
Primary ignorable characters are ignored when the multilingual collation or UCA collation definition applied to the given comparison has the accent-insensitivity modifier _AI, for example, GENERIC_M_AI or UCA0620_DUCET_AI. Primary ignorable characters are comprised of diacritics (accents) from various alphabets (Latin, Cyrillic, Greek, Devanagari, Katakana, and so on) but also of decorating modifiers, such as an enclosing circle or enclosing square. These characters are non-spacing combining characters, which means they combine with the preceding character to form a complete accented or decorated character ("non-spacing" means that the character occupies the same character position on screen or paper as the preceding character). For example, the character "Latin Small Letter e" followed by the character "Combining Grave Accent" forms a single letter "è", while the character "Latin Capital Letter A" followed by the "Combining Enclosing Circle" forms a single character "(A)". Because non-spacing characters are defined as ignorable for accent-insensitive sorts, these sorts can treat, for example, rôle as equal to role, naïve as equal to naive, and (A)(B)(C) as equal to ABC.
Primary ignorable characters are called non-spacing characters when viewed in a multilingual collation definition in the Oracle Locale Builder utility.
Secondary Ignorable Characters
Secondary ignorable characters are ignored when the applied definition has either the accent-insensitivity modifier _AI or the case-insensitivity modifier _CI.
In multilingual collation, secondary ignorable characters are comprised of punctuation characters, such as the space character, new line control codes, dashes, various quote forms, mathematical operators, dot, comma, exclamation mark, various bracket forms, and so on. In accent-insensitive (_AI) and case-insensitive (_CI) sorts, these punctuation characters are ignored so that multi-lingual can be treated as equal to multilingual and e-mail can be treated as equal to email.
Secondary ignorable characters are called punctuation characters when viewed in a multilingual collation definition in the Oracle Locale Builder utility.
There are no secondary ignorable characters defined in the UCA DUCET, however. Punctuations are treated as variable characters in the UCA.
Tertiary Ignorable Characters
Tertiary ignorable characters are generally ignored in linguistic comparison. They are mainly comprised of control codes, format characters, variation selectors, and so on.
Primary and secondary ignorable characters are not ignored when a standard, case- and accent-sensitive sort is used. However, they have lower priority when determining the order of strings. For example, multi-lingual is sorted after multilingual in the GENERIC_M sort, but it is still sorted between multidimensional and multinational. The comparison d < l < n of the base letters has higher priority in determining the order than the presence of the secondary ignorable character HYPHEN (U+002D).
You can see the full list of non-spacing characters and punctuation characters in a multilingual collation definition when viewing the definition in the Oracle Locale Builder. Generally, neither punctuation characters nor non-spacing characters are included in monolingual collation definitions. In some monolingual collation definitions, the space character and the tabulator character may be included. The comparison algorithm automatically assigns a minor value to each undefined character. This makes punctuation characters non-ignorable but, as in the case of multilingual collations, considered with lower priority when determining the order of compared strings. The ordering among punctuation characters in monolingual collations is based on their Unicode code points and may not correspond to user expectations.
Variable Characters and Variable Weighting
There are characters defined with variable collation elements in the UCA. These characters are called variable characters and are comprised of white space characters, punctuations, and certain symbols.
Variable characters can be weighted differently in UCA collations to adjust the effect of these characters in a sorting or comparison, which is called variable weighting. The collation parameter, alternate, controls how it works. The following options on variable weighting are supported in UCA collations as of Oracle Database 12c:
-
blankedVariable characters are treated as ignorable characters. For example, SPACE (U+0020) is ignored in comparison.
-
non-ignorableVariable characters are treated as if they were not ignorable characters. For example, SPACE (U+0020) is not ignored in comparison at primary level.
-
shiftedVariable characters are treated as ignorable characters on the primary, secondary and tertiary levels. In addition, a new quaternary level is used for all characters. The quaternary weight of a character depends on if the character is a variable, ignorable, or other. For example, SPACE (U+0020) is assigned a quaternary weight differently from A (U+0041) because SPACE is a variable character while A is neither a variable nor an ignorable character.
See Also:
"UCA Collation Parameters"Examples of Variable Weighting
This section includes different examples of variable weighting.
Example 5-1 UCA DUCET Order When Variable is Weighed as Blanked
The following list has been sorted using UCA0620_DUCET_VB:
blackbird Blackbird Black-bird Black bird BlackBird
Blackbird, Black-bird, and Black bird have the same collation weight because SPACE(U+0020) and HYPHEN(U+002D) are treated as ignorable characters. Selecting only the distinct entries illustrates this behavior (note that only Blackbird is shown in the result):
blackbird Blackbird BlackBird
Blackbird, Black-bird, and Black bird are sorted after blackbird due to case difference on the first letter B (U+0042), but before BlackBird due to case difference at the second b (U+0062).
Example 5-2 UCA DUCET Order When Variable is Weighed as Non-Ignorable
The following list has been sorted using UCA0620_DUCET_VN:
Black bird Black-bird blackbird Blackbird BlackBird
Black bird and Black-bird are sorted before blackbird because both SPACE (U+0020) and HYPHEN (U+002D) are not treated as ignorable characters but they are smaller than b (U+0062) at the primary level. Black bird is sorted before Black-bird because SPACE (U+0020) is small than HYPHEN (U+002D) at the primary level.
Example 5-3 UCA DUCET Order When Variable is Weighed as Shifted
The following list has been sorted using UCA0620_DUCET:
blackbird Black bird Black-bird Blackbird BlackBird
blackbird is sorted before Black bird and Black-bird because both SPACE (U+0020) and HYPHEN (U+002D) are ignored at the first three levels, and there is a case difference on the first letter b (U+0062). Black-bird is sorted before Blackbird is because HYPHEN (U+002D) has a small quaternary weight than the letter b (U+0062) in Blackbird.
Contracting Characters
Collation elements usually consist of a single character, but in some locales, two or more characters in a character string must be considered as a single collation element during sorting. For example, in traditional Spanish, the string ch is composed of two characters. These characters are called contracting characters in multilingual collation and special combination letters in monolingual collation.
Do not confuse a composed character with a contracting character. A composed character like á can be decomposed into a and ', each with their own encoding. The difference between a composed character and a contracting character is that a composed character can be displayed as a single character on a terminal, while a contracting character is used only for sorting, and its component characters must be rendered separately.
Expanding Characters
In some locales, certain characters must be sorted as if they were character strings. An example is the German character ß (sharp s). It is sorted exactly the same as the string SS. Another example is that ö sorts as if it were oe, after od and before of. These characters are known as expanding characters in multilingual collation and special letters in monolingual collation. Just as with contracting characters, the replacement string for an expanding character is meaningful only for sorting.
Context-Sensitive Characters
In Japanese, a prolonged sound mark that resembles an em dash — represents a length mark that lengthens the vowel of the preceding character. The sort order depends on the vowel that precedes the length mark. This is called context-sensitive collation. For example, after the character ka, the — length mark indicates a long a and is treated the same as a, while after the character ki, the — length mark indicates a long i and is treated the same as i. Transliterating this to Latin characters, a sort might look like this:
kaa ka— -- kaa and ka— are the same kai -- kai follows ka- because i is after a kia -- kia follows kai because i is after a kii -- kii follows kia because i is after a ki— -- kii and ki— are the same
Canonical Equivalence
Canonical equivalence is an attribute of a multilingual collation and describes how equivalent code point sequences are sorted. If canonical equivalence is applied in a particular multilingual collation, then canonically equivalent strings are treated as equal.
One Unicode code point can be equivalent to a sequence of base letter code points plus diacritic code points. This is called the Unicode canonical equivalence. For example, ä equals its base letter a and an umlaut. A linguistic flag, CANONICAL_EQUIVALENCE = TRUE, indicates that all canonical equivalence rules defined in Unicode need to be applied in a specific multilingual collation. Oracle Database-defined multilingual collations include the appropriate setting for the canonical equivalence flag. You can set the flag to FALSE to speed up the comparison and ordering functions if all the data is in its composed form.
For example, consider the following strings:
-
äa(aumlaut followed bya) -
a¨b(afollowed by umlaut followed byb) -
äc(aumlaut followed byc)
If CANONICAL_EQUIVALENCE=FALSE, then the sort order of the strings is:
a¨b äa äc
This occurs because a comes before ä if canonical equivalence is not applied.
If CANONICAL_EQUIVALENCE=TRUE, then the sort order of the strings is:
äa a¨b äc
This occurs because ä and a¨ are treated as canonically equivalent.
You can use Oracle Locale Builder to view the setting of the canonical equivalence flag in existing multilingual collations. When you create a customized multilingual collation with Oracle Locale Builder, you can set the canonical equivalence flag as desired.
See Also:
"Creating a New Linguistic Sort with the Oracle Locale Builder" for more information about setting the canonical equivalence flagReverse Secondary Sorting
In French, sorting strings of characters with diacritics first compares base letters from left to right, but compares characters with diacritics from right to left. For example, by default, a character with a diacritic is placed after its unmarked variant. Thus Èdit comes before Edít in a French sort. They are equal on the primary level, and the secondary order is determined by examining characters with diacritics from right to left. Individual locales can request that the characters with diacritics be sorted with the right-to-left rule. Set the REVERSE_SECONDARY linguistic flag to TRUE to enable reverse secondary sorting.
See Also:
"Creating a New Linguistic Sort with the Oracle Locale Builder" for more information about setting the reverse secondary flagCharacter Rearrangement for Thai and Laotian Characters
In Thai and Lao, some characters must first change places with the following character before sorting. Normally, these types of characters are symbols representing vowel sounds, and the next character is a consonant. Consonants and vowels must change places before sorting. Set the SWAP_WITH_NEXT linguistic flag for all characters that must change places before sorting.
See Also:
"Creating a New Linguistic Sort with the Oracle Locale Builder" for more information about setting theSWAP_WITH_NEXT flagSpecial Letters
Special letters is a term used in monolingual collation. They are called expanding characters in multilingual collation.
See Also:
"Expanding Characters"Special Combination Letters
Special combination letters is the term used in monolingual collations. They are called contracting letters in multilingual collation.
See Also:
"Contracting Characters"Special Uppercase Letters
One lowercase letter may map to multiple uppercase letters. For example, in traditional German, the uppercase letters for ß are SS.
These case conversions are handled by the NLS_UPPER, NLS_LOWER, and NLS_INITCAP SQL functions, according to the conventions established by the linguistic collations. The UPPER, LOWER, and INITCAP SQL functions cannot handle these special characters, because their casing operation is based on binary mapping defined for the underlying character set, which is not linguistic sensitive.
The NLS_UPPER SQL function returns all uppercase characters from the same character set as the lowercase string. The following example shows the result of the NLS_UPPER function when NLS_SORT is set to XGERMAN:
SELECT NLS_UPPER ('große') "Uppercase" FROM DUAL;
Upper
-----
GROSSE
See Also:
Oracle Database SQL Language ReferenceCase-Insensitive and Accent-Insensitive Linguistic Collation
Operation inside an Oracle database is always sensitive to the case and the accents (diacritics) of the characters. Sometimes you may need to perform case-insensitive or accent-insensitive comparisons and collations.
In previous versions of the database, case-insensitive queries could be achieved by using the NLS_UPPER and NLS_LOWER SQL functions. The functions change the case of strings based on a specific linguistic collation definition. This enables you to perform case-insensitive searches regardless of the language being used. For example, create a table called test1 as follows:
SQL> CREATE TABLE test1(word VARCHAR2(12));
SQL> INSERT INTO test1 VALUES('GROSSE');
SQL> INSERT INTO test1 VALUES('Große');
SQL> INSERT INTO test1 VALUES('große');
SQL> SELECT * FROM test1;
WORD
------------
GROSSE
Große
große
Perform a case-sensitive search for GROSSE as follows:
SQL> SELECT word FROM test1 WHERE word='GROSSE'; WORD ------------ GROSSE
Perform a case-insensitive search for GROSSE using the NLS_UPPER function:
SELECT word FROM test1 WHERE NLS_UPPER(word, 'NLS_SORT = XGERMAN') = 'GROSSE'; WORD ------------ GROSSE Große große
Oracle Database provides case-insensitive and accent-insensitive options for collation. It provides the following types of linguistic collations:
-
Linguistic collations that use information about base letters, diacritics, punctuation, and case. These are the standard linguistic collations that are described in "Using Linguistic Collation".
-
Monolingual collations that use information about base letters, diacritics, and punctuation, but not case, and multilingual and UCA collations that use information about base letters and diacritics, but not case or punctuation. This type of sort is called case-insensitive.
-
Monolingual collations that use information about base letters and punctuation only, and multilingual and UCA collations that use information about base letters only. This type of sort is called accent-insensitive. (Accent is another word for diacritic.) Like case-insensitive sorts, an accent-insensitive sort does not use information about case.
Accent- and case-insensitive multilingual collations ignore punctuation characters as described in "Ignorable Characters".
The rest of this section contains the following topics:
-
Specifying a Case-Insensitive or Accent-Insensitive Collation
-
Examples: Linguistic Collation
See Also:
Examples: Case-Insensitive and Accent-Insensitive Collation
The following examples show:
-
A collation that uses information about base letters, diacritics, punctuation, and case
-
A case-insensitive collation
-
An accent-insensitive collation
Example 5-4 Linguistic Collation Using Base Letters, Diacritics, Punctuation, and Case Information
The following list has been sorted using information about base letters, diacritics, punctuation, and case:
blackbird black bird black-bird Blackbird Black-bird blackbîrd bläckbird
Example 5-5 Case-Insensitive Linguistic Collation
The following list has been sorted using information about base letters, diacritics, and punctuation, ignoring case:
black bird black-bird Black-bird blackbird Blackbird blackbîrd bläckbird
black-bird and Black-bird have the same value in the collation, because the only different between them is case. They could appear interchanged in the list. Blackbird and blackbird also have the same value in the collation and could appear interchanged in the list.
Specifying a Case-Insensitive or Accent-Insensitive Collation
Use the NLS_SORT session parameter to specify a case-insensitive or accent-insensitive collation:
-
Append
_CIto an Oracle Database collation name for a case-insensitive collation. -
Append
_AIto an Oracle Database collation name for an accent-insensitive and case-insensitive collation.
For example, you can set NLS_SORT to the following types of values:
UCA0620_SPANISH_AI FRENCH_M_AI XGERMAN_CI
Binary collation can also be case-insensitive or accent-insensitive. When you specify BINARY_CI as a value for NLS_SORT, it designates a collation that is accent-sensitive and case-insensitive. BINARY_AI designates an accent-insensitive and case-insensitive binary collation. You may want to use a binary collation if the binary collation order of the character set is appropriate for the character set you are using.
For example, with the NLS_LANG environment variable set to AMERICAN_AMERICA.WE8ISO8859P1, create a table called test2 and populate it as follows:
SQL> CREATE TABLE test2 (letter VARCHAR2(10));
SQL> INSERT INTO test2 VALUES('ä');
SQL> INSERT INTO test2 VALUES('a');
SQL> INSERT INTO test2 VALUES('A');
SQL> INSERT INTO test2 VALUES('Z');
SQL> SELECT * FROM test2;
LETTER
-----------
ä
a
A
Z
The default value of NLS_SORT is BINARY. Use the following statement to do a binary collation of the characters in table test2:
SELECT * FROM test2 ORDER BY letter;
To change the value of NLS_SORT, enter a statement similar to the following:
ALTER SESSION SET NLS_SORT=BINARY_CI;
The following table shows the collation orders that result from setting NLS_SORT to BINARY, BINARY_CI, and BINARY_AI.
| BINARY | BINARY_CI | BINARY_AI |
|---|---|---|
A |
a |
ä |
Z |
A |
a |
a |
Z |
A |
ä |
ä |
Z |
When NLS_SORT=BINARY, uppercase letters come before lowercase letters. Letters with diacritics appear last.
When the collation considers diacritics but ignores case (BINARY_CI), the letters with diacritics appear last.
When both case and diacritics are ignored (BINARY_AI), ä is sorted with the other characters whose base letter is a. All the characters whose base letter is a occur before z.
You can use binary collation for better performance when the character set is US7ASCII or another character set that has the same collation order as the binary collation.
The following table shows the collation orders that result from German collation for the table.
| GERMAN | GERMAN_CI | GERMAN_AI |
|---|---|---|
a |
a |
ä |
A |
A |
a |
ä |
ä |
A |
Z |
Z |
Z |
A German collation places lowercase letters before uppercase letters, and ä occurs before Z. When the collation ignores both case and diacritics (GERMAN_AI), ä appears with the other characters whose base letter is a.
Examples: Linguistic Collation
The examples in this section demonstrate a binary collation, a monolingual collation, and a UCA collation. To prepare for the examples, create and populate a table called test3. Enter the following statements:
SQL> CREATE TABLE test3 (name VARCHAR2(20));
SQL> INSERT INTO test3 VALUES('Diet');
SQL> INSERT INTO test3 VALUES('À voir');
SQL> INSERT INTO test3 VALUES('Freizeit');
The ORDER BY clause uses a binary collation.
SQL> SELECT * FROM test3 ORDER BY name;
You should see the following output:
Diet Freizeit À voir
Note that a binary collation results in À voir being at the end of the list.
Example 5-8 Monolingual German Collation
Use the NLSSORT function with the NLS_SORT parameter set to german to obtain a German collation.
SQL> SELECT * FROM test3 ORDER BY NLSSORT(name, 'NLS_SORT=german');
You should see the following output:
À voir Diet Freizeit
Note that À voir is at the beginning of the list in a German collation.
Example 5-9 Comparing a Monolingual German Collation to a UCA Collation
Insert the character string shown in Figure 5-2 into test. It is a D with a crossbar followed by ñ.
Perform a monolingual German collation by using the NLSSORT function with the NLS_SORT parameter set to german.
SELECT * FROM test2 ORDER BY NLSSORT(name, 'NLS_SORT=german');
The output from the German collation shows the new character string last in the list of entries because the characters are not recognized in a German collation.
Perform a UCA collation by entering the following statement:
SELECT * FROM test2 ORDER BY NLSSORT(name, 'NLS_SORT=UCA0620_DUCET');
The output shows the new character string after Diet, following the UCA order.
See Also:
-
"NLS_SORT" for more information about setting and changing the
NLS_SORTparameter
Performing Linguistic Comparisons
When performing SQL comparison operations, characters are compared according to their binary values. A character is greater than another if it has a higher binary value. Because the binary sequences rarely match the linguistic sequences for most languages, such comparisons may not be meaningful for a typical user. To achieve a meaningful comparison, you can specify behavior by using the session parameters NLS_COMP and NLS_SORT. The way you set these two parameters determines the rules by which characters are collated and compared.
The NLS_COMP setting determines how NLS_SORT is handled by the SQL operations. There are three valid values for NLS_COMP:
-
BINARYAll SQL collations and comparisons are based on the binary values of the string characters, regardless of the value set to
NLS_SORT. This is the default setting.
-
LINGUISTICAll SQL collation and comparison are based on the linguistic rule specified by
NLS_SORT. For example,NLS_COMP=LINGUISTICandNLS_SORT=BINARY_CImeans the collation sensitive SQL operations will use binary value for collating and comparison but ignore character case.
-
ANSIA limited set of SQL functions honor the
NLS_SORTsetting.ANSIis available for backward compatibility only. In general, you should setNLS_COMPtoLINGUISTICwhen performing linguistic comparison.
Table 5-3 shows how different SQL or PL/SQL operations behave with these different settings.
Table 5-3 Linguistic Comparison Behavior with NLS_COMP Settings
| SQL or PL/SQL Operation | BINARY | LINGUISTIC | ANSI |
|---|---|---|---|
|
Set Operators |
- |
- |
- |
|
|
Binary |
Honors |
Binary |
|
Scalar Functions |
- |
- |
- |
|
|
Binary |
Honors |
Binary |
|
|
Binary |
Honors |
Binary |
|
|
Binary |
Honors |
Binary |
|
|
Binary |
Honors |
Binary |
|
|
Honors |
Honors |
Honors |
|
|
Honors |
Honors |
Honors |
|
|
Honors |
Honors |
Honors |
|
|
Honors |
Honors |
Honors |
|
|
Binary |
Honors |
Binary |
|
|
Honors |
Honors |
Honors |
|
|
Honors |
Honors |
Honors |
|
|
Honors |
Honors |
Honors |
|
|
Honors |
Honors |
Honors |
|
|
Binary |
Honors |
Binary |
|
|
Binary |
Honors |
Binary |
|
|
Binary |
Honors |
Binary |
|
Conditions |
- |
- |
- |
|
|
Binary |
Honors |
Honors |
|
|
Binary |
Honors |
Honors |
|
|
Binary |
Honors |
Honors |
|
|
Binary |
Honors |
Binary |
|
|
Honors |
Honors |
Honors |
|
CASE Expression |
- |
- |
- |
|
|
Binary |
Honors |
Binary |
|
Analytic Function Clauses |
- |
- |
- |
|
|
Honors |
Honors |
Honors |
|
|
Honors |
Honors |
Honors |
|
|
Honors |
Honors |
Honors |
|
Subquery Clauses |
- |
- |
- |
|
|
Binary |
Honors |
Binary |
|
|
Binary |
Honors |
Binary |
|
|
Honors |
Honors |
Honors |
See "NLS_COMP" and "NLS_SORT" for information regarding these parameters.
Collation Keys
When the comparison conditions =, !=, >, <, >=, <=, BETWEEN, NOT BETWEEN, IN, NOT IN, the query clauses ORDER BY or GROUP BY, or the aggregate function COUNT(DISTINCT) are evaluated according to linguistic rules specified by NLS_SORT, the compared argument values are first transformed to binary values called collation keys and then compared byte by byte, like RAW values. If a monolingual collation is applied, collation keys contain major values for characters of the source value concatenated with minor values for those characters. If a multilingual collation is applied, collation keys contain concatenated primary, secondary, and tertiary values.
The collation keys are the same values that are returned by the NLSSORT function. That is, activating the linguistic behavior of these SQL operations is equivalent to including their arguments into calls to the NLSSORT function.
Restricted Precision of Linguistic Comparison
As collation keys are values of the data type RAW and the maximum length of a RAW value depends on the value of the initialization parameter, MAX_STRING_SIZE, the maximum length of a collation key is controlled by the parameter as well.
When MAX_STRING_SIZE is set to STANDARD, the maximum length of a collation key is restricted to 2000 bytes. If a full source string yields a collation key longer than the maximum length, the collation key generated for this string is calculated for a maximum prefix (initial substring) of the value for which the calculated result does not exceed 2000 bytes. For monolingual collation, the prefix is typically 1000 characters. For multilingual collation, the prefix is typically 500 characters. For UCA collations, the prefix is typically 300 characters. The exact length of the prefix may be higher or lower and depends on the particular collation and the particular characters contained in the source string. The implication of this method of collation key generation is that SQL operations using the collation keys to implement the linguistic behavior will return results that may ignore trailing parts of long arguments. For example, two strings starting with the same 1000 characters but differing somewhere after the 1000th character will be grouped together by the GROUP BY clause.
When MAX_STRING_SIZE is set to EXTENDED, the maximum length of a collation key is restricted to 32767 bytes. If a full source string yields a collation key longer than the maximum length, ORA- 12742 will be raised.
Examples: Linguistic Comparison
The following examples illustrate behavior with different NLS_COMP settings.
Example 5-10 Binary Comparison Binary Collation
The following illustrates behavior with a binary setting:
SQL> ALTER SESSION SET NLS_COMP=BINARY; SQL> ALTER SESSION SET NLS_SORT=BINARY; SQL> SELECT ename FROM emp1; ENAME ---------------------- Mc Calla MCAfee McCoye Mccathye McCafeé 5 rows selected SQL> SELECT ename FROM emp1 WHERE ename LIKE 'McC%e'; ENAME ---------------------- McCoye 1 row selected
Example 5-11 Linguistic Comparison Binary Case-Insensitive Collation
The following illustrates behavior with a case-insensitive setting:
SQL> ALTER SESSION SET NLS_COMP=LINGUISTIC; SQL> ALTER SESSION SET NLS_SORT=BINARY_CI; SQL> SELECT ename FROM emp1 WHERE ename LIKE 'McC%e'; ENAME ---------------------- McCoye Mccathye 2 rows selected
Example 5-12 Linguistic Comparison Binary Accent-Insensitive Collation
The following illustrates behavior with an accent-insensitive setting:
SQL> ALTER SESSION SET NLS_COMP=LINGUISTIC; SQL> ALTER SESSION SET NLS_SORT=BINARY_AI; SQL> SELECT ename FROM emp1 WHERE ename LIKE 'McC%e'; ENAME ---------------------- McCoye Mccathye McCafeé 3 rows selected
Example 5-13 Linguistic Comparisons Returning Fewer Rows
Some operations may return fewer rows after applying linguistic rules. For example, with a binary setting, McAfee and Mcafee are different:
SQL> ALTER SESSION SET NLS_COMP=BINARY; SQL> ALTER SESSION SET NLS_SORT=BINARY; SQL> SELECT DISTINCT ename FROM emp2; ENAME ---------------------- McAfee Mcafee McCoy 3 rows selected
However, with a case-insensitive setting, McAfee and Mcafee are the same:
SQL> ALTER SESSION SET NLS_COMP=LINGUISTIC; SQL> ALTER SESSION SET NLS_SORT=BINARY_CI; SQL> SELECT DISTINCT ename FROM emp2; ENAME ---------------------- McAfee McCoy 2 rows selected
In this example, either McAfee or Mcafee could be returned from the DISTINCT operation. There is no guarantee exactly which one will be picked.
Example 5-14 Linguistic Comparisons Using XSPANISH
There are cases where characters are the same using binary comparison but different using linguistic comparison. For example, with a binary setting, the character C in Cindy, Chad, and Clara represents the same letter C:
SQL> ALTER SESSION SET NLS_COMP=BINARY; SQL> ALTER SESSION SET NLS_SORT=BINARY; SQL> SELECT ename FROM emp3 WHERE ename LIKE 'C%'; ENAME ---------------------- Cindy Chad Clara 3 rows selected
In a database session with the linguistic rule set to traditional Spanish, XSPANISH, ch is treated as one character. So the letter c in Chad is different than the letter C in Cindy and Clara:
SQL> ALTER SESSION SET NLS_COMP=LINGUISTIC; SQL> ALTER SESSION SET NLS_SORT=XSPANISH; SQL> SELECT ename FROM emp3 WHERE ename LIKE 'C%'; ENAME ---------------------- Cindy Clara 2 rows selected
And the letter c in combination ch is different than the c standing by itself:
SQL> SELECT REPLACE ('character', 'c', 't') "Changes" FROM DUAL;
Changes
---------------------
charatter
Example 5-15 Linguistic Comparisons Using UCA0620_TSPANISH
The character ch behaves the same in the traditional Spanish ordering of the UCA collations as that in XSPANISH:
SQL> ALTER SESSION SET NLS_COMP = LINGUISTIC;
SQL> ALTER SESSION SET NLS_SORT = UCA0620_TSPANISH;
SQL> SELECT ename FROM emp3 WHERE ename LIKE 'C%';
ENAME
--------------
Cindy
Clara
SQL> SELECT REPLACE ('character', 'c', 't') "Changes" FROM DUAL;
Changes
-----------
charatter
Using Linguistic Indexes
Linguistic collation is language-specific and requires more data processing than binary collation. Using a binary collation for ASCII is accurate and fast because the binary codes for ASCII characters reflect their linguistic order. When data in multiple languages is stored in the database, you may want applications to collate the data returned from a SELECT...ORDER BY statement according to different collation sequences depending on the language. You can accomplish this without sacrificing performance by using linguistic indexes. Although a linguistic index for a column slows down inserts and updates, it greatly improves the performance of linguistic collation with the ORDER BY clause and the WHERE clause.
You can create a function-based index that uses languages other than English. The index does not change the linguistic collation order determined by NLS_SORT. The linguistic index simply improves the performance.
The following statement creates an index based on a German collation:
CREATE TABLE my_table(name VARCHAR(20) NOT NULL); CREATE INDEX nls_index ON my_table (NLSSORT(name, 'NLS_SORT = German'));
The NOT NULL in the CREATE TABLE statement ensures that the index is used.
After the index has been created, enter a SELECT statement similar to the following example:
SELECT * FROM my_table ORDER BY name WHERE name LIKE 'Hein%';
It returns the result much faster than the same SELECT statement without a linguistic index.
The rest of this section contains the following topics:
-
Supported SQL Operations and Functions for Linguistic Indexes
-
Requirements for Using Linguistic Indexes
See Also:
-
Oracle Database Administrator's Guide for more information about function-based indexes
-
Supported SQL Operations and Functions for Linguistic Indexes
Linguistic index support is available for the following collation-sensitive SQL operations and SQL functions:
-
Comparison conditions
=,!=,>,<,>=,<= -
Range conditions
BETWEEN|NOTBETWEEN -
IN|NOTIN -
ORDERBY -
GROUPBY -
LIKE(LIKE,LIKE2,LIKE4,LIKEC) -
DISTINCT -
UNIQUE -
UNION -
INTERSECT -
MINUS
The SQL functions in the following list cannot utilize linguistic index:
-
INSTR(INSTR,INSTRB,INSTR2,INSTR4,INSTRC) -
MAX -
MIN -
REPLACE -
TRIM -
LTRIM -
RTRIM -
TRANSLATE
Linguistic Indexes for Multiple Languages
There are four ways to build linguistic indexes for data in multiple languages:
-
Build a linguistic index for each language that the application supports. This approach offers simplicity but requires more disk space. For each index, the rows in the language other than the one on which the index is built are collated together at the end of the sequence. The following example builds linguistic indexes for French and German.
CREATE INDEX french_index ON employees (NLSSORT(employee_id, 'NLS_SORT=FRENCH')); CREATE INDEX german_index ON employees (NLSSORT(employee_id, 'NLS_SORT=GERMAN'));
Oracle Database chooses the index based on the
NLS_SORTsession parameter or the arguments of theNLSSORTfunction specified in theORDERBYclause. For example, if theNLS_SORTsession parameter is set toFRENCH, then Oracle Database usesfrench_index. When it is set toGERMAN, Oracle Database usesgerman_index. -
Build a single linguistic index for all languages. This requires a language column (
LANG_COLin "Example: Setting Up a French Linguistic Index") to be used as a parameter of theNLSSORTfunction. The language column containsNLS_LANGUAGEvalues for the data in the column on which the index is built. The following example builds a single linguistic index for multiple languages. With this index, the rows with the same values forNLS_LANGUAGEare sorted together.CREATE INDEX i ON t (NLSSORT(col, 'NLS_SORT=' || LANG_COL));
Queries choose an index based on the argument of the
NLSSORTfunction specified in theORDER BYclause. -
Build a single linguistic index for all languages using one of the multilingual collations such as
GENERIC_MorFRENCH_M. These indexes sort characters according to the rules defined in ISO 14651. For example:CREATE INDEX i ON t (NLSSORT(col, 'NLS_SORT=GENERIC_M'));
See Also:
"Multilingual Collation" for more information -
Build a single linguistic index for all languages using one of the UCA collations such as
UCA0620_DUCETorUCA0620_CFRENCH. These indexes sort characters in the order conforming to ISO 14654 and UCA 6.2.0. For example:CREATE INDEX i ON t (NLSSORT(col, 'NLS_SORT=UCA0620_DUCET'));
See Also:
"UCA Collation" for more information
Requirements for Using Linguistic Indexes
The following are requirements for using linguistic indexes:
This section also includes:
Set NLS_SORT Appropriately
The NLS_SORT parameter should indicate the linguistic definition you want to use for the linguistic collation. If you want a French linguistic collation order, then NLS_SORT should be set to FRENCH. If you want a German linguistic collation order, then NLS_SORT should be set to GERMAN.
There are several ways to set NLS_SORT. You should set NLS_SORT as a client environment variable so that you can use the same SQL statements for all languages. Different linguistic indexes can be used when NLS_SORT is set in the client environment.
See Also:
"NLS_SORT"Specify NOT NULL in a WHERE Clause If the Column Was Not Declared NOT NULL
When you want to use the ORDER BY column_name clause with a column that has a linguistic index, include a WHERE clause like the following example:
WHERE NLSSORT(column_name) IS NOT NULL
This WHERE clause is not necessary if the column has already been defined as a NOT NULL column in the schema.
Use a Tablespace with an Adequate Block Size
A collation key created from a character value is usually a few times longer than this value. The actual length expansion depends on the particular collation in use and the content of the source value, with the UCA-based collations expanding the most.
When creating a linguistic index, Oracle Database first calculates the estimated maximum size of the index key by summing up the estimated maximum sizes of the collation keys (NLSSORT results) for each of the character columns forming the index key. In this calculation, the maximum size of a collation key for a character column with the maximum byte length n is estimated to be n*21+5 for UCA-based collations and n*8+10 for other collations.
The large expansion ratios can yield large maximum index key sizes, especially for composite (multicolumn) keys. At the same time, the maximum key size of an index cannot exceed around 70% of the block size of the tablespace containing the index. If it does, an ORA-1450 error is reported. To avoid this error, you should store the linguistic index in a tablespace with an adequate block size, which may be larger than the default block size of your database. A suitable tablespace can be created with the CREATE TABLESPACE statement, provided the initialization parameter DB_nK_CACHE_SIZE corresponding to the required block size n has been set appropriately.
See Also:
Example: Setting Up a French Linguistic Index
The following example shows how to set up a French linguistic index. You may want to set NLS_SORT as a client environment variable instead of using the ALTER SESSION statement.
ALTER SESSION SET NLS_SORT='FRENCH'; CREATE INDEX test_idx ON test4(NLSSORT(name, 'NLS_SORT=FRENCH')); SELECT * FROM test4 ORDER BY col; ALTER SESSION SET NLS_COMP=LINGUISTIC; SELECT * FROM test4 WHERE name > 'Henri';
Note:
The SQL functionsMAX( ) and MIN( ) cannot use linguistic indexes when NLS_COMP is set to LINGUISTIC.Searching Linguistic Strings
Searching and collation are related tasks. Organizing data and processing it in a linguistically meaningful order is necessary for proper business processing. Searching and matching data in a linguistically meaningful way depends on what collation order is applied. For example, searching for all strings greater than c and less than f produces different results depending on the value of NLS_SORT. In an ASCII binary collation, the search finds any strings that start with d or e but excludes entries that begin with upper case D or E or accented e with a diacritic, such as ê. Applying an accent-insensitive binary collation returns all strings that start with d, D, and accented e, such as Ê or ê. Applying the same search with NLS_SORT set to XSPANISH also returns strings that start with ch, because ch is treated as a composite character that collates between c and d in traditional Spanish. This chapter discusses the kinds of collation that Oracle Database offers and how they affect string searches by SQL and SQL regular expressions.
SQL Regular Expressions in a Multilingual Environment
Regular expressions provide a powerful method of identifying patterns of strings within a body of text. Usage ranges from a simple search for a string such as San Francisco to the more complex task of extracting all URLs to finding all words whose every second character is a vowel. SQL and PL/SQL support regular expressions in Oracle Database.
Traditional regular expression engines were designed to address only English text. However, regular expression implementations can encompass a wide variety of languages with characteristics that are very different from western European text. The implementation of regular expressions in Oracle Database is based on the Unicode Regular Expression Guidelines. The REGEXP SQL functions work with all character sets that are supported as database character sets and national character sets. Moreover, Oracle Database enhances the matching capabilities of the POSIX regular expression constructs to handle the unique linguistic requirements of matching multilingual data.
Oracle Database enhancements of the linguistic-sensitive operators are described in the following sections:
-
See Also:
-
Oracle Database Development Guide for more information about regular expression syntax
-
Oracle Database SQL Language Reference for more information about
REGEXSQL functions
-
Character Range '[x-y]' in Regular Expressions
According to the POSIX standard, a range in a regular expression includes all collation elements between the start point and the end point of the range in the linguistic definition of the current locale. Therefore, ranges in regular expressions are meant to be linguistic ranges, not byte value ranges, because byte value ranges depend on the platform, and the end user should not be expected to know the ordering of the byte values of the characters. The semantics of the range expression must be independent of the character set. This implies that a range such as [a-d] may include all the letters between a and d plus all of those letters with diacritics, plus any special case collation element such as ch in Traditional Spanish that is sorted as one character.
Oracle Database interprets range expressions as specified by the NLS_SORT parameter to determine the collation elements covered by a given range. For example:
Expression: [a-d]e NLS_SORT: BINARY Does not match: cheremoya NLS_SORT: XSPANISH Matches: >>che<<remoya
Collation Element Delimiter '[. .]' in Regular Expressions
This construct is introduced by the POSIX standard to separate collating elements. A collating element is a unit of collation and is equal to one character in most cases. However, the collation sequence in some languages may define two or more characters as a collating element. The historical regular expression syntax does not allow the user to define ranges involving multicharacter collation elements. For example, there was no way to define a range from a to ch because ch was interpreted as two separate characters.
By using the collating element delimiter [. .], you can separate a multicharacter collation element from other elements. For example, the range from a to ch can be written as [a-[.ch.]]. It can also be used to separate single-character collating elements. If you use [. .] to enclose a multicharacter sequence that is not a defined collating element, then it is considered as a semantic error in the regular expression. For example, [.ab.] is considered invalid if ab is not a defined multicharacter collating element.
Character Class '[: :]' in Regular Expressions
In English regular expressions, the range expression can be used to indicate a character class. For example, [a-z] can be used to indicate any lowercase letter. However, in non-English regular expressions, this approach is not accurate unless a is the first lowercase letter and z is the last lowercase letter in the collation sequence of the language.
The POSIX standard introduces a new syntactical element to enable specifying explicit character classes in a portable way. The [: :] syntax denotes the set of characters belonging to a certain character class. The character class definition is based on the character set classification data.
Equivalence Class '[= =]' in Regular Expressions
Oracle Database also supports equivalence classes through the [= =] syntax as recommended by the POSIX standard. A base letter and all of the accented versions of the base constitute an equivalence class. For example, the equivalence class [=a=] matches ä as well as â. The current implementation does not support matching of Unicode composed and decomposed forms for performance reasons. For example, ä (a umlaut) does not match 'a followed by umlaut'.
Examples: Regular Expressions
The following examples show regular expression matches.
Example 5-16 Case-Insensitive Match Using the NLS_SORT Value
Case sensitivity in an Oracle Database regular expression match is determined at two levels: the NLS_SORT initialization parameter and the run-time match option. The REGEXP functions inherit the case-sensitivity behavior from the value of NLS_SORT by default. The value can also be explicitly overridden by the run-time match option 'c' (case sensitive) or 'i' (case insensitive).
Expression: catalog(ue)? NLS_SORT: GENERIC_M_CI Matches:
>>Catalog<< >>catalogue<< >>CATALOG<<
Oracle Database SQL syntax:
SQL> ALTER SESSION SET NLS_SORT='GENERIC_M_CI'; SQL> SELECT col FROM test WHERE REGEXP_LIKE(col,'catalog(ue)?');
Example 5-17 Case Insensitivity Overridden by the Run-time Match Option
Expression: catalog(ue)? NLS_SORT: GENERIC_M_CI Match option: 'c' Matches:
>>catalogue<<
Does not match:
Catalog CATALOG
Oracle Database SQL syntax:
SQL> ALTER SESSION SET NLS_SORT='GENERIC_M_CI'; SQL> SELECT col FROM test WHERE REGEXP_LIKE(col,'catalog(ue)?','c');
Example 5-18 Matching with the Collation Element Operator [..]
Expression: [^-a-[.ch.]]+ /*with NLS_SORT set to xspanish*/ Matches:
>>driver<<
Does not match:
cab
Oracle Database SQL syntax:
SQL> SELECT col FROM test WHERE REGEXP_LIKE(col,'[^-a-[.ch.]]+');
Example 5-19 Matching with the Character Class Operator [::]
This expression looks for 6-character strings with lowercase characters. Note that accented characters are matched as lowercase characters.
Expression: [[:lower:]]{6}
Database character set: WE8ISO8859P1
Matches:
>>maître<< >>mòbile<< >>pájaro<< >>zurück<<
Oracle Database SQL syntax:
SQL> SELECT col FROM test WHERE REGEXP_LIKE(col,'[[:lower:]]{6}');
Example 5-20 Matching with the Base Letter Operator [==]
Expression: r[[=e=]]sum[[=e=]] Matches:
>>resume<< >>résumé<< >>résume<< >>resumé<<
Oracle Database SQL syntax:
SQL> SELECT col FROM test WHERE REGEXP_LIKE(col,'r[[=e=]]sum[[=e=]]');
See Also:
-
Oracle Database Development Guide for more information about regular expression syntax
-
Oracle Database SQL Language Reference for more information about
REGEXSQL functions