7 Working with Data in a TimesTen Database
This chapter provides detailed information on the basic components in a TimesTen database and simple examples of how you can use SQL to manage these components. For more information about SQL, see the Oracle TimesTen In-Memory Database SQL Reference.
For information on how to execute SQL from within a C or Java application, see "Managing TimesTen data" in the Oracle TimesTen In-Memory Database Java Developer's Guide or "Managing TimesTen data" in the Oracle TimesTen In-Memory Database C Developer's Guide.
This chapter includes the following topics:
Database overview
The following sections describe the main TimesTen database elements and features:
Database components
A TimesTen database has the following permanent components:
-
Tables. The primary components of a TimesTen database are the tables that contain the application data. See "Understanding tables".
-
Materialized Views. Read-only tables that hold a summary of data selected from one or more "regular" TimesTen tables. See "Understanding materialized views".
-
Views. Logical tables that are based on one or more tables called detail tables. A view itself contains no data. See "Understanding views".
-
Indexes. Indexes on one or more columns of a table may be created for faster access to tables. See "Understanding indexes".
-
Rows. Every table consists of 0 or more rows. A row is a formatted list of values. See "Understanding rows".
-
System tables. System tables contain TimesTen metadata, such as a table of all tables. See "System Tables" in the Oracle TimesTen In-Memory Database System Tables and Limits Reference.
There are also many temporary components, including prepared commands, cursors and locks.
Database users and owners
When access control is enabled, the TimesTen Data Manager authenticates user names with passwords. TimesTen Client/Server also authenticates users with passwords. Applications should choose one UID for the application itself because by default the login name that is being used to run the application becomes the owner of the database. If two different logins are used, TimesTen may have difficulty finding the correct tables. If you omit the UID connection attribute in the connection string, TimesTen uses the current user's login name. TimesTen converts all user names to upper case characters.
Users cannot access TimesTen databases as user SYS. TimesTen determines the user name by the value of the UID connection attribute, or if not present, then by the login name of the connected user. If a user's login is SYS, set the UID connection to override the login name.
Database persistence
When a database is created, it has either the permanent or temporary attribute set:
Note:
You cannot change the permanent or temporary attribute on a database after it is created.-
Permanent databases are stored to disk automatically through a procedure called checkpointing. TimesTen automatically performs background checkpoints based on the settings of the connection attributes
CkptFrequencyandCkptLogVolume. TimesTen also checkpoints the database when the last application disconnects. Applications can also checkpoint a database directly to disk by invoking thettCkptBlockingbuilt-in procedures described in the Oracle TimesTen In-Memory Database Reference. -
Temporary databases are not stored to disk. A temporary database is automatically destroyed when no applications are connected to it; that is, when the last connection disconnects or when there is a system or application failure. TimesTen removes all disk-based files when the last application disconnects.
A temporary database cannot be backed up or replicated. Temporary databases are never fully checkpointed to disk, although Checkpoint operations can have significant overhead for permanent databases, depending on database size and activity, but have very little impact for temporary databases. Checkpoints are still necessary to remove transaction log files.
However, temporary databases do have a transaction log, which is periodically written to disk, so transactions can be rolled back. The amount of data written to the transaction log for temporary databases is less than that written for permanent databases, allowing better performance for temporary databases. Recovery is never performed for temporary databases.
You can increase your performance with temporary databases. If you do not need to save the database to disk, you can save checkpoint overhead by creating a temporary database.
Details for setting up a temporary database are described in "Setting up a temporary database".
Understanding tables
A TimesTen table consists of rows that have a common format or structure. This format is described by the table's columns.
The following sections describes tables, its columns and how to manage them:
Overview of tables
This section includes the following topics:
Column overview
When you create the columns in the table, the column names are case-insensitive.
Each column has the following:
-
A data type
-
Optional nullability, primary key and foreign key properties
-
An optional default value
Unless you explicitly declare a column NOT NULL, columns are nullable. If a column in a table is nullable, it can contain a NULL value. Otherwise, each row in the table must have a non-NULL value in that column.
The format of TimesTen columns cannot be altered. It is possible to add or remove columns but not to change column definitions. To add or remove columns, use the ALTER TABLE statement. To change column definitions, an application must first drop the table and then recreate it with the new definitions.
In-line and out-of-line columns
The in-memory layout of the rows of a table is designed to provide fast access to rows while minimizing wasted space. TimesTen designates each VARBINARY, NVARCHAR and VARCHAR column of a table as either in-line or not inline.
-
An in-line column has a fixed length. All values of fixed-length columns of a table are stored row wise.
-
A not inline column has a varying length. Some
VARCHAR,NVARCHARorVARBINARYdata type columns are stored not inline. Not inline columns are not stored contiguously with the row but are allocated. Accessing out-of-line columns is slightly slower than accessing in-line columns. By default,VARCHAR,NVARCHARandVARBINARYcolumns whose declared column length is > 128 bytes are stored out of line. Columns whose declared column length is <= 128 bytes are stored inline.
The maximum sizes of in-line and out-of-line portions of a row are listed in "Estimating table size".
Default column values
When you create a table, you can specify default values for the columns. The default value you specify must be compatible with the data type of the column. You can specify one of the following default values for a column:
-
NULLfor any column type -
A constant value
-
SYSDATEforDATEandTIMESTAMPcolumns -
USERforCHARcolumns -
CURRENT_USERforCHARcolumns -
SYSTEM_USERforCHARcolumns
If you use the DEFAULT clause of the CREATE TABLE statement but do not specify the default value, the default value is NULL. See "Column Definition" in the Oracle TimesTen In-Memory Database SQL Reference.
Table names
A TimesTen table is identified uniquely by its owner name and table name. Every table has an owner. By default, the owner is the user who created the table. Tables created by TimesTen, such as system tables, have the owner name SYS, or TTREP if created during replication.
To uniquely refer to a table, specify both its owner and name separated by a period ("."), such as MARY.PAYROLL. If an application does not specify an owner, TimesTen looks for the table under the user name of the caller, then under the user name SYS.
A name is an alphanumeric value that begins with a letter. A name can include underscores. The maximum length of a table name is 30 characters. The maximum length of an owner name is also 30 characters. TimesTen displays all table, column and owner names to upper case characters. See "Names and parameters" in the Oracle TimesTen In-Memory Database SQL Reference for additional information.
Table access
Applications access tables through SQL statements. The TimesTen query optimizer automatically chooses a fast way to access tables. It uses existing indexes or, if necessary, creates temporary indexes to speed up access. For improved performance, applications should explicitly create indexes for frequently searched columns because the automatic creation and destruction of temporary indexes incurs a performance overhead. For more details, see "Tune statements and use indexes".
Primary keys, foreign keys and unique indexes
The creator of a TimesTen table can designate one or more columns as a primary key to indicate that duplicate values for that set of columns should be rejected. Primary key columns cannot be nullable. A table can have at most one primary key. TimesTen automatically creates a range index on the primary key to enforce uniqueness on the primary key and to guarantee fast access through the primary key. Indexes are discussed in "Understanding indexes". Once a row is inserted, its primary key columns cannot be modified, except to change a range index to a hash index.
Although a table may have only one primary key, additional uniqueness properties may be added to the table using unique indexes. See "CREATE INDEX" in the Oracle TimesTen In-Memory Database SQL Reference for more information.
Note:
Columns of a primary key cannot be nullable; a unique index can be built on nullable columns.A table may also have one or more foreign keys through which rows correspond to rows in another table. Foreign keys relate to a primary key or uniquely indexed columns in the other table. Foreign keys use a range index on the referencing columns. See "CREATE TABLE" in the Oracle TimesTen In-Memory Database SQL Reference for more information.
System tables
In addition to tables created by applications, a TimesTen database contains system tables. System tables contain TimesTen metadata such as descriptions of all tables and indexes in the database, as well as other information such as optimizer plans. Applications may query system tables just as they query user tables. Applications may not update system tables. TimesTen system tables are described in the "System Tables" chapter in the Oracle TimesTen In-Memory Database System Tables and Limits Reference.
Note:
TimesTen system table formats may change between releases and are different between the 32- and 64-bit versions of TimesTen.Working with tables
To perform any operation that creates, drops or manages a table, the user must have the appropriate privileges, which are described along with the syntax for all SQL statements in the "SQL Statements" chapter in the Oracle TimesTen In-Memory Database SQL Reference.
This section includes the following topics:
Creating a table
To create a table, use the SQL statement CREATE TABLE. The syntax for all SQL statements is provided in the Oracle TimesTen In-Memory Database SQL Reference. TimesTen converts table names to upper case characters.
The following SQL statement creates a table, called NameID, with two columns: CustId and CustName of two different data types.
CREATE TABLE NameID (CustId TT_INTEGER, CustName VARCHAR2(50));
Example 7-2 Create a table with a hash index
This example creates a table, called Customer, with the columns: CustId, CustName, Addr, Zip, and Region. The CustId column is designated as the primary key, so that the CustId value in a row uniquely identifies that row in the table, as described in "Primary keys, foreign keys and unique indexes". The UNIQUE HASH ON custId PAGES value indicates that there are 30 pages in the hash index. This number is used to determine the number of buckets that are to be allocated for the table's hash index. Bucket count = (PAGES * 256) / 20. Therefore the number of buckets allocated for the hash index is 384: (30 * 256) / 20 = 384
CREATE TABLE Customer (custId NUMBER NOT NULL PRIMARY KEY, custName CHAR(100) NOT NULL, Addr CHAR(100), Zip NUMBER, Region CHAR(10)) UNIQUE HASH ON (custId) PAGES = 30;
Implementing aging in your tables
You can define an aging policy for one or more tables in your database. An aging policy refers to the type of aging and the aging attributes, as well as the aging state (ON or OFF). You can specify one of the following types of aging policies: usage-based or time-based. Usage-based aging removes least recently used (LRU) data within a specified database usage range. Time-based aging removes data based on the specified data lifetime and frequency of the aging process. You can define both usage-based aging and time-based aging in the same database, but you can define only one type of aging on a specific table.
You can define an aging policy for a new table with the CREATE TABLE statement. You can add an aging policy to an existing table with the ALTER TABLE statement if the table does not already have an aging policy defined. You can change the aging policy by dropping aging and adding a new aging policy.
You cannot specify aging on the following types of tables:
-
Global temporary tables
-
Detail tables for materialized views
You can also implement aging in cache groups. See "Implementing aging on a cache group" in the Oracle In-Memory Database Cache User's Guide.
This section includes the following topics:
Usage-based aging
Usage-based aging enables you to maintain the amount of memory used in a database within a specified threshold by removing the least recently used (LRU) data.
Define LRU aging for a new table by using the AGING LRU clause of the CREATE TABLE statement. Aging begins automatically if the aging state is ON.
Use the ttAgingLRUConfig built-in procedure to specify the LRU aging attributes. The attribute values apply to all tables in the database that have an LRU aging policy. If you do not call the ttAgingLRUConfig built-in procedure, then the default values for the attributes are used.
Note:
ThettAgingLRUConfig built-in procedure requires that the user have ADMIN privilege if you want to modify any attributes. You do not need any privileges for viewing existing attributes. For more information, see "Built-In Procedures" in the Oracle TimesTen In-Memory Database Reference.The following table summarizes the LRU aging attributes:
| LRU Aging Attribute | Description |
|---|---|
LowUsageThreshhold |
The percent of the database PermSize at which LRU aging is deactivated. |
HighUsageThreshhold |
The percent of the database PermSize at which LRU aging is activated. |
AgingCycle |
The number of minutes between aging cycles. |
If you set a new value for AgingCycle after an LRU aging policy has already been defined, aging occurs based on the current time and the new cycle time. For example, if the original aging cycle is 15 minutes and LRU aging occurred 10 minutes ago, aging is expected to occur again in 5 minutes. However, if you change the AgingCycle parameter to 30 minutes, then aging occurs 30 minutes from the time you call the ttAgingLRUConfig procedure with the new value for AgingCycle.
If a row has been accessed or referenced since the last aging cycle, it is not eligible for LRU aging. A row is considered to be accessed or referenced if one of the following is true:
-
The row is used to build the result set of a
SELECTstatement. -
The row has been flagged to be updated or deleted.
-
The row is used to build the result set of an
INSERT SELECTstatement.
You can use the ALTER TABLE statement to perform the following tasks:
-
Enable or disable the aging state on a table that has an aging policy defined by using the
ALTER TABLEstatement with theSET AGING{ON|OFF} clause. -
Add an LRU aging policy to an existing table by using the
ALTER TABLEstatement with theADD AGING LRU[ON|OFF] clause. -
Drop aging on a table by using the
ALTER TABLEstatement with theDROP AGINGclause.
Use the ttAgingScheduleNow built-in procedure to schedule when aging starts. For more information, see "Scheduling when aging starts".
To change aging from LRU to time-based on a table, first drop aging on the table by using the ALTER TABLE statement with the DROP AGING clause. Then add time-based aging by using the ALTER TABLE statement with the ADD AGING USE clause.
Note:
When you drop LRU aging or add LRU aging to tables that are referenced in commands, TimesTen marks the compiled commands invalid. The commands need to be recompiled.Time-based aging
Time-based aging removes data from a table based on the specified data lifetime and frequency of the aging process. Specify a time-based aging policy for a new table with the AGING USE clause of the CREATE TABLE statement. Add a time-based aging policy to an existing table with the ADD AGING USE clause of the ALTER TABLE statement.
The AGING USE clause has a ColumnName argument.ColumnName is the name of the column that is used for time-based aging. For brevity, we will call it the timestamp column. The timestamp column must be defined as follows:
-
ORA_TIMESTAMP,TT_TIMESTAMP,ORA_DATEorTT_DATEdata type -
NOT NULL
Your application updates the values of the timestamp column. If the value of this column is unknown for some rows and you do not want the rows to be aged, then define the column with a large default value. You can create an index on the timestamp column for better performance of the aging process.
Note:
You cannot add or modify a column in an existing table and then use that column as a timestamp column because you cannot add or modify a column and define it to beNOT NULL.You cannot drop the timestamp column from a table that has a time-based aging policy.
If the data type of the timestamp column is ORA_TIMESTAMP, TT_TIMESTAMP, or ORA_DATE, you can specify the lifetime in days, hours, or minutes in the LIFETIME clause of the CREATE TABLE statement. If the data type of the timestamp column is TT_DATE, specify the lifetime in days.
The value in the timestamp column is subtracted from SYSDATE. The result is truncated the result using the specified unit (minute, hour, day) and compared with the specified LIFETIME value. If the result is greater than the LIFETIME value, then the row is a candidate for aging.
Use the CYCLE clause to indicate how often the system should examine the rows to remove data that has exceeded the specified lifetime. If you do not specify CYCLE, aging occurs every five minutes. If you specify 0 for the cycle, then aging is continuous. Aging begins automatically if the state is ON.
Use the ALTER TABLE statement to perform the following tasks:
-
Enable or disable the aging state on a table with a time-based aging policy by using the
SET AGING{ON|OFF} clause. -
Change the aging cycle on a table with a time-based aging policy by using the
SET AGING CYCLEclause. -
Change the lifetime by using the
SET AGING LIFETIMEclause. -
Add time-based aging to an existing table with no aging policy by using the
ADD AGING USEclause. -
Drop aging on a table by using the
DROP AGINGclause.
Use the ttAgingScheduleNow built-in procedure to schedule when aging starts. For more information, see "Scheduling when aging starts"
To change the aging policy from time-based aging to LRU aging on a table, first drop time-based aging on the table. Then add LRU aging by using the ALTER TABLE statement with the ADD AGING LRU clause.
Aging and foreign keys
Tables that are related by foreign keys must have the same aging policy.
If LRU aging is in effect and a row in a child table has been recently accessed, then neither the parent row nor the child row will be deleted.
If time-based aging is in effect and a row in a parent table is a candidate for aging out, then the parent row and all of its children will be deleted.
If a table has ON DELETE CASCADE enabled, the setting is ignored.
Scheduling when aging starts
Use the ttAgingScheduleNow built-in procedure to schedule the aging process. The aging process starts as soon as you call the procedure unless there is already an aging process in progress, in which case it will begin when that aging process has completed.
When you call ttAgingScheduleNow, the aging process starts regardless of whether the state is ON or OFF.
The aging process starts only once as a result of calling ttAgingScheduleNow does not change the aging state. If the aging state is OFF when you call ttAgingScheduleNow, then the aging process starts, but it does not continue after the process is complete. To continue aging, you must call ttAgingScheduleNow again or change the aging state to ON.
If the aging state is already set to ON, then ttAgingScheduleNow resets the aging cycle based on the time ttAgingScheduleNow was called.
You can control aging externally by disabling aging by using the ALTER TABLE statement with the SET AGING OFF clause. Then use ttAgingScheduleNow to start aging at the desired time.
Use ttAgingScheduleNow to start or reset aging for an individual table by specifying its name when you call the procedure. If you do not specify a table name, then ttAgingScheduleNow will start or reset aging on all of the tables in the database that have aging defined.
Aging and replication
For active standby pairs, implement aging on the active master database. Deletes that occur as a result of aging will be replicated to the standby master database and the read-only subscribers. If a failover to the standby master database occurs, aging is enabled on the database after its role changes to ACTIVE.
For all other types of replication schemes, implement aging separately on each node. The aging policy must be the same on all nodes.
If you implement LRU aging on a multimaster replication scheme used as a hot standby, LRU aging may provide unintended results. After a failover, you may not have all of the desired data because aging occurs locally.
Understanding views
A view is a logical table that is based on one or more tables. The view itself contains no data. It is sometimes called a non-materialized view to distinguish it from a materialized view, which does contain data that has already been calculated from detail tables. Views cannot be updated directly, but changes to the data in the detail tables are immediately reflected in the view.
To choose whether to create a view or a materialized view, consider where the cost of calculation lies. For a materialized view, the cost falls on the users who update the detail tables because calculations must be made to update the data in the materialized views. For a nonmaterialized view, the cost falls on a connection that queries the view, because the calculations must be made at the time of the query.
To perform any operation that creates, drops or manages a view, the user must have the appropriate privileges, which are described along with the syntax for all SQL statements in the "SQL Statements" chapter in the Oracle TimesTen In-Memory Database SQL Reference.
This section includes the following topics:
Creating a view
To create a view, use the CREATE VIEW SQL statement. The syntax for all SQL statements is provided in the "SQL Statements" chapter in the Oracle TimesTen In-Memory Database SQL Reference.
CREATE VIEW ViewName AS SelectQuery;
This selects columns from the detail tables to be used in the view.
For example, create a view from the table t1:
CREATE VIEW v1 AS SELECT * FROM t1;
Now create a view from an aggregate query on the table t1:
CREATE VIEW v1 (max1) AS SELECT max(x1) FROM t1;
The SELECT query in the CREATE VIEW statement
The SELECT query used to define the contents of a materialized view is similar to the top-level SQL SELECT statement described in "SQL Statements" in the Oracle TimesTen In-Memory Database SQL Reference, with the following restrictions:
-
A
SELECT *query in a view definition is expanded at view creation time. Any columns added after a view is created do not affect the view. -
The following cannot be used in a
SELECTstatement that is creating a view: -
DISTINCT -
FIRST -
ORDER BY -
Arguments
-
Temporary tables
-
Each expression in the select list must have a unique name. A name of a simple column expression would be that column's name unless a column alias is defined. RowId is considered an expression and needs an alias.
-
No
SELECT FOR UPDATEorSELECT FOR INSERTstatements can be used on a view. -
Certain TimesTen query restrictions are not checked when a non-materialized view is created. Views that violate those restrictions may be allowed to be created, but an error is returned when the view is referenced later in an executed statement.
Dropping a view
The DROP VIEW statement deletes the specified view.
The following statement drops the CustOrder view:
DROP VIEW CustOrder;
Restrictions on views and detail tables
Views have the following restrictions:
-
When a view is referenced in the
FROMclause of aSELECTstatement, its name is replaced by its definition as a derived table at parsing time. If it is not possible to merge all clauses of a view to the same clause in the original select to form a legal query without the derived table, the content of this derived table is materialized. For example, if both the view and the referencing select specify aggregates, the view is materialized before its result can be joined with other tables of the select. -
A view cannot be dropped with a
DROP TABLEstatement. You must use theDROP VIEWstatement. -
A view cannot be altered with an
ALTER TABLEstatement. -
Referencing a view can fail due to dropped or altered detail tables.
Understanding materialized views
The following sections describes materialized views and how to manage them:
Overview of materialized views
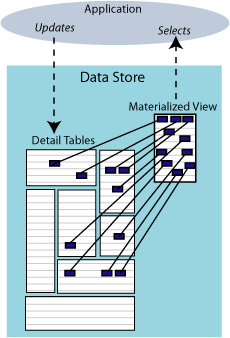
A materialized view is a read-only table that maintains a summary of data selected from one or more regular TimesTen tables. The TimesTen tables queried to make up the result set for the materialized view are called detail tables.
Note:
Materialized views are not supported on cache tables.Figure 7-1 shows a materialized view created from detail tables. An application updates the detail tables and can select data from the materialized view.
There are two types of materialized views based upon how the result set for the materialized view is updated.
In addition, learn when to use each type of materialized views in the section: "When to use synchronous or asynchronous materialized views".
Synchronous materialized view
The synchronous materialized view, by default, updates the result set data from the detail tables at the time of the detail table transaction. Every time data is updated in the detail tables, the result set is updated. Thus, the synchronous materialized view is never out of sync with the detail tables. However, this can affect your performance. A single transaction, the user transaction, executes the updates for both the detail table and any synchronous materialized views.
Asynchronous materialized view
The materialized view is populated and it is in sync with the detail tables at creation. When the detail tables are updated, the asynchronous materialized views are not updated immediately. At any moment, they can be out of sync with the corresponding detail tables. The asynchronous materialized view defers updates to the result set as a trade-off for performance. You decide when and how the result set is refreshed either manually by the user or automatically within a pre-configured interval. The asynchronous materialized view is always refreshed in its own transaction, not within the user transaction that updates the detail tables. Thus, the user transaction is not blocked by any updates for the asynchronous materialized view.
The asynchronous refresh may use either of the following refresh method configurations:
-
FAST, which updates only the incremental changes since the last update. -
COMPLETE, which provides a full refresh.
To facilitate a FAST refresh, you must create a materialized view log to manage the deferred incremental transactions for each detail table used by the asynchronous materialized view. Each detail table requires only one materialized view log for managing all deferred transactions, even if it is included in more than one FAST asynchronous materialized view.
The detail table cannot be dropped if there is an associated materialized view or materialized view log.
Note:
When you use XLA in conjunction with asynchronous materialized views, you cannot depend on the ordering of the DDL statements. In general, there are no operational differences between the XLA mechanisms used to track changes to a table or a materialized view. However, for asynchronous materialized views, be aware that the order of XLA notifications for an asynchronous view is not necessarily the same as it would be for the associated detail tables, or the same as it would be for asynchronous view. For example, if there are two inserts to a detail table, they may be done in the opposite order in the asynchronous materialized view. Furthermore, updates may be treated as a delete followed by an insert, and multiple operations, such as multiple inserts or multiple deletes, may be combined. Applications that depend on ordering should not use asynchronous materialized views.When to use synchronous or asynchronous materialized views
The following sections provide guidelines on when to use synchronous or asynchronous materialized views:
Joins and aggregate functions turn into super locks
If a synchronous materialized view has joins or uses aggregate functions, there is a super lock effect. For example, if you have a single table with a synchronous materialized view that aggregates on average 1000 rows into 1. When you update a row in the detail table of the synchronous materialized view, you lock that row for the remainder of the transaction. Any other transaction that attempts to update that row blocks and waits until the transaction commits.
But since there is a synchronous materialized view on that table, the materialized view is also updated. The single row in the materialized view is locked and updated to reflect the change. However, there are 999 other rows from the base table that also aggregate to that same materialized view row. These 999 other base table rows are also effectively locked because if you try to update any of them, you will block and wait while retrieving the lock on the materialized view row. This is referred to as a super lock.
The same effect occurs across joins. If you have a synchronous materialized view that joins five tables and you update a row in any one of the five tables, you will have a super lock on all the rows in the other four tables that join to the one that you updated.
Obviously, the combination of joins and aggregate functions compound the problem for synchronous materialized views. However, asynchronous materialized views with COMPLETE refresh diminish the super lock because the locks on the asynchronous materialized view rows with COMPLETE refresh are only held during the refresh process. The super locks with synchronous materialized views will be held until the updating transaction commits. Thus, if you have short transactions, then super locks on synchronous materialized view are not a problem. However, if you have long transactions, use asynchronous materialized views with COMPLETE refresh that minimize the effect of any super lock.
Freshness of the materialized view
Synchronous materialized views are always fresh and they always return the latest data. Asynchronous materialized views can become stale after an update until refreshed. If you must have the most current data all the time, use synchronous materialized views. However, you may consider using asynchronous if your application does not need the most current data.
For example, you may execute a series of analytical queries each with variations. In this case, you can use an asynchronous materialized view to isolate the differences that result from the query variations from the differences that result from newly arrived or updated data.
Overhead cost
An asynchronous materialized view is not updated in the user transaction, which updates the detail tables. The refresh of an asynchronous materialized view is always performed in an independent transaction. This means that the user is free to execute any other transaction. By comparison, for synchronous materialized views, a single transaction executes the updates for both the detail table and any synchronous materialized views, which does affect your performance.
While the asynchronous materialized view logs for asynchronous materialized views with FAST refresh incur overhead, it is generally less overhead than the cost of updating a synchronous materialized view. This is especially true even if the asynchronous materialized view is complicated with joins. For asynchronous materialized views with COMPLETE refresh, there is no overhead at the time of updating the detail table.
You can defer asynchronous materialized view maintenance cost. The asynchronous materialized view log costs less than the incremental maintenance of the synchronous materialized view because the asynchronous materialized view logs perform simple inserts, whereas synchronous materialized view maintenance has to compute the delta for the materialized view and joins and then apply results in an update operation. Updates are more expensive than inserts. The cost difference reduces if the synchronous materialized view is simple in structure.
Working with materialized views
This section includes the following topics:
Creating a materialized view
To create a materialized view, use the SQL statement CREATE MATERIALIZED VIEW.
Note:
In order to create a materialized view, the user must have the appropriate privileges, which are described along with the syntax for all SQL statements in the "SQL Statements" chapter in the Oracle TimesTen In-Memory Database SQL Reference.If the owner has these privileges revoked for any of the detail tables on which the materialized view is created, the materialized view becomes invalid. See "Object privileges for materialized views" for details.
When creating a materialized view, you can establish primary keys and the size of the hash table in the same manner as described for tables in "Primary keys, foreign keys and unique indexes".
The materialized view examples are based on the following two tables:
CREATE TABLE customer(custId int not null, custName char(100) not null, Addr char(100), Zip int, Region char(10), PRIMARY KEY (custId)); CREATE TABLE bookOrder(orderId int not null, custId int not null, book char(100), PRIMARY KEY (orderId), FOREIGN KEY (custId) REFERENCES Customer(custId));
The following sections provide details and examples for creating materialized views:
Creating a synchronous materialized view
A synchronous materialized view is automatically updated each time the detail tables are updated. You can create a synchronous materialized view with the CREATE MATERIALIZED VIEW statement.
The following creates a synchronous materialized view, named SampleMV, that generates a result set from selected columns in the customer and bookOrder detail tables described above.
CREATE MATERIALIZED VIEW SampleMV AS SELECT customer.custId, custName, orderId, book FROM customer, bookOrder WHERE customer.custId=bookOrder.custId;
Creating an asynchronous materialized view
An asynchronous materialized view is updated as specified by the refresh method and refresh interval, which are configured during the creation of the materialized view.
When you create an asynchronous materialized view, you specify the REFRESH clause with at least one of the following:
-
Refresh method: For the asynchronous materialized view, specify either
FASTorCOMPLETEfor the refresh method.FASTdenotes an incremental refresh.COMPLETEindicates a full refresh. If the refresh method is omitted, then complete is the default refresh method. If you specifyFAST, then you must create the asynchronous materialized view log for each detail table associated with the materialized view.Note:
Aggregate functions and outer joins are not supported in aFASTrefresh. -
Refresh interval:
-
Manual update: If the refresh interval is not specified, the interval defaults to manual update. You can manually refresh the view by using the
REFRESH MATERIALIZED VIEWstatement, which is described at the end of this section. -
Specify refresh after every commit: When you specify
NEXT SYSDATEwithout specifyingNUMTODSINTERVL(), the refresh is performed after every commit of any user transaction that updates the detail tables. This refresh is always performed in a separate transaction. The user transaction does not wait for the refresh to complete. The option to refresh at every commit is only supported for the fast refresh method. -
Specify interval: The asynchronous materialized view is updated at a specified interval when you use the
NEXT SYSDATE + NUMTODSINTERVAL(IntegerLiteral,IntervalUnit) clause. This option is supported for both FAST and COMPLETE refresh methods.This clause specifies that the materialized view will be refreshed at the specified interval.
IntegerLiteralmust be an integer.IntervalUnitmust be one of the following values:'DAY','HOUR','MINUTE','SECOND'.The last refresh time is saved in order to determine the next refresh time. Refresh is skipped if there are no changes to the any of the detail tables of the asynchronous materialized view since the last refresh. If you want to modify a configured refresh interval, you must drop and recreate the asynchronous materialized view.
-
If you use the fast refresh method, the deferred transactions are saved in a materialized view log. Thus, before you create your asynchronous materialized view, you must create a materialized view log for each detail table included in the asynchronous materialized view that uses fast refresh. Each detail table can have only one materialized view log even if they are used by more than one asynchronous materialized view with fast refresh. All columns referenced in an asynchronous materialized view must be included in the corresponding asynchronous materialized view log. If there is more than one asynchronous materialized view with fast refresh created on a detail table, make sure to include all columns that are used in the different asynchronous materialized views created for that detail table in its asynchronous materialized view log.
The following example creates an asynchronous materialized view that uses fast refresh, where the deferred transactions are updated every hour after creation. First, create the materialized view log for each detail table, customer and bookOrder. The following statements create the materialized log views for customer and bookOrder to track the deferred transactions for the fast refresh. The materialized view log for customer tracks the primary key and the customer name as follows:
CREATE MATERIALIZED VIEW LOG ON customer WITH PRIMARY KEY (custName);
Note:
In theCREATE MATERIALIZED VIEW LOG syntax, the primary key is included if you specify WITH PRIMARY KEY or do not mention either PRIMARY KEY or ROWID. All non-primary key columns that you want included in the materialized view log must be specified in the parenthetical column list.The materialized view log for the bookorder table tracks the primary key of orderId and columns custId, and book.
CREATE MATERIALIZED VIEW LOG ON bookOrder WITH (custId, book);
Once you create the materialized view log for both the customer and bookOrder detail tables, you can create an asynchronous materialized view. The asynchronous materialized view must include either the ROWID or primary key columns for all the detail tables.
The following example creates an asynchronous materialized view named SampleAMV that generates a result set from selected columns in the customer and bookOrder detail tables. The statement specifies a fast refresh to update the deferred transactions every hour from the moment of creation.
CREATE MATERIALIZED VIEW SampleAMV
REFRESH
FAST
NEXT SYSDATE + NUMTODSINTERVAL(1, 'HOUR')
AS SELECT customer.custId, custName, orderId, book
FROM customer, bookOrder
WHERE customer.custId=bookOrder.custId;
If you want to manually refresh the materialized view, execute the REFRESH MATERIALIZED VIEW statement. You can manually refresh the materialized view at any time, even if a REFRESH interval is specified. For example, if there were multiple updates to the detail tables, you can manually refresh the SampleAMV materialized view as follows:
REFRESH MATERIALIZED VIEW SampleAMV;
The SELECT query in the CREATE MATERIALIZED VIEW statement
The SELECT query used to define the contents of a materialized view is similar to the top-level SQL SELECT statement described in "SQL Statements" in the Oracle TimesTen In-Memory Database SQL Reference, with the following restrictions:
-
All columns in the
GROUP BYGroupColumnListmust be included in theSelectList. -
SUMandCOUNTare allowed, but not expressions involving them, includingAVG. -
The following cannot be used in a
SELECTstatement that is creating a materialized view:-
DISTINCT -
FIRST -
HAVING -
ORDER BY -
UNION -
UNION ALL -
MINUS -
INTERSECT -
JOIN -
User functions:
USER,CURRENT_USER,SESSION_USER -
Subqueries
-
NEXTVALandCURRVAL -
Derived tables and joined tables
-
-
Each expression in the SelectList must have a unique name. A name of a simple column expression would be that column's name unless a column alias is defined.
ROWIDis considered an expression and needs an alias. -
Self joins are allowed. A self join is a join of a table to itself. This table appears more than once in the
FROMclause and is followed by table aliases that qualify column names in the join condition.
For synchronous materialized views or asynchronous materialized views that use complete refresh, the following is true for the SELECT statement:
-
Aggregate views must include a
COUNT(*)in the SelectList so that TimesTen can do incremental updates of a group. For example, a group should be removed if its count becomes zero. -
Outer joins are allowed, but the
SELECTlist must project at least one non-nullable column from each of the inner tables specified in theOUTER JOIN.OUTER JOINsyntax for aSELECTin a materialized view definition is identical to that in a top-levelSELECT. The restrictions noted in the description ofSELECTstatements apply. The (+) symbol must be used to specify outer joins of a materialized view.
For asynchronous materialized views that use fast refresh, the following is true for the SELECT statement:
-
Aggregate functions are not supported.
-
Outer joins are not supported.
-
SELECTlist must includeROWIDor the primary key columns for all the included detail tables.
Dropping a materialized view or a materialized view log
To drop any materialized view, execute the DROP VIEW statement.
The following statement drops the sampleMV materialized view.
DROP VIEW sampleMV;
When there are no asynchronous materialized views referencing a table, the materialized view log on that table can be dropped. For example, if you have dropped the materialized view sampleAMV, then the following statements drop the associated materialized view logs.
DROP MATERIALIZED VIEW LOG ON customer; DROP MATERIALIZED VIEW LOG ON bookOrder;
The syntax for all SQL statements is provided in the "SQL Statements" chapter in the Oracle TimesTen In-Memory Database SQL Reference.
Identifying the table associated with a materialized view log
Materialized view logs are represented in the TimesTen system tables as a table named MVLOG$_detailTableId, where detailTableId is the table id of the table on which it was created. The table id and table name are both recorded in SYS.TABLES. For example, if the materialized view log filename is MVLOG$_507244, then you can retrieve the table name from SYS.TABLES where the table id is 507244 as follows:
select tblname from sys.tables where tblid = 507244; < T1 > 1 row found.
Restrictions on materialized views and detail tables
A materialized view is a read-only table that cannot be updated directly. This means a materialized view cannot be updated by an INSERT, DELETE, or UPDATE statement by replication, XLA, or the cache agent.
For example, any attempt to update a row in a materialized view generates the following error:
805: Update view table directly has not been implemented
Readers familiar with other implementations of materialized views should note the following characteristics of TimesTen views:
-
Detail tables can be replicated, but materialized views cannot.
-
Neither a materialized view nor its detail tables can be part of a cache group.
-
No referential indexes can be defined on the materialized view.
-
To drop a materialized view must use the
DROP VIEWstatement. -
You cannot alter a materialized view. You must use the
DROP VIEWstatement and then create a new materialized view with aCREATE MATERIALIZED VIEWstatement. -
Materialized views must be explicitly created by the application. The TimesTen query optimizer has no facility to automatically create materialized views.
-
The TimesTen query optimizer does not rewrite queries on the detail tables to reference materialized views. Application queries must directly reference views, if they are to be used.
-
There are some restrictions to the SQL used to create materialized views. See "CREATE MATERIALIZED VIEW" in the Oracle TimesTen In-Memory Database SQL Reference for details.
Performance implications of materialized views
The following sections describes performance implications for each type of materialized view:
Managing performance for asynchronous materialized views
For managing performance, you can defer the refresh of the materialized view until an optimal time. Rows in the materialized view logs, detail table and materialized view may be locked during the refresh. If these locks interfere with the user transaction updating the detail tables, then the user can adjust the refresh interval. If performance is the highest priority and the asynchronous materialized view can be out of sync with the detail tables, set the refresh interval to execute when the system load is low.
-
FAST refresh incrementally updates the materialized view based on the changes captured in the materialized view log. The time for this refresh depends on the number of modifications captured in the materialized view log and the complexities of the
SELECTstatement used in theCREATE MATERIALIZED VIEWstatement. After every refresh, the processed rows in the materialized view log are deleted.Update table statistics on the detail table, materialized view log tables and the materialized view at periodic intervals to improve the refresh performance. If the view involves joins, update table statistics before inserting any row in any of the detail tables. Table statistics can be updated using the
ttOptEstimateStatsbuilt-in procedure. -
A complete refresh is similar to the initial loading of the materialized view at creation time. The time for this refresh depends on the number of rows in the detail tables.
Managing performance for synchronous materialized views
The performance of UPDATE and INSERT operations may be impacted if the updated table is referenced in a materialized view. The performance impact depends on many factors, such as the following:
-
Nature of the materialized view: How many detail tables, whether outer join or aggregation is used.
-
Which indexes are present on the detail table and on the materialized view.
-
How many materialized view rows will be affected by the change.
A view is a persistent, up-to-date copy of a query result. To keep the view up to date, TimesTen must perform "view maintenance" when you change a view's detail table. For example, if you have a view named V that selects from tables T1, T2, and T3, then any time you insert into T1, or update T2, or delete from T3, TimesTen performs "view maintenance."
View maintenance needs appropriate indexes just like regular database operations. If they are not there, view maintenance will perform poorly.
All update, insert, or delete statements on detail tables have execution plans, as described in "The TimesTen Query Optimizer". For example, an update of a row in T1 will have a first stage of the plan where it updates the view V, followed by a second stage where it updates T1.
For fast view maintenance, you should evaluate the plans for all the operations that update the detail tables, as follows:
-
Examine all the
WHEREclauses for the update or delete statements that frequently occur on the detail tables. Note any clause that uses an index key. For example, if the operations that an application performs 95 percent of the time are as follows:UPDATE T1 set A=A+1 WHERE K1=? AND K2=? DELETE FROMT2 WHERE K3=?
Then the keys to note are (
K1,K2) andK3. -
Ensure that the view selects all of those key columns. In this example, the view should select
K1,K2, andK3. -
Create an index on the view on each of those keys. In this example, the view should have two indexes, one on (
V.K1,V.K2) and one onV.K3. The indexes do not have to be unique. The names of the view columns can be different from the names of the table columns, though they are the same in this example.
With this method, when you update a detail table, your WHERE clause is used to do the corresponding update of the view. This allows maintenance to be executed in a batch, which has better performance.
The above method may not always work, however. For example, an application may have many different methods to update the detail tables. The application would have to select far too many items in the view or create too many indexes on the view, taking up more space or more performance than you might wish. An alternative method is as follows:
-
For each table in the view's
FROMclause (each detail table), check which ones are frequently changed byUPDATE,INSERTandCREATE VIEWstatements. For example, a view'sFROMclause may have tablesT1,T2,T3,T4, andT5, but of those, onlyT2andT3are frequently changed. -
For each of those tables, make sure the view selects its rowids. In this example, the view should select
T2.rowid andT3.rowid. -
Create an index on the view on each of those rowid columns. In this example, the columns might be called
T2rowidandT3rowid, and indexes would be created onV.T2rowidandV.T3rowid.
With this method, view maintenance is done on a row-by-row basis, rather than on a batch basis. But the rows can be matched very efficiently between a view and its detail tables, which speeds up the maintenance. It is generally not as fast as the first method, but it is still good.
Understanding indexes
Indexes are auxiliary data structures that greatly improve the performance of table searches. They are used automatically by the query optimizer to speed up the execution of a query. For information about the query optimizer, see "The TimesTen Query Optimizer".
You can designate an index as unique, which means that each row in the table has a unique value for the indexed column or columns. Unique indexes can be created over nullable columns. In conformance with the SQL standard, multiple NULL values are permitted in a unique index.
When sorting data values, TimesTen considers NULL values to be larger than all non-NULL values. See the Oracle TimesTen In-Memory Database SQL Reference for more information on NULL values.
To perform any operation that creates, drops or alters an index, the user must have the appropriate privileges, which are described along with the syntax for all SQL statements in the "SQL Statements" chapter in the Oracle TimesTen In-Memory Database SQL Reference.
The following sections describe how to manage your index:
Overview of index types
TimesTen provides three types of indexes to enable fast access to tables.
-
Hash Indexes. Hash indexes are useful for finding rows with an exact match on one or more columns. Hash indexes are useful for doing equality searches. TimesTen currently supports a maximum of one hash index per table. A hash index is created with the
UNIQUE HASHoption, which is specified over the columns that make up the primary key of a table.The "CREATE TABLE" section of the Oracle TimesTen In-Memory Database SQL Reference discusses in detail the automatic creation of hash indexes. For an example of how to create a hash index when creating the table, see Example 7-2.
-
Range Indexes. Range indexes are useful for finding rows with column values within a certain range. You can create range indexes over one or more columns of a table. Up to 32 range indexes may be created on one table.
Range indexes and equijoins can be used for equality and range searches, such as greater than or equal to, less than or equal to, and so on. If you have a primary key on a field and want to see if
FIELD > 10, then the primary key index will not expedite finding the answer, but a separate index will.The "CREATE INDEX" section of the Oracle TimesTen In-Memory Database SQL Reference discusses in describes how to create range indexes.
Note:
Hash indexes are faster than range indexes for exact match lookups, but they require more space than range indexes. Hash indexes cannot be used for lookups involving ranges. -
Bitmap Indexes. Bitmap indexes are useful when searching and retrieving data from columns with low cardinality. That is, these columns can have only a few unique possible values. Bitmap indexes encode information about a unique value in a row in a bitmap. Each bit in the bitmap corresponds to a row in the table. Use a bitmap index for columns that do not have many unique values. An example of such a column is a column that records gender as one of two values.
Bitmap indexes increase the performance of complex queries that specify multiple predicates on multiple columns connected by
ANDandORoperators.See "CREATE INDEX" in the Oracle TimesTen In-Memory Database SQL Reference for how to create and more information on bitmap indexes.
Note:
Alternatively, you can perform lookups by RowID for fast access to data. See the Oracle TimesTen In-Memory Database SQL Reference for more information on RowIDs.Creating an index
To create an index, execute the SQL statement CREATE INDEX. TimesTen converts index names to upper case characters.
Every index has an owner. The owner is the user who created the underlying table. Indexes created by TimesTen itself, such as indexes on system tables, are created with the user name SYS or with the user name TTREP if created during replication.
Create an index IxID over column CustID of table NameID.
CREATE INDEX IxID ON NameID (CustID);
You can also create a hash index by creating a primary key or using the UNIQUE HASH ON clause in the CREATE TABLE. However, TimesTen may create temporary hash and range indexes automatically during query processing to speed up query execution.
Altering an index
You can change a range index to a hash index with the USE HASH INDEX of the ALTER TABLE statement.
Dropping an index
To uniquely refer to an index, an application must specify both its owner and name. If the application does not specify an owner, TimesTen looks for the index first under the user name of the caller, then under the user name SYS.
To drop a TimesTen index, execute the DROP INDEX SQL statement. All indexes in a table are dropped automatically when the table is dropped.
Understanding rows
Rows are used to store TimesTen data. TimesTen supports several data types for fields in a row, including:
-
One-byte, two-byte, four-byte and eight-byte integers.
-
Four-byte and eight-byte floating-point numbers.
-
Fixed-length and variable-length character strings, both ASCII and Unicode.
-
Fixed-length and variable-length binary data.
-
Fixed-length fixed-point numbers.
-
Time represented as
hh:mm:ss [AM|am|PM|pm]. -
Date represented as
yyyy-mm-dd. -
Timestamp represented as
yyyy-mm-dd hh:mm:ss.
The "Data Types" section in the Oracle TimesTen In-Memory Database SQL Reference contains a detailed description of these data types.
To perform any operation for inserting or deleting rows, the user must have the appropriate privileges, which are described along with the syntax for all SQL statements in the "SQL Statements" chapter in the Oracle TimesTen In-Memory Database SQL Reference.
The following sections describe how to manage your rows:
Inserting rows
To insert a row, execute INSERT or INSERT SELECT. You can also use the ttBulkCp utility.
Example 7-6 Insert a row in a table
To insert a row in the table NameID, enter:
INSERT INTO NameID VALUES(23125, 'John Smith';
Note:
When inserting multiple rows into a table, it is more efficient to use prepared commands and parameters in your code. Create Indexes after the bulk load is completed.Understanding synonyms
A synonym is an alias for a database object. Synonyms are often used for security and convenience, because they can be used to mask object name and object owner. In addition, you can use a synonym to simplify SQL statements. Synonyms provide independence in that they permit applications to function without modification regardless of which object a synonym refers to. Synonyms can be used in DML statements and some DDL and IMDB cache statements.
Synonyms are categorized into two classes:
-
Private synonyms: A private synonym is owned by a specific user and exists in the schema of a specific user. A private synonym shares the same namespace as all other object names, such as table names, view names, sequence names, and so on. Therefore, a private synonym cannot have the same name as a table name or a view name in the same schema.
-
Public synonyms: A public synonym is owned by all users and every user in the database can access it. A public synonym is accessible for all users and it does not belong to any user schema. Therefore, a public synonym can have the same name as a private synonym name or a table name.
In order to create and use synonyms, the user must have the correct privileges, which are described in "Object privileges for synonyms".
After synonyms are created, they can be viewed using the following views:
-
SYS.ALL_SYNONYMS: describes the synonyms accessible to the current user. -
SYS.DBA_SYNONYMS: describes all synonyms in the database. -
SYS.USER_SYNONYMS: describes the synonyms owned by the current user.
For full details on these views, see the Oracle TimesTen In-Memory Database Reference.
Creating synonyms
Create the synonym with the CREATE SYNONYM statement. You can use the CREATE OR REPLACE SYNONYM statement to change the definition of an existing synonym without needing to drop it first. The CREATE SYNONYM and CREATE OR REPLACE SYNONYM statements specify the synonym name and the schema name in which the synonym is created. If the schema is omitted, the synonym is created in the user's schema. However, when creating public synonyms, you do not provide the schema name as it will be defined in the PUBLIC namespace.
In order to execute the CREATE SYNONYM or CREATE OR REPLACE SYNONYM statements, the user must have the appropriate privileges, as described in "Object privileges for synonyms".
-
Object types for synonyms: The
CREATE SYNONYMandCREATE OR REPLACE SYNONYMstatements define an alias for a particular object, which can be one of the following object types: table, view, synonym, sequence, PL/SQL stored procedure, PL/SQL function, PL/SQL package, materialized view, or cache group.Note:
If you try to create a synonym for unsupported object types, you may not be able to use the synonym. -
Naming considerations: A private synonym shares the same namespace as all other object names, such as table names and so on. Therefore, a private synonym cannot have the same name as a table name or other objects in the same schema.
A public synonym is accessible for all users and does not belong to any particular user schema. Therefore, a public synonym can have the same name as a private synonym name or other object name. However, you cannot create a public synonym that has the same name as any objects in the SYS schema.
In the following example, the user creates a private synonym of synjobs for the jobs table. Execute a SELECT statement on both the jobs table and the synjobs synonym to show that selecting from synjobs is the same as selecting from the jobs table. Finally, to display the private synonym, the example executes a SELECT statement on the SYS.USER_SYNONYMS table.
Command> CREATE SYNONYM synjobs FOR jobs; Synonym created. Command> SELECT FIRST 2 * FROM jobs; < AC_ACCOUNT, Public Accountant, 4200, 9000 > < AC_MGR, Accounting Manager, 8200, 16000 > 2 rows found. Command> SELECT FIRST 2 * FROM synjobs; < AC_ACCOUNT, Public Accountant, 4200, 9000 > < AC_MGR, Accounting Manager, 8200, 16000 > 2 rows found. Command> SELECT * FROM sys.user_synonyms; < SYNJOBS, TTUSER, JOBS, <NULL> > 1 row found.
For full details, more examples, and rules on creating or replacing a synonym, see the "CREATE SYNONYM" section in the Oracle TimesTen In-Memory Database SQL Reference.
Dropping synonyms
Use the DROP SYNONYM statement to drop an existing synonym from the database. A user cannot be dropped unless all objects, including synonyms, owned by this user are dropped.
For example, the following drops the public synonym pubemp:
DROP PUBLIC SYNONYM pubemp; Synonym dropped.
In order drop a public synonym or a private synonym in another user's schema, the user must have the appropriate privileges. For full details, more examples, and rules on creating or replacing a synonym, see the "DROP SYNONYM" section in the Oracle TimesTen In-Memory Database SQL Reference.
Synonyms may cause invalidation or recompilation of SQL queries
When a synonym or object is newly created or dropped, some SQL queries and DDL statements may be invalidated or recompiled. The following lists the invalidation and recompilation behavior for SQL queries and DDL statements:
-
All SQL queries that depend on a public synonym are invalidated if you create a private synonym with the same name for one of the following objects:
-
private synonym
-
table
-
view
-
sequence
-
materialized view
-
cache group
-
PL/SQL object including procedures, functions, and packages.
-
-
All SQL queries that depend on a private synonym or schema object are invalidated when a private synonym or schema object is dropped.