1 Overview of TimesTen Replication
The following sections provide an overview of TimesTen replication:
What is replication?
Replication is the process of maintaining copies of data in multiple databases. The purpose of replication is to make data highly available to applications with minimal performance impact. In addition to providing recovery from failures, replication schemes can also distribute application workloads across multiple databases for maximum performance and facilitate online upgrades and maintenance.
Replication is the process of copying data from a master database to a subscriber database. Replication is controlled by replication agents for each database. The replication agent on the master database reads the records from the transaction log for the master database. It forwards changes to replicated elements to the replication agent on the subscriber database. The replication agent on the subscriber database then applies the updates to its database. If the subscriber replication agent is not running when the updates are forwarded by the master, the master retains the updates in its transaction log until they can be applied at the subscriber database.
TimesTen recommends the active standby pair configuration for highest availability. In an active standby pair replication scheme, the data is copied from the active database to the standby database before being copied to read-only subscribers.
An entity that is replicated with all of its contents between databases is called a replication element. TimesTen supports databases, cache groups, tables and sequences as replication elements. TimesTen also replicates XLA bookmarks. An active standby pair is the only supported replication scheme for databases with cache groups.
In addition, when you execute certain DDL statements in an active standby pair, some statements are replicated against the other nodes in the replication scheme. For more details, see "Making DDL changes in an active standby pair".
Requirements for replication compatibility
TimesTen replication is supported only between identical platforms and bit-levels. Although you can replicate between databases that reside on the same host, replication is generally used for copying updates into a database that resides on another host. This helps prevent data loss from host failure.
The databases must have DSNs with identical DatabaseCharacterSet and TypeMode database attributes.
Replication agents
Replication between databases is controlled by a replication agent. Each database is identified by:
-
A database name derived from the file system's path name for the database
-
A host name
The replication agent on the master database reads the records from the transaction log and forwards any detected changes to replicated elements to the replication agent on the subscriber database. The replication agent on the subscriber database then applies the updates to its database. If the subscriber agent is not running when the updates are forwarded by the master, the master retains the updates in the transaction log until they can be transmitted.
The replication agents communicate through TCP/IP stream sockets. The replication agents obtain the TCP/IP address, host name, and other configuration information from the replication tables described in Oracle TimesTen In-Memory Database System Tables and Views Reference.
Copying updates between databases
By default, updates are copied between databases asynchronously. While asynchronous replication provides the best performance, it does not provide the application with confirmation that the replicated updates were committed on subscriber databases. For applications that need higher levels of confidence that the replicated data is consistent between the master and subscriber databases, you can enable either return receipt or return twosafe service.
-
The return receipt service loosely synchronizes the application with the replication mechanism by blocking the application until replication confirms that the update has been received by the subscriber.
-
The return twosafe service provides a fully synchronous option by blocking the application until replication confirms that the update has been both received and committed on the subscriber.
Return receipt replication impacts performance less than return twosafe, but at the expense of less synchronization. The operational details for asynchronous, return receipt, and return twosafe replication are discussed in these sections:
Default replication
When using default TimesTen replication, an application updates a master database and continues working without waiting for the updates to be received and applied by the subscribers. The master and subscriber databases have internal mechanisms to confirm that the updates have been successfully received and committed by the subscriber. These mechanisms ensure that updates are applied at a subscriber only once, but they are completely independent of the application.
Default TimesTen replication provides maximum performance, but the application is completely decoupled from the receipt process of the replicated elements on the subscriber.
Figure 1-1 Basic asynchronous replication cycle
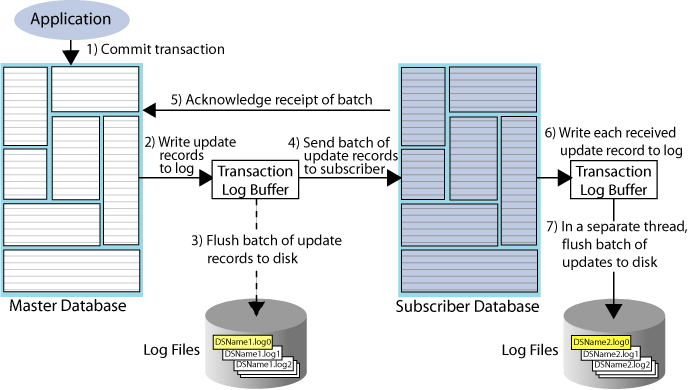
Description of "Figure 1-1 Basic asynchronous replication cycle"
The default TimesTen replication cycle is:
-
The application commits a local transaction to the master database and is free to continue with other transactions.
-
During the commit, the TimesTen daemon writes the transaction update records to the transaction log buffer.
-
The replication agent on the master database directs the daemon to flush a batch of update records for the committed transactions from the log buffer to a transaction log file. This step ensures that, if the master fails and you need to recover the database from the checkpoint and transaction log files, the recovered master contains all the data it replicated to the subscriber.
-
The master replication agent forwards the batch of transaction update records to the subscriber replication agent, which applies them to the subscriber database. Update records are flushed to disk and forwarded to the subscriber in batches of 256K or less, depending on the master database's transaction load. A batch is created when there is no more log data in the transaction log buffer or when the current batch is roughly 256K bytes.
-
The subscriber replication agent sends an acknowledgement back to the master replication agent that the batch of update records was received. The acknowledgement includes information on which batch of records the subscriber last flushed to disk. The master replication agent is now free to purge from the transaction log the update records that have been received, applied, and flushed to disk by all subscribers and to forward another batch of update records, while the subscriber replication agent asynchronously continues on to Step 6.
-
The replication agent at the subscriber updates the database and directs the daemon to write the transaction update records to the transaction log buffer.
-
The replication agent at the subscriber database uses a separate thread to direct the daemon to flush the update records to a transaction log file.
Return receipt replication
The return receipt service provides a level of synchronization between the master and a subscriber database by blocking the application after commit on the master until the updates of the committed transaction have been received by the subscriber.
An application requesting return receipt updates the master database in the same manner as in the basic asynchronous case. However, when the application commits a transaction that updates a replicated element, the master database blocks the application until it receives confirmation that the updates for the completed transaction have been received by the subscriber.
Return receipt replication trades some performance in order to provide applications with the ability to ensure higher levels of data integrity and consistency between the master and subscriber databases. In the event of a master failure, the application has a high degree of confidence that a transaction committed at the master persists in the subscribing database.
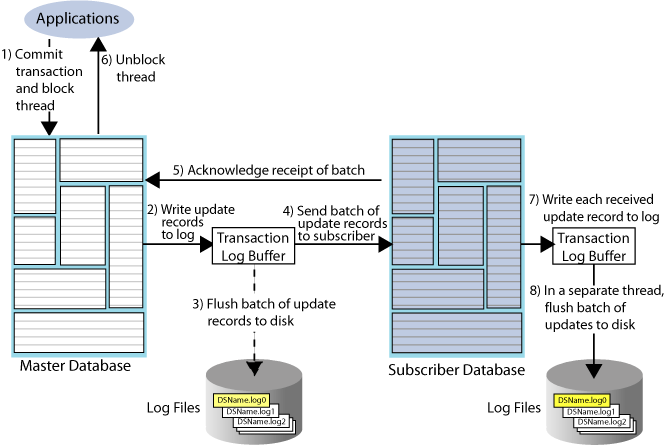
Figure 1-2 shows that the return receipt replication cycle is the same as shown for the basic asynchronous cycle in Figure 1-1, only the master replication agent blocks the application thread after it commits a transaction (Step 1) and retains control of the thread until the subscriber acknowledges receipt of the update batch (Step 5). Upon receiving the return receipt acknowledgement from the subscriber, the master replication agent returns control of the thread to the application (Step 6), freeing it to continue executing transactions.
If the subscriber is unable to acknowledge receipt of the transaction within a configurable timeout period (default is 10 seconds), the master replication agent returns a warning stating that it did not receive acknowledgement of the update from the subscriber and returns control of the thread to the application. The application is then free to commit another transaction to the master, which continues replication to the subscriber as before.
Return receipt transactions may time out for many reasons. The most likely causes for timeout are the network, a failed replication agent, or the master replication agent may be so far behind with respect to the transaction load that it cannot replicate the return receipt transaction before its timeout expires. For information on how to manage return-receipt timeouts, see "Managing return service timeout errors and replication state changes".
See "RETURN RECEIPT" for information on how to configure replication for return receipt.
Return twosafe replication
The return twosafe service provides fully synchronous replication between the master and subscriber. Unlike the previously described replication modes, where transactions are transmitted to the subscriber after being committed on the master, transactions in twosafe mode are first committed on the subscriber before they are committed on the master.
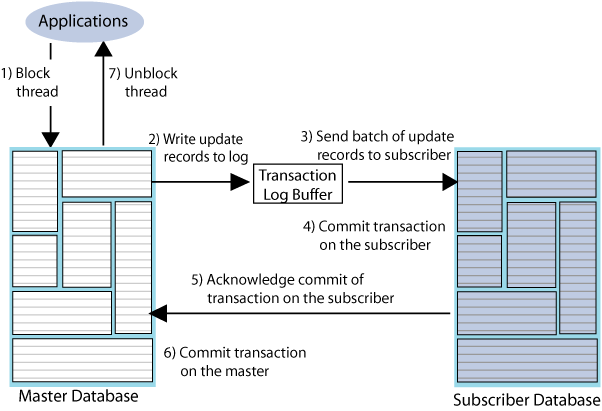
The following describes the replication behavior between a master and subscriber configured for return twosafe replication:
-
The application commits the transaction on the master database.
-
The master replication agent writes the transaction records to the log and inserts a special precommit log record before the commit record. This precommit record acts as a place holder in the log until the master replication receives an acknowledgement that indicates the status of the commit on the subscriber.
Note:
Transmission of return twosafe transactions is nondurable, so the master replication agent does not flush the log records to disk before sending them to the subscriber, as it does by default when replication is configured for asynchronous or return receipt replication. -
The master replication agent transmits the batch of update records to the subscriber.
-
The subscriber replication agent commits the transaction on the subscriber database.
-
The subscriber replication agent returns an acknowledgement back to the master replication agent with notification of whether the transaction was committed on the subscriber and whether the commit was successful.
-
If the commit on the subscriber was successful, the master replication agent commits the transaction on the master database.
-
The master replication agent returns control to the application.
If the subscriber is unable to acknowledge commit of the transaction within a configurable timeout period (default is 10 seconds) or if the acknowledgement from the subscriber indicates the commit was unsuccessful, the replication agent returns control to the application without committing the transaction on the master database. The application can then to decide whether to unconditionally commit or retry the commit. You can optionally configure your replication scheme to direct the master replication agent to commit all transactions that time out.
See "RETURN TWOSAFE" for information on how to configure replication for return twosafe.
Types of replication schemes
You create a replication scheme to define a specific configuration of master and subscriber databases. This section describes the possible relationships you can define between master and subscriber databases when creating a replication scheme.
When defining a relationship between a master and subscriber, consider these replication schemes:
Active standby pair with read-only subscribers
Figure 1-4 shows an active standby pair replication scheme with an active master, a standby master, and four read-only subscriber databases.
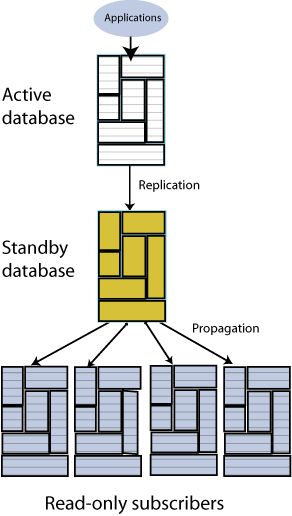
The active standby pair can replicate a whole database or select elements like tables and cache groups.
In an active standby pair, two databases are defined as masters. One is an active master, and the other is a standby master. The application updates the active master directly. Applications cannot update the standby master. It receives the updates from the active master and propagates the changes to as many as 127 read-only subscriber databases. This arrangement ensures that the standby master is always ahead of the subscriber databases and enables rapid failover to the standby master if the active master fails.
Only one of the master databases can function as an active master at a specific time. You can manage failover and recovery of an active standby pair with Oracle Clusterware. See Chapter 8, "Using Oracle Clusterware to Manage Active Standby Pairs". You can also manage failover and recovery manually. See Chapter 5, "Administering an Active Standby Pair without Cache Groups" or Chapter 6, "Administering an Active Standby Pair with Cache Groups."
If the standby master fails, the active master can replicate changes directly to the read-only subscribers. After the standby database has been recovered, it contacts the active master to receive any updates that have been sent to the subscribers while the standby master was down or was recovering. When the active master and the standby master have been synchronized, then the standby master resumes propagating changes to the subscribers.
For details about setting up an active standby pair, see "Setting up an active standby pair with no cache groups", "Setting up an active standby pair with a read-only cache group", or "Setting up an active standby pair with an AWT cache group."
Classic replication
Classic replication schemes enable you to design relationships between masters and subscribers. The following sections describe classic replication schemes:
Full database replication or selective replication
Figure 1-5 illustrates a full replication scheme in which the entire master database is replicated to the subscriber.
Figure 1-5 Replicating the entire master database
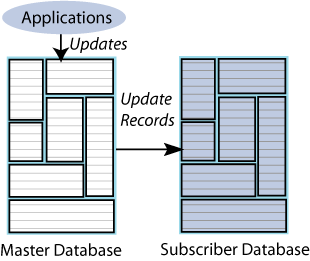
Description of "Figure 1-5 Replicating the entire master database"
You can also configure your master and subscriber databases to selectively replicate some elements in a master database to subscribers. Figure 1-6 shows examples of selective replication. The left side of the figure shows a master database that replicates the same selected elements to multiple subscribers, while the right side shows a master that replicates different elements to each subscriber.
Figure 1-6 Replicating selected elements to multiple subscribers
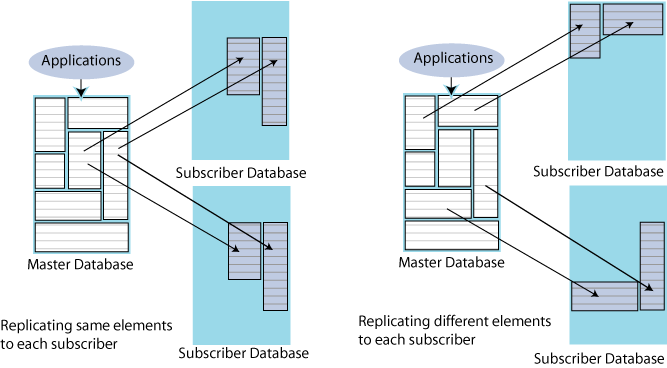
Description of "Figure 1-6 Replicating selected elements to multiple subscribers"
Unidirectional or bidirectional replication
Unidirectional replication is where a master database sends updates to one or more subscriber databases. Bidirectional replication is where there are two databases that operate bidirectionally, where each database is both a master and a subscriber.
These are basic ways to use bidirectional replication:
Split workload configuration
In a split workload configuration, each database serves as a master for some elements and a subscriber for others.
Consider the example shown in Figure 1-7, where the accounts for Chicago are processed on database A while the accounts for New York are processed on database B.
Figure 1-7 Split workload bidirectional replication
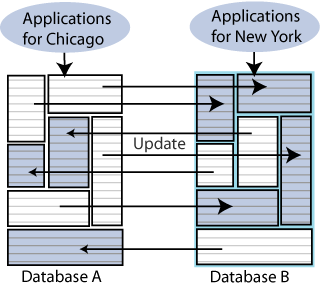
Description of "Figure 1-7 Split workload bidirectional replication"
Distributed workload
In a distributed workload replication scheme, user access is distributed across duplicate application/database combinations that replicate any update on any element to each other. In the event of a failure, the affected users can be quickly shifted to any application/database combination.The distributed workload configuration is shown in Figure 1-8. Users access duplicate applications on each database, which serves as both master and subscriber for the other database.
Figure 1-8 Distributed workload configuration
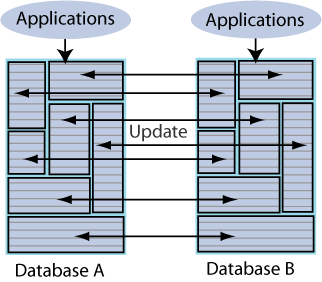
Description of "Figure 1-8 Distributed workload configuration"
When databases are replicated in a distributed workload configuration, it is possible for separate users to concurrently update the same rows and replicate the updates to one another. Your application should ensure that such conflicts cannot occur, that they be acceptable if they do occur, or that they can be successfully resolved using the conflict resolution mechanism described in Chapter 13, "Resolving Replication Conflicts".
Note:
Do not use a distributed workload configuration with the return twosafe return service.Direct replication or propagation
You can define a subscriber to serve as a propagator that receives replicated updates from a master and passes them on to subscribers of its own.
Propagators are useful for optimizing replication performance over lower-bandwidth network connections, such as those between servers in an intranet. For example, consider the direct replication configuration illustrated in Figure 1-9, where a master directly replicates to four subscribers over an intranet connection. Replicating to each subscriber over a network connection in this manner is an inefficient use of network bandwidth.
Figure 1-9 Master replicating directly to multiple subscribers over a network
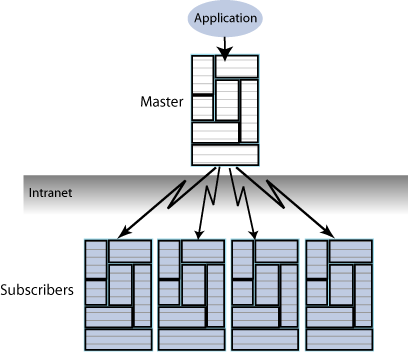
Description of "Figure 1-9 Master replicating directly to multiple subscribers over a network"
For optimum performance, consider the configuration shown in Figure 1-10, where the master replicates to a single propagator over the network connection. The propagator in turn forwards the updates to each subscriber on its local area network.
Figure 1-10 Master replicating to a single propagator over a network
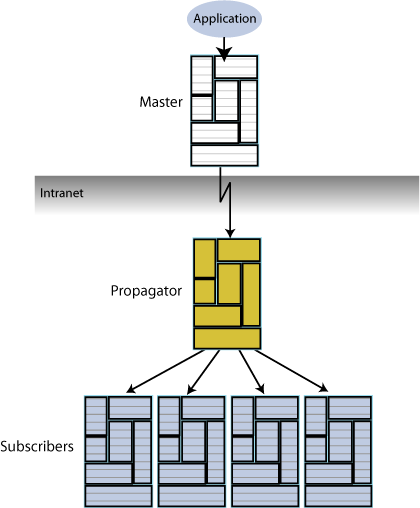
Description of "Figure 1-10 Master replicating to a single propagator over a network"
Propagators are also useful for distributing replication loads in configurations that involve a master database that must replicate to a large number of subscribers. For example, it is more efficient for the master to replicate to three propagators, rather than directly to the 12 subscribers as shown in Figure 1-11.
Figure 1-11 Using propagators to replicate to many subscribers
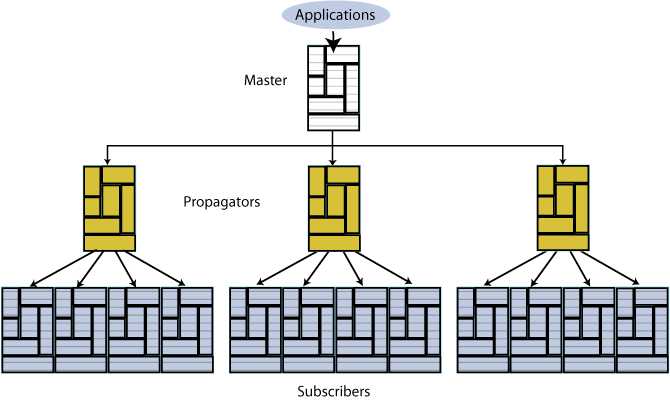
Description of "Figure 1-11 Using propagators to replicate to many subscribers"
Note:
Each propagator is one-hop, which means that you can forward an update only once. You cannot have a hierarchy of propagators where propagators forward updates to other propagators.Cache groups and replication
As described in Oracle TimesTen Application-Tier Database Cache User's Guide, a cache group is a group of tables stored in a central Oracle database that are cached in a local TimesTen Application-Tier Database Cache (TimesTen Cache). This section describes how cache groups can be replicated between TimesTen databases. You can achieve high availability by using an active standby pair to replicate asynchronous writethrough cache groups or read-only cache groups.
This section describes the following ways to replicate cache groups:
See Chapter 6, "Administering an Active Standby Pair with Cache Groups" for details about configuring replication of cache groups.
Replicating an AWT cache group
An asynchronous writethrough (AWT) cache group can be configured as part of an active standby pair with optional read-only subscribers to ensure high availability and to distribute the application workload. Figure 1-12 shows this configuration.
Figure 1-12 AWT cache group replicated by an active standby pair
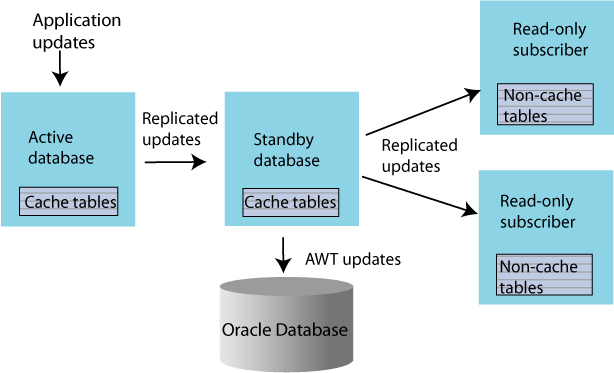
Description of "Figure 1-12 AWT cache group replicated by an active standby pair"
Application updates are made to the active database, the updates are replicated to the standby database, and then the updates are asynchronously written to the Oracle database by the standby. At the same time, the updates are also replicated from the standby to the read-only subscribers, which may be used to distribute the load from reading applications. The tables on the read-only subscribers are not in cache groups.
When there is no standby database, the active database both accepts application updates and writes the updates asynchronously to the Oracle database and the read-only subscribers. This situation can occur when the standby has not yet been created, or when the active fails and the standby becomes the new active. TimesTen reconfigures the AWT cache group when the standby becomes the new active.
If a failure occurs on the node where the active database resides, the standby node becomes the new active node. TimesTen automatically reconfigures the AWT cache group so that it can be updated directly by the application and continue to propagate the updates to the Oracle database asynchronously.
Replicating an AWT cache group with a subscriber propagating to an Oracle database
You can recover from a complete failure of a site by creating a special disaster recovery read-only subscriber on a remote site as part of the active standby pair replication configuration. Figure 1-13 shows this configuration.
Figure 1-13 Disaster recovery configuration with active standby pair
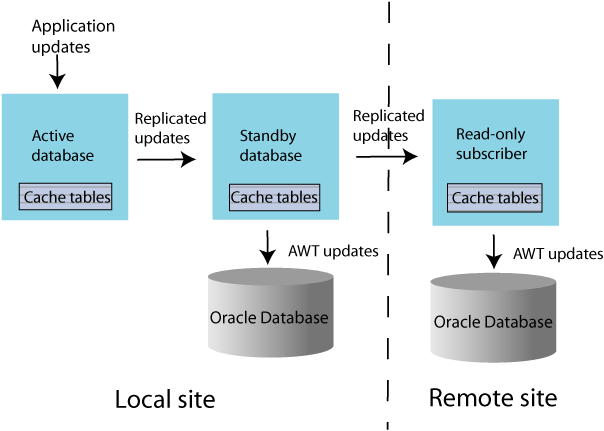
Description of "Figure 1-13 Disaster recovery configuration with active standby pair"
The standby database sends updates to cache group tables on the read-only subscriber. This special subscriber is located at a remote disaster recovery site and can propagate updates to a second Oracle database, also located at the disaster recovery site. You can set up more than one disaster recovery site with read-only subscribers and Oracle databases. See "Using a disaster recovery subscriber in an active standby pair".
Replicating a read-only cache group
A read-only cache group enforces caching behavior in which committed updates on the Oracle database tables are automatically refreshed to the corresponding TimesTen cache tables. Figure 1-14 shows a read-only cache group replicated by an active standby pair.
Figure 1-14 Read-only cache group replicated by an active standby pair
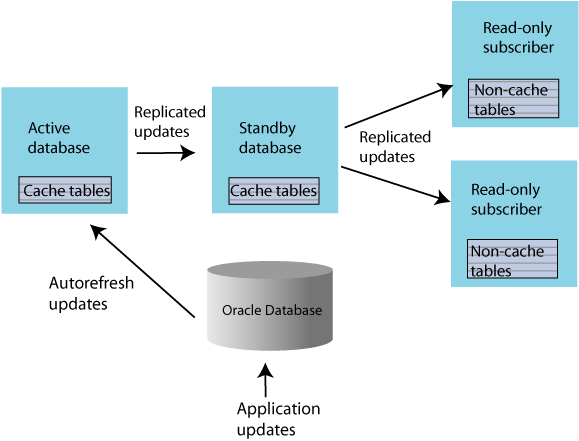
Description of "Figure 1-14 Read-only cache group replicated by an active standby pair"
When the read-only cache group is replicated by an active standby pair, the cache group on the active database is autorefreshed from the Oracle database and replicates the updates to the standby, where AUTOREFRESH is also configured on the cache group but is in the PAUSED state. In the event of a failure of the active, TimesTen automatically reconfigures the standby to be autorefreshed when it takes over for the failed master database by setting the AUTOREFRESH STATE to ON.TimesTen also tracks whether updates that have been autorefreshed from the Oracle database to the active database have been replicated to the standby. This ensures that the autorefresh process picks up from the correct point after the active fails, and no autorefreshed updates are lost.This configuration may also include read-only subscriber databases.This enables the read workload to be distributed across many databases. The cache groups on the standby database replicate to regular (non-cache) tables on the subscribers.
Sequences and replication
In some replication configurations, you may need to keep sequences synchronized between two or more databases. For example, you may have a master database containing a replicated table that uses a sequence to fill in the primary key value for each row. The subscriber database is used as a hot backup for the master database. If updates to the sequence's current value are not replicated, insertions of new rows on the subscriber after the master has failed could conflict with rows that were originally inserted on the master.
TimesTen replication allows the incremented sequence value to be replicated to subscriber databases, ensuring that rows in this configuration inserted on either database does not conflict. See "Replicating sequences" for details on writing a replication scheme to replicate sequences.
Foreign keys and replication
You may choose to replicate all or a subset of tables that have foreign key relationships with one another. However, the method for how to replicate the tables involved in the relationship differ according to the type of replication scheme. See the following for details:
Aging and replication
When a table or cache group is configured with least recently used (LRU) or time-based aging, the following rules apply to the interaction with replication:
-
The aging configuration on replicated tables and cache groups must be identical on every peer database.
-
If the replication scheme is an active standby pair, then aging is performed only on the active database. Deletes that result from aging are then replicated to the standby database. The aging configuration must be set to
ONon both the active and standby databases. TimesTen automatically determines which database is actually performing the aging based on its current role as active or standby. -
In a replication scheme that is not an active standby pair, aging is performed individually in each database. Deletes performed by aging are not replicated to other databases.
-
When an asynchronous writethrough cache group is in a database that is replicated by an active standby pair, delete operations that result from aging are not propagated to the Oracle database.