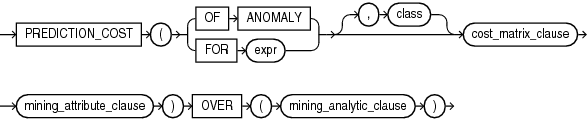
PREDICTION_COST
Description of the illustration prediction_cost.gif
Description of the illustration prediction_cost_analytic.gif
Description of the illustration cost_matrix_clause.gif
Description of the illustration mining_attribute_clause.gif
Description of the illustration mining_analytic_clause.gif
See Also:
"Analytic Functions" for information on the syntax, semantics, and restrictions ofmining_analytic_clausePREDICTION_COST returns a cost for each row in the selection. The cost refers to the lowest cost class or to the specified class. The cost is returned as BINARY_DOUBLE.
PREDICTION_COST can perform classification or anomaly detection. For classification, the returned cost refers to a predicted target class. For anomaly detection, the returned cost refers to a classification of 1 (for typical rows) or 0 (for anomalous rows).
You can use PREDICTION_COST in conjunction with the PREDICTION function to obtain the prediction and the cost of the prediction.
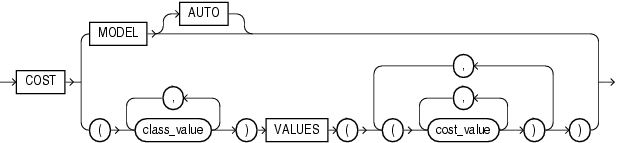
Costs are a biasing factor for minimizing the most harmful kinds of misclassifications. For example, false positives might be considered more costly than false negatives. Costs are specified in a cost matrix that can be associated with the model or defined inline in a VALUES clause. All classification algorithms can use costs to influence scoring.
Decision Tree is the only algorithm that can use costs to influence the model build. The cost matrix used to build a Decision Tree model is also the default scoring cost matrix for the model.
The following cost matrix table specifies that the misclassification of 1 is five times more costly than the misclassification of 0.
ACTUAL_TARGET_VALUE PREDICTED_TARGET_VALUE COST
------------------- ---------------------- ----------
0 0 0
0 1 1
1 0 5
1 1 0
In cost_matrix_clause:
-
COSTMODELindicates that scoring should be performed by taking into account the scoring cost matrix associated with the model. If the cost matrix does not exist, then the function returns an error. -
COSTMODELAUTOindicates that the existence of a cost matrix is unknown. If a cost matrix exists, then the function uses it to return the lowest cost prediction. Otherwise the function returns the highest probability prediction. -
The
VALUESclause specifies an inline cost matrix forclass_value. For example, you could specify that the misclassification of1is five times more costly than the misclassification of0as follows:PREDICTION (nb_model COST (0,1) VALUES ((0, 1),(1, 5)) USING *)
If a model that has a scoring cost matrix is invoked with an inline cost matrix, then the inline costs are used.
See Also:
Oracle Data Mining User's Guide for more information about cost-sensitive prediction.
PREDICTION_COST can score the data in one of two ways: It can apply a mining model object to the data, or it can dynamically mine the data by executing an analytic clause that builds and applies one or more transient mining models. Choose Syntax or Analytic Syntax:
-
Syntax — Use the first syntax to score the data with a pre-defined model. Supply the name of a model that performs classification or anomaly detection.
-
Analytic Syntax — Use the analytic syntax to score the data without a pre-defined model. The analytic syntax uses
mining_analytic_clause, which specifies if the data should be partitioned for multiple model builds. Themining_analytic_clausesupports aquery_partition_clauseand anorder_by_clause. (See "analytic_clause::=".)-
For classification, specify
FORexpr, whereexpris an expression that identifies a target column that has a character data type. -
For anomaly detection, specify the keywords
OF ANOMALY.
-
mining_attribute_clause identifies the column attributes to use as predictors for scoring. When the function is invoked with the analytic syntax, these predictors are also used for building the transient models. The mining_attribute_clause behaves as described for the PREDICTION function. (See "mining_attribute_clause::=".)
See Also:
-
Oracle Data Mining User's Guide for information about scoring.
-
Oracle Data Mining Concepts for information about classification with costs
About the Example:
The following example is excerpted from the Data Mining sample programs. For more information about the sample programs, see Appendix A in Oracle Data Mining User's Guide.This example predicts the ten customers in Italy who would respond to the least expensive sales campaign (offering an affinity card).
SELECT cust_id
FROM (SELECT cust_id,rank()
OVER (ORDER BY PREDICTION_COST(DT_SH_Clas_sample, 1 COST MODEL USING *)
ASC, cust_id) rnk
FROM mining_data_apply_v
WHERE country_name = 'Italy')
WHERE rnk <= 10
ORDER BY rnk;
CUST_ID
----------
100081
100179
100185
100324
100344
100554
100662
100733
101250
101306