1 RDF Semantic Graph Overview
This chapter describes the support in Oracle Spatial and Graph for semantic technologies, specifically Resource Description Framework (RDF) and a subset of the Web Ontology Language (OWL). These capabilities are referred to as the RDF Semantic Graph feature of Oracle Spatial and Graph. This chapter assumes that you are familiar with the major concepts associated with RDF and OWL, such as {subject, predicate, object} triples, URIs, blank nodes, plain and typed literals, and ontologies. This chapter does not explain these concepts in detail, but focuses instead on how the concepts are implemented in Oracle.
-
For an excellent explanation of RDF concepts, see the World Wide Web Consortium (W3C) RDF Primer at
http://www.w3.org/TR/rdf-primer/. -
For information about OWL, see the OWL Web Ontology Language Reference at
http://www.w3.org/TR/owl-ref/.
The PL/SQL subprograms for working with semantic data are in the SEM_APIS package, which is documented in Chapter 11.
The RDF and OWL support are features of Oracle Spatial and Graph, which must be installed for these features to be used. However, the use of RDF and OWL is not restricted to spatial data.
This chapter contains the following major sections:
-
Section 1.1, "Introduction to Oracle Semantic Technologies Support"
-
Section 1.5, "Semantic Data Types, Constructors, and Methods"
-
Section 1.6, "Using the SEM_MATCH Table Function to Query Semantic Data"
-
Section 1.10, "Managing Statistics for Semantic Models and the Semantic Network"
For information about OWL concepts and the Oracle Database support for OWL capabilities, see Chapter 2.
Required Actions to Enable RDF Semantic Graph Support:
Before performing any operations described in this guide, you must enable RDF Semantic Graph support in the database and meet other prerequisites, as explained in Section A.1, "Enabling RDF Semantic Graph Support".1.1 Introduction to Oracle Semantic Technologies Support
Oracle Database enables you to store semantic data and ontologies, to query semantic data and to perform ontology-assisted query of enterprise relational data, and to use supplied or user-defined inferencing to expand the power of querying on semantic data. Figure 1-1 shows how these capabilities interact.
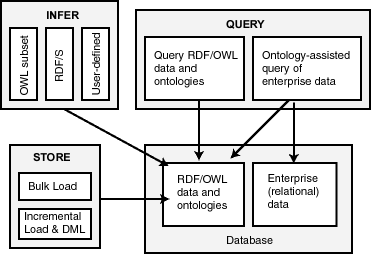
As shown in Figure 1-1, the database contains semantic data and ontologies (RDF/OWL models), as well as traditional relational data. To load semantic data, bulk loading is the most efficient approach, although you can load data incrementally using transactional INSERT statements.
Note:
If you want to use existing semantic data from a release before Oracle Database 11.1, the data must be upgraded as described in Section A.1.You can query semantic data and ontologies, and you can also perform ontology-assisted queries of semantic and traditional relational data to find semantic relationships. To perform ontology-assisted queries, use the SEM_RELATED operator, which is described in Section 2.3.
You can expand the power of queries on semantic data by using inferencing, which uses rules in rulebases. Inferencing enables you to make logical deductions based on the data and the rules. For information about using rules and rulebases for inferencing, see Section 1.3.6.
1.2 Semantic Data Modeling
In addition to its formal semantics, semantic data has a simple data structure that is effectively modeled using a directed graph. The metadata statements are represented as triples: nodes are used to represent two parts of the triple, and the third part is represented by a directed link that describes the relationship between the nodes. The triples are stored in a semantic data network. In addition, information is maintained about specific semantic data models created by database users. A user-created model has a model name, and refers to triples stored in a specified table column.
Statements are expressed in triples: {subject or resource, predicate or property, object or value}. In this manual, {subject, property, object} is used to describe a triple, and the terms statement and triple may sometimes be used interchangeably. Each triple is a complete and unique fact about a specific domain, and can be represented by a link in a directed graph.
1.3 Semantic Data in the Database
There is one universe for all semantic data stored in the database. All triples are parsed and stored in the system as entries in tables under the MDSYS schema. A triple {subject, property, object} is treated as one database object. As a result, a single document containing multiple triples results in multiple database objects.
All the subjects and objects of triples are mapped to nodes in a semantic data network, and properties are mapped to network links that have their start node and end node as subject and object, respectively. The possible node types are blank nodes, URIs, plain literals, and typed literals.
The following requirements apply to the specifications of URIs and the storage of semantic data in the database:
-
A subject must be a URI or a blank node.
-
A property must be a URI.
-
An object can be any type, such as a URI, a blank node, or a literal. (However, null values and null strings are not supported.)
1.3.1 Metadata for Models
The MDSYS.SEM_MODEL$ view contains information about all models defined in the database. When you create a model using the SEM_APIS.CREATE_SEM_MODEL procedure, you specify a name for the model, as well as a table and column to hold references to the semantic data, and the system automatically generates a model ID.
Oracle maintains the MDSYS.SEM_MODEL$ view automatically when you create and drop models. Users should never modify this view directly. For example, do not use SQL INSERT, UPDATE, or DELETE statements with this view.
The MDSYS.SEM_MODEL$ view contains the columns shown in Table 1-1.
Table 1-1 MDSYS.SEM_MODEL$ View Columns
| Column Name | Data Type | Description |
|---|---|---|
|
OWNER |
VARCHAR2(30) |
Schema of the owner of the model. |
|
MODEL_ID |
NUMBER |
Unique model ID number, automatically generated. |
|
MODEL_NAME |
VARCHAR2(25) |
Name of the model. |
|
TABLE_NAME |
VARCHAR2(30) |
Name of the table to hold references to semantic data for the model. |
|
COLUMN_NAME |
VARCHAR2(30) |
Name of the column of type SDO_RDF_TRIPLE_S in the table to hold references to semantic data for the model. |
|
MODEL_TABLESPACE_NAME |
VARCHAR2(30) |
Name of the tablespace to be used for storing the triples for this model. |
|
MODEL_TYPE |
VARCHAR2(40) |
A value indicating the type of RDF model: |
When you create a model, a view for the triples associated with the model is also created under the MDSYS schema. This view has a name in the format SEMM_model-name, and it is visible only to the owner of the model and to users with suitable privileges. Each MDSYS.SEMM_model-name view contains a row for each triple (stored as a link in a network), and it has the columns shown in Table 1-2.
Table 1-2 MDSYS.SEMM_model-name View Columns
| Column Name | Data Type | Description |
|---|---|---|
|
P_VALUE_ID |
NUMBER |
The VALUE_ID for the text value of the predicate of the triple. Part of the primary key. |
|
START_NODE_ID |
NUMBER |
The VALUE_ID for the text value of the subject of the triple. Also part of the primary key. |
|
CANON_END_NODE_ID |
NUMBER |
The VALUE_ID for the text value of the canonical form of the object of the triple. Also part of the primary key. |
|
END_NODE_ID |
NUMBER |
The VALUE_ID for the text value of the object of the triple |
|
MODEL_ID |
NUMBER |
The ID for the RDF model to which the triple belongs. |
|
COST |
NUMBER |
(Reserved for future use) |
|
CTXT1 |
NUMBER |
(Reserved column; can be used for fine-grained access control) |
|
CTXT2 |
VARCHAR2(4000) |
(Reserved for future use) |
|
DISTANCE |
NUMBER |
(Reserved for future use) |
|
EXPLAIN |
VARCHAR2(4000) |
(Reserved for future use) |
|
PATH |
VARCHAR2(4000) |
(Reserved for future use) |
|
G_ID |
NUMBER |
The VALUE_ID for the text value of the graph name for the triple. Null indicates the default graph (see Section 1.3.9, "Named Graphs"). |
|
LINK_ID |
VARCHAR2(71) |
Unique triple identifier value. (It is currently a computed column, and its definition may change in a future release.) |
Note:
In Table 1-2, for columns P_VALUE_ID, START_NODE_ID, END_NODE_ID, CANON_END_NODE_ID, and G_ID, the actual ID values are computed from the corresponding lexical values. However, a lexical value may not always map to the same ID value.1.3.2 Statements
The MDSYS.RDF_VALUE$ table contains information about the subjects, properties, and objects used to represent RDF statements. It uniquely stores the text values (URIs or literals) for these three pieces of information, using a separate row for each part of each triple.
Oracle maintains the MDSYS.RDF_VALUE$ table automatically. Users should never modify this view directly. For example, do not use SQL INSERT, UPDATE, or DELETE statements with this view.
The RDF_VALUE$ table contains the columns shown in Table 1-3.
Table 1-3 MDSYS.RDF_VALUE$ Table Columns
| Column Name | Data Type | Description |
|---|---|---|
|
VALUE_ID |
NUMBER |
Unique value ID number, automatically generated. |
|
VALUE_TYPE |
VARCHAR2(10) |
The type of text information stored in the VALUE_NAME column. Possible values: |
|
VNAME_PREFIX |
VARCHAR2(4000) |
If the length of the lexical value is 4000 bytes or less, this column stores a prefix of a portion of the lexical value. The SEM_APIS.VALUE_NAME_PREFIX function can be used for prefix computation. For example, the prefix for the portion of the lexical value |
|
VNAME_SUFFIX |
VARCHAR2(512) |
If the length of the lexical value is 4000 bytes or less, this column stores a suffix of a portion of the lexical value. The SEM_APIS.VALUE_NAME_SUFFIX function can be used for suffix computation. For the lexical value mentioned in the description of the VNAME_PREFIX column, the suffix is |
|
LITERAL_TYPE |
VARCHAR2(4000) |
For typed literals, the type information; otherwise, null. For example, for a row representing a creation date of 1999-08-16, the VALUE_TYPE column can contain |
|
LANGUAGE_TYPE |
VARCHAR2(80) |
Language tag (for example, |
|
CANON_ID |
NUMBER |
The ID for the canonical lexical value for the current lexical value. (The use of this column may change in a future release.) |
|
COLLISION_EXT |
VARCHAR2(64) |
Used for collision handling for the lexical value. (The use of this column may change in a future release.) |
|
CANON_COLLISION_EXT |
VARCHAR2(64) |
Used for collision handling for the canonical lexical value. (The use of this column may change in a future release.) |
|
LONG_VALUE |
CLOB |
The character string if the length of the lexical value is greater than 4000 bytes. Otherwise, this column has a null value. |
|
VALUE_NAME |
VARCHAR2(4000) |
This is a computed column. If length of the lexical value is 4000 bytes or less, the value of this column is the concatenation of the values of VNAME_PREFIX column and the VNAME_SUFFIX column. |
1.3.2.1 Triple Uniqueness and Data Types for Literals
Duplicate triples are not stored in the database. To check if a triple is a duplicate of an existing triple, the subject, property, and object of the incoming triple are checked against triple values in the specified model. If the incoming subject, property, and object are all URIs, an exact match of their values determines a duplicate. However, if the object of incoming triple is a literal, an exact match of the subject and property, and a value (canonical) match of the object, determine a duplicate. For example, the following two triples are duplicates:
<eg:a> <eg:b> <"123"^^http://www.w3.org/2001/XMLSchema#int> <eg:a> <eg:b> <"123"^^http://www.w3.org/2001/XMLSchema#unsignedByte>
The second triple is treated as a duplicate of the first, because "123"^^<http://www.w3.org/2001/XMLSchema#int> has an equivalent value (is canonically equivalent) to "123"^^<http://www.w3.org/2001/XMLSchema#unsignedByte>. Two entities are canonically equivalent if they can be reduced to the same value.
To use a non-RDF example, A*(B-C), A*B-C*A, (B-C)*A, and -A*C+A*B all convert into the same canonical form.
Note:
Although duplicate triples and quads are not stored in the underlying table partition for the MDSYS.RDFM_<model> view, it is possible to have duplicate rows in an application table. For example, if a triple is inserted multiple times into an application table, it will appear once in the MDSYS.RDFM_<model> view, but will occupy multiple rows in the application table.Value-based matching of lexical forms is supported for the following data types:
-
STRING: plain literal, xsd:string and some of its XML Schema subtypes
-
NUMERIC: xsd:decimal and its XML Schema subtypes, xsd:float, and xsd:double. (Support is not provided for float/double INF, -INF, and NaN values.)
-
DATETIME: xsd:datetime, with support for time zone. (Without time zone there are still multiple representations for a single value, for example,
"2004-02-18T15:12:54"and"2004-02-18T15:12:54.0000".) -
DATE: xsd:date, with or without time zone
-
OTHER: Everything else. (No attempt is made to match different representations).
Canonicalization is performed when the time zone is present for literals of type xsd:time and xsd:dateTime.
The following namespace definition is used: xmlns:xsd="http://www.w3.org/2001/XMLSchema"
The first occurrence of a literal in the RDF_VALUE$ table is taken as the canonical form and given the VALUE_TYPE value of CPL, CPL@, CTL, CPLL, CPLL@, or CTLL as appropriate; that is, a C for canonical is prefixed to the actual value type. If a literal with the same canonical form (but a different lexical representation) as a previously inserted literal is inserted into the RDF_VALUE$ table, the VALUE_TYPE value assigned to the new insert is PL, PL@, TL, PLL, PLL@, or TLL as appropriate.
Canonically equivalent text values having different lexical representations are thus stored in the RDF_VALUE$ table; however, canonically equivalent triples are not stored in the database.
1.3.3 Subjects and Objects
RDF subjects and objects are mapped to nodes in a semantic data network. Subject nodes are the start nodes of links, and object nodes are the end nodes of links. Non-literal nodes (that is, URIs and blank nodes) can be used as both subject and object nodes. Literals can be used only as object nodes.
1.3.4 Blank Nodes
Blank nodes can be used as subject and object nodes in the semantic network. Blank node identifiers are different from URIs in that they are scoped within a semantic model. Thus, although multiple occurrences of the same blank node identifier within a single semantic model necessarily refer to the same resource, occurrences of the same blank node identifier in two different semantic models do not refer to the same resource.
In an Oracle semantic network, this behavior is modeled by requiring that blank nodes are always reused (that is, are used to represent the same resource if the same blank node identifier is used) within a semantic model, and never reused between two different models. Thus, when inserting triples involving blank nodes into a model, you must use the SDO_RDF_TRIPLE_S constructor that supports reuse of blank nodes.
1.3.5 Properties
Properties are mapped to links that have their start node and end node as subjects and objects, respectively. Therefore, a link represents a complete triple.
When a triple is inserted into a model, the subject, property, and object text values are checked to see if they already exist in the database. If they already exist (due to previous statements in other models), no new entries are made; if they do not exist, three new rows are inserted into the RDF_VALUE$ table (described in Section 1.3.2).
1.3.6 Inferencing: Rules and Rulebases
Inferencing is the ability to make logical deductions based on rules. Inferencing enables you to construct queries that perform semantic matching based on meaningful relationships among pieces of data, as opposed to just syntactic matching based on string or other values. Inferencing involves the use of rules, either supplied by Oracle or user-defined, placed in rulebases.
Figure 1-2 shows triple sets being inferred from model data and the application of rules in one or more rulebases. In this illustration, the database can have any number of semantic models, rulebases, and inferred triple sets, and an inferred triple set can be derived using rules in one or more rulebases.
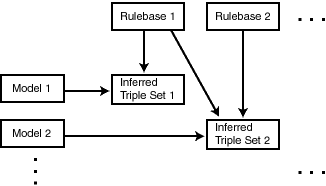
A rule is an object that can be applied to draw inferences from semantic data. A rule is identified by a name and consists of:
-
An IF side pattern for the antecedents
-
An optional filter condition that further restricts the subgraphs matched by the IF side pattern
-
A THEN side pattern for the consequents
For example, the rule that a chairperson of a conference is also a reviewer of the conference could be represented as follows:
('chairpersonRule', -- rule name
'(?r :ChairPersonOf ?c)', -- IF side pattern
NULL, -- filter condition
'(?r :ReviewerOf ?c)', -- THEN side pattern
SEM_ALIASES (SEM_ALIAS('', 'http://some.org/test/'))
)
In this case, the rule does not have a filter condition, so that component of the representation is NULL. For best performance, use a single-triple pattern on the THEN side of the rule. If a rule has multiple triple patterns on the THEN side, you can easily break it into multiple rules, each with a single-triple pattern, on the THEN side.
A rulebase is an object that contains rules. The following Oracle-supplied rulebases are provided:
-
RDFS
-
RDF (a subset of RDFS)
-
OWLSIF (empty)
-
RDFS++ (empty)
-
OWL2RL (empty)
-
OWLPrime (empty)
-
SKOSCORE (empty)
The RDFS and RDF rulebases are created when you call the SEM_APIS.CREATE_SEM_NETWORK procedure to add RDF support to the database. The RDFS rulebase implements the RDFS entailment rules, as described in the World Wide Web Consortium (W3C) RDF Semantics document at http://www.w3.org/TR/rdf-mt/. The RDF rulebase represents the RDF entailment rules, which are a subset of the RDFS entailment rules. You can see the contents of these rulebases by examining the MDSYS.SEMR_RDFS and MDSYS.SEMR_RDF views.
You can also create user-defined rulebases using the SEM_APIS.CREATE_RULEBASE procedure. User-defined rulebases enable you to provide additional specialized inferencing capabilities.
For each rulebase, a system table is created to hold rules in the rulebase, along with a system view with a name in the format MDSYS.SEMR_rulebase-name (for example, MDSYS.SEMR_FAMILY_RB for a rulebase named FAMILY_RB). You must use this view to insert, delete, and modify rules in the rulebase. Each MDSYS.SEMR_rulebase-name view has the columns shown in Table 1-4.
Table 1-4 MDSYS.SEMR_rulebase-name View Columns
| Column Name | Data Type | Description |
|---|---|---|
|
RULE_NAME |
VARCHAR2(30) |
Name of the rule |
|
ANTECEDENTS |
VARCHAR2(4000) |
IF side pattern for the antecedents |
|
FILTER |
VARCHAR2(4000) |
Filter condition that further restricts the subgraphs matched by the IF side pattern. Null indicates no filter condition is to be applied. |
|
CONSEQUENTS |
VARCHAR2(4000) |
THEN side pattern for the consequents |
|
ALIASES |
SEM_ALIASES |
One or more namespaces to be used. (The SEM_ALIASES data type is described in Section 1.6.) |
Information about all rulebases is maintained in the MDSYS.SEM_RULEBASE_INFO view, which has the columns shown in Table 1-5 and one row for each rulebase.
Table 1-5 MDSYS.SEM_RULEBASE_INFO View Columns
| Column Name | Data Type | Description |
|---|---|---|
|
OWNER |
VARCHAR2(30) |
Owner of the rulebase |
|
RULEBASE_NAME |
VARCHAR2(25) |
Name of the rulebase |
|
RULEBASE_VIEW_NAME |
VARCHAR2(30) |
Name of the view that you must use for any SQL statements that insert, delete, or modify rules in the rulebase |
|
STATUS |
VARCHAR2(30) |
Contains |
Example 1-1 creates a rulebase named family_rb, and then inserts a rule named grandparent_rule into the family_rb rulebase. This rule says that if a person is the parent of a child who is the parent of a child, that person is a grandparent of (that is, has the grandParentOf relationship with respect to) his or her child's child. It also specifies a namespace to be used. (This example is an excerpt from Example 1-89 in Section 1.12.2.)
Example 1-1 Inserting a Rule into a Rulebase
EXECUTE SEM_APIS.CREATE_RULEBASE('family_rb');
INSERT INTO mdsys.semr_family_rb VALUES(
'grandparent_rule',
'(?x :parentOf ?y) (?y :parentOf ?z)',
NULL,
'(?x :grandParentOf ?z)',
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')));
Note that the kind of grandparent rule shown in Example 1-1 can be implemented using the OWL 2 property chain construct. For information about property chain handling, see Section 3.2.2.
You can specify one or more rulebases when calling the SEM_MATCH table function (described in Section 1.6), to control the behavior of queries against semantic data. Example 1-2 refers to the family_rb rulebase and to the grandParentOf relationship created in Example 1-1, to find all grandfathers (grandparents who are male) and their grandchildren. (This example is an excerpt from Example 1-89 in Section 1.12.2.)
Example 1-2 Using Rulebases for Inferencing
-- Select all grandfathers and their grandchildren from the family model.
-- Use inferencing from both the RDFS and family_rb rulebases.
SELECT x, y
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male}',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
For information about support for native OWL inferencing, see Section 2.2.
1.3.7 Entailments (Rules Indexes)
An entailment (rules index) is an object containing precomputed triples that can be inferred from applying a specified set of rulebases to a specified set of models. If a SEM_MATCH query refers to any rulebases, an entailment must exist for each rulebase-model combination in the query.
To create an entailment, use the SEM_APIS.CREATE_ENTAILMENT procedure. To drop (delete) an entailment, use the SEM_APIS.DROP_ENTAILMENT procedure.
When you create an entailment, a view for the triples associated with the entailment is also created under the MDSYS schema. This view has a name in the format SEMI_entailment-name, and it is visible only to the owner of the entailment and to users with suitable privileges. Each MDSYS.SEMI_entailment-name view contains a row for each triple (stored as a link in a network), and it has the same columns as the SEMM_model-name view, which is described in Table 1-2 in Section 1.3.1.
Information about all entailments is maintained in the MDSYS.SEM_RULES_INDEX_INFO view, which has the columns shown in Table 1-6 and one row for each entailment.
Table 1-6 MDSYS.SEM_RULES_INDEX_INFO View Columns
| Column Name | Data Type | Description |
|---|---|---|
|
OWNER |
VARCHAR2(30) |
Owner of the entailment |
|
INDEX_NAME |
VARCHAR2(25) |
Name of the entailment |
|
INDEX_VIEW_NAME |
VARCHAR2(30) |
Name of the view that you must use for any SQL statements that insert, delete, or modify rules in the entailment |
|
STATUS |
VARCHAR2(30) |
Contains |
|
MODEL_COUNT |
NUMBER |
Number of models included in the entailment |
|
RULEBASE_COUNT |
NUMBER |
Number of rulebases included in the entailment |
Information about all database objects, such as models and rulebases, related to entailments is maintained in the MDSYS.SEM_RULES_INDEX_DATASETS view. This view has the columns shown in Table 1-7 and one row for each unique combination of values of all the columns.
Table 1-7 MDSYS.SEM_RULES_INDEX_DATASETS View Columns
| Column Name | Data Type | Description |
|---|---|---|
|
INDEX_NAME |
VARCHAR2(25) |
Name of the entailment |
|
DATA_TYPE |
VARCHAR2(8) |
Type of data included in the entailment. Examples: |
|
DATA_NAME |
VARCHAR2(25) |
Name of the object of the type in the DATA_TYPE column |
Example 1-3 creates an entailment named family_rb_rix_family, using the family model and the RDFS and family_rb rulebases. (This example is an excerpt from Example 1-89 in Section 1.12.2.)
1.3.8 Virtual Models
A virtual model is a logical graph that can be used in a SEM_MATCH query. A virtual model is the result of a UNION or UNION ALL operation on one or more models and/or entailments.
Using a virtual model can provide several benefits:
-
It can simplify management of access privileges for semantic data. For example, assume that you have created three semantic models and one entailment based on the three models and the OWLPrime rulebase. Without a virtual model, you must individually grant and revoke access privileges for each model and the entailment. However, if you create a virtual model that contains the three models and the entailment, you will only need to grant and revoke access privileges for the single virtual model.
-
It can facilitate rapid updates to semantic models. For example, assume that virtual model VM1 contains model M1 and entailment R1 (that is, VM1 = M1 UNION ALL R1), and assume that semantic model M1_UPD is a copy of M1 that has been updated with additional triples and that R1_UPD is an entailment created for M1_UPD. Now, to have user queries over VM1 go to the updated model and entailment, you can redefine virtual model VM1 (that is, VM1 = M1_UPD UNION ALL R1_UPD).
-
It can simplify query specification because querying a virtual model is equivalent to querying multiple models in a SEM_MATCH query. For example, assume that models m1, m2, and m3 already exist, and that an entailment has been created for m1, m2 ,and m3 using the OWLPrime rulebase. You could create a virtual model vm1 as follows:
EXECUTE sem_apis.create_virtual_model('vm1', sem_models('m1', 'm2', 'm3'), sem_rulebases('OWLPRIME'));To query the virtual model, use the virtual model name as if it were a model in a SEM_MATCH query. For example, the following query on the virtual model:
SELECT * FROM TABLE (sem_match('{…}', sem_models('vm1'), null, …));is equivalent to the following query on all the individual models:
SELECT * FROM TABLE (sem_match('{…}', sem_models('m1', 'm2', 'm3'), sem_rulebases('OWLPRIME'), …));A SEM_MATCH query over a virtual model will query either the SEMV or SEMU view (SEMU by default and SEMV if the 'ALLOW_DUP=T' option is specified) rather than querying the UNION or UNION ALL of each model and entailment. For information about these views and options, see the reference section for the SEM_APIS.CREATE_VIRTUAL_MODEL procedure.
You cannot use Oracle Workspace Manager version-enabling on a model that participates in a virtual model. (Workspace Manager support for RDF data is described in Chapter 6.)
Virtual models use views (described later in this section) and add some metadata entries, but do not significantly increase system storage requirements.
To create a virtual model, use the SEM_APIS.CREATE_VIRTUAL_MODEL procedure. To drop (delete) a virtual model, use the SEM_APIS.DROP_VIRTUAL_MODEL procedure. A virtual model is dropped automatically if any of its component models, rulebases, or entailment are dropped. To replace a virtual model without dropping it, use the SEM_APIS.CREATE_VIRTUAL_MODEL procedure with the REPLACE=T option. Replacing a virtual model allows you to redefine it while maintaining any access privileges.
To query a virtual model, specify the virtual model name in the models parameter of the SEM_MATCH table function, as shown in Example 1-4.
Example 1-4 Querying a Virtual Model
SELECT COUNT(protein)
FROM TABLE (SEM_MATCH (
'{?protein rdf:type :Protein .
?protein :citation ?citation .
?citation :author "Bairoch A."}',
SEM_MODELS('UNIPROT_VM'),
NULL,
SEM_ALIASES(SEM_ALIAS('', 'http://purl.uniprot.org/core/')),
NULL,
NULL,
'ALLOW_DUP=T'));
For information about the SEM_MATCH table function, see Section 1.6, which includes information using certain attributes when querying a virtual model.
When you create a virtual model, an entry is created for it in the MDSYS.SEM_MODEL$ view, which is described in Table 1-1 in Section 1.3.1. However, the values in several of the columns are different for virtual models as opposed to semantic models, as explained in Table 1-8.
Table 1-8 MDSYS.SEM_MODEL$ View Column Explanations for Virtual Models
| Column Name | Data Type | Description |
|---|---|---|
|
OWNER |
VARCHAR2(30) |
Schema of the owner of the virtual model |
|
MODEL_ID |
NUMBER |
Unique model ID number, automatically generated. Will be a negative number, to indicate that this is a virtual model. |
|
MODEL_NAME |
VARCHAR2(25) |
Name of the virtual model |
|
TABLE_NAME |
VARCHAR2(30) |
Null for a virtual model |
|
COLUMN_NAME |
VARCHAR2(30) |
Null for a virtual model |
|
MODEL_TABLESPACE_NAME |
VARCHAR2(30) |
Null for a virtual model |
Information about all virtual models is maintained in the MDSYS.SEM_VMODEL_INFO view, which has the columns shown in Table 1-9 and one row for each virtual model.
Table 1-9 MDSYS.SEM_VMODEL_INFO View Columns
| Column Name | Data Type | Description |
|---|---|---|
|
OWNER |
VARCHAR2(30) |
Owner of the virtual model |
|
VIRTUAL_MODEL_NAME |
VARCHAR2(25) |
Name of the virtual model |
|
UNIQUE_VIEW_NAME |
VARCHAR2(30) |
Name of the view that contains unique triples in the virtual model, or null if the view was not created |
|
DUPLICATE_VIEW_NAME |
VARCHAR2(30) |
Name of the view that contains duplicate triples (if any) in the virtual model |
|
STATUS |
VARCHAR2(30) |
Contains In the case of multiple entailments, the lowest status among all of the component entailments is used as the virtual model's status ( |
|
MODEL_COUNT |
NUMBER |
Number of models in the virtual model |
|
RULEBASE_COUNT |
NUMBER |
Number of rulebases used for the virtual model |
|
RULES_INDEX_COUNT |
NUMBER |
Number of entailments in the virtual model |
Information about all objects (models, rulebases, and entailments) related to virtual models is maintained in the MDSYS.SEM_VMODEL_DATASETS view. This view has the columns shown in Table 1-10 and one row for each unique combination of values of all the columns.
Table 1-10 MDSYS.SEM_VMODEL_DATASETS View Columns
| Column Name | Data Type | Description |
|---|---|---|
|
VIRTUAL_MODEL_NAME |
VARCHAR2(25) |
Name of the virtual model |
|
DATA_TYPE |
VARCHAR2(8) |
Type of object included in the virtual model. Examples: |
|
DATA_NAME |
VARCHAR2(25) |
Name of the object of the type in the DATA_TYPE column |
1.3.9 Named Graphs
RDF Semantic Graph supports the use of named graphs, which are described in the "RDF Dataset" section of the W3C SPARQL Query Language for RDF recommendation (http://www.w3.org/TR/rdf-sparql-query/#rdfDataset).
This support is provided by extending an RDF triple consisting of the traditional subject, predicate, and object, to include an additional component to represent a graph name. The extended RDF triple, despite having four components, will continue to be referred to as an RDF triple in this document. In addition, the following terms are sometimes used:
-
N-Triple is a format that does not allow extended triples. Thus, n-triples can include only triples with three components.
-
N-Quad is a format that allows both "regular" triples (three components) and extended triples (four components, including the graph name). For more information, see
http://www.w3.org/TR/2013/NOTE-n-quads-20130409/.To load a file containing extended triples (possibly mixed with regular triples) into an Oracle database, the input file must be in N-Quad format.
The graph name component of an RDF triple must either be null or a URI. If it is null, the RDF triple is said to belong to a default graph; otherwise it is said to belong to a named graph whose name is designated by the URI.
Additionally, to support named graphs in SDO_RDF_TRIPLE_S object type (described in Section 1.5), a new syntax is provided for specifying a model-graph, that is, a combination of model and graph (if any) together, and the RDF_M_ID attribute holds the identifier for a model-graph: a combination of model ID and value ID for the graph (if any). The name of a model-graph is specified as model_name, and if a graph is present, followed by the colon (:) separator character and the graph name (which must be a URI and enclosed within angle brackets < >).
For example, in a medical data set the named graph component for each RDF triple might be a URI based on patient identifier, so there could be as many named graphs as there are unique patients, with each named graph consisting of data for a specific patient.
For information about performing specific operations with named graphs, see the following:
-
Using constructors and methods: Section 1.5, "Semantic Data Types, Constructors, and Methods"
-
Loading: Section 1.7.1.1.2, "Loading N-Quad Format Data into a Staging Table Using an External Table" and Section 1.7.3.1, "Loading Data into Named Graphs Using INSERT Statements"
-
Querying: Section 1.6.2.1, "GRAPH Keyword Support" and Section 1.6.7.1, "Expressions in the SELECT Clause"
-
Inferencing: Section 2.2.11, "Using Named Graph Based Inferencing (Global and Local)"
1.3.9.1 Data Formats Related to Named Graph Support
TriG (http://wifo5-03.informatik.uni-mannheim.de/bizer/trig/) and N-QUADS (http://www.w3.org/TR/2013/NOTE-n-quads-20130409/) are two popular data formats that provide graph names (or context) to triple data. (As of November 2011, neither format was a standard.) The graph names (context) can be used in a variety of different ways. Typical usage includes, but is not limited to, the grouping of triples for ease of management, localized query, localized inference, and provenance.
Example 1-5 shows an RDF data set encoded in TriG format. It contains a default graph and a named graph.
Example 1-5 RDF Data Encoded in TriG Format
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix dc: <http://purl.org/dc/elements/1.1/> .
# Default graph
{
<http://my.com/John> dc:publisher <http://publisher/Xyz> .
}
# A named graph
<http://my.com/John> {
<http://my.com/John> foaf:name "John Doe" .
}
When loading the TriG file from Example 1-5 into a DatasetGraphOracleSem object (for example, using Example 7-13 in Section 7.12, "Bulk Loading Using RDF Semantic Graph Support for Apache Jena", but replacing the constant "N-QUADS" with "TRIG"), the triples in the default graph will be loaded into Oracle Database as triples with null graph names, and the triples in the named graphs will be loaded into Oracle Database with the designated graph names.
N-QUADS format is a simple extension of the existing N-TRIPLES format by adding an optional fourth column (graph name or context). Example 1-6 shows the N-QUADS format representation of the TriG file from Example 1-5.
Example 1-6 N-QUADS Format Representation
<http://my.com/John> <http://purl.org/dc/elements/1.1/publisher> <http://publisher/Xyz> . <http://my.com/John> <http://xmlns.com/foaf/0.1/name> "John Doe" <http://my.com/John>
When loading an N-QUADS file into a DatasetGraphOracleSem object (see Example 7-13), lines without the fourth column will be loaded into Oracle Database as triples with null graph names, and lines with a fourth column will be loaded into Oracle Database with the designated graph names.
1.3.10 Semantic Data Security Considerations
The following database security considerations apply to the use of semantic data:
-
When a model or entailment is created, the owner gets the SELECT privilege with the GRANT option on the associated view. Users that have the SELECT privilege on these views can perform SEM_MATCH queries against the associated model or entailment.
-
When a rulebase is created, the owner gets the SELECT, INSERT, UPDATE, and DELETE privileges on the rulebase, with the GRANT option. Users that have the SELECT privilege on a rulebase can create an entailment that includes the rulebase. The INSERT, UPDATE, and DELETE privileges control which users can modify the rulebase and how they can modify it.
-
To perform data manipulation language (DML) operations on a model, a user must have DML privileges for the corresponding base table.
-
The creator of the base table corresponding to a model can grant privileges to other users.
-
To perform data manipulation language (DML) operations on a rulebase, a user must have the appropriate privileges on the corresponding database view.
-
The creator of a model can grant SELECT privileges on the corresponding database view to other users.
-
A user can query only those models for which that user has SELECT privileges to the corresponding database views.
-
Only the creator of a model or a rulebase can drop it.
1.4 Semantic Metadata Tables and Views
Oracle Database maintains several tables and views in the MDSYS schema to hold metadata related to semantic data. (Some of these tables and views are created by the SEM_APIS.CREATE_SEM_NETWORK procedure, as explained in Section 1.11, and some are created only as needed.) Table 1-11 lists the tables and views in alphabetical order. (In addition, several tables and views are created for Oracle internal use, and these are accessible only by users with DBA privileges.)
Table 1-11 Semantic Metadata Tables and Views
| Name | Contains Information About | Described In |
|---|---|---|
|
RDF_VALUE$ |
Subjects, properties, and objects used to represent statements |
|
|
RDFOLS_SECURE_RESOURCE |
Resources secured with Oracle Label Security (OLS) policies and the sensitivity labels associated with these resources |
|
|
RDFVPD_MODELS |
RDF models and their associated VPD policies |
|
|
RDFVPD_POLICIES |
All VPD policies defined in the schema or the policies to which the user has FULL access |
|
|
RDFVPD_POLICY_CONSTRAINTS |
Constraints defined in the VPD policy that are accessible to the current user |
|
|
RDFVPD_PREDICATE_MDATA |
Predicate metadata associated with a VPD policy |
|
|
RDFVPD_RESOURCE_REL |
Subclass, subproperty, and equivalence property relationships that are defined between resources in a VPD policy |
|
|
SEM_DTYPE_INDEX_INFO |
All data type indexes in the network |
|
|
SEM_MODEL$ |
All models defined in the database |
|
|
SEM_NETWORK_INDEX_INFO$ |
Semantic network indexes |
|
|
SEM_RULEBASE_INFO |
Rulebases |
|
|
SEM_RULES_INDEX_DATASETS |
Database objects used in entailments |
|
|
SEM_RULES_INDEX_INFO |
Entailments (rules indexes) |
|
|
SEM_VMODEL_INFO |
Virtual models |
|
|
SEM_VMODEL_DATASETS |
Database objects used in virtual models |
|
|
SEMCL_entailment-name |
|
|
|
SEMI_entailment-name |
Triples in the specified entailment |
|
|
SEMM_model-name |
Triples in the specified model |
|
|
SEMR_rulebase-name |
Rules in the specified rulebase |
|
|
SEMU_virtual-model-name |
Unique triples in the virtual model |
|
|
SEMV_virtual-model-name |
Triples in the virtual model |
1.5 Semantic Data Types, Constructors, and Methods
The SDO_RDF_TRIPLE object type represents semantic data in triple format, and the SDO_RDF_TRIPLE_S object type (the _S for storage) stores persistent semantic data in the database. The SDO_RDF_TRIPLE_S type has references to the data, because the actual semantic data is stored only in the central RDF schema. This type has methods to retrieve the entire triple or part of the triple.
Note:
Blank nodes are always reused within an RDF model and cannot be reused across modelsThe SDO_RDF_TRIPLE type is used to display triples, whereas the SDO_RDF_TRIPLE_S type is used to store the triples in database tables.
The SDO_RDF_TRIPLE object type has the following attributes:
SDO_RDF_TRIPLE ( subject VARCHAR2(4000), property VARCHAR2(4000), object VARCHAR2(10000))
The SDO_RDF_TRIPLE_S object type has the following attributes:
SDO_RDF_TRIPLE_S ( RDF_C_ID NUMBER, -- Canonical object value ID RDF_M_ID NUMBER, -- Model (or Model-Graph) ID RDF_S_ID NUMBER, -- Subject value ID RDF_P_ID NUMBER, -- Property value ID RDF_O_ID NUMBER) -- Object value ID
The SDO_RDF_TRIPLE_S type has the following methods that retrieve the name of the RDF model (or model-graph), a triple, or a part (subject, property, or object) of a triple:
GET_MODEL() RETURNS VARCHAR2 GET_TRIPLE() RETURNS SDO_RDF_TRIPLE GET_SUBJECT() RETURNS VARCHAR2 GET_PROPERTY() RETURNS VARCHAR2 GET_OBJECT() RETURNS CLOB
Example 1-7 shows the SDO_RDF_TRIPLE_S methods.
Example 1-7 SDO_RDF_TRIPLE_S Methods
SELECT a.triple.GET_MODEL() AS model_graph, a.triple.GET_TRIPLE() AS triple FROM articles_rdf_data a WHERE a.id = 99; MODEL_GRAPH -------------------------------------------------------------------------------- TRIPLE(SUBJECT, PROPERTY, OBJECT) -------------------------------------------------------------------------------- ARTICLES:<http://examples.com/ns#Graph1> SDO_RDF_TRIPLE('<http://nature.example.com/Article101>', '<http://purl.org/dc/elements/1.1/creator>', '"John Smith"') SELECT a.triple.GET_TRIPLE() AS triple FROM articles_rdf_data a WHERE a.id = 1; TRIPLE(SUBJECT, PROPERTY, OBJECT) -------------------------------------------------------------------------------- SDO_RDF_TRIPLE('<http://nature.example.com/Article1>', '<http://purl.org/dc/elem ents/1.1/title>', '<All about XYZ>') SELECT a.triple.GET_SUBJECT() AS subject FROM articles_rdf_data a WHERE a.id = 1; SUBJECT -------------------------------------------------------------------------------- <http://nature.example.com/Article1> SELECT a.triple.GET_PROPERTY() AS property FROM articles_rdf_data a WHERE a.id = 1; PROPERTY -------------------------------------------------------------------------------- <http://purl.org/dc/elements/1.1/title> SELECT a.triple.GET_OBJECT() AS object FROM articles_rdf_data a WHERE a.id = 1; OBJECT -------------------------------------------------------------------------------- <All about XYZ>
1.5.1 Constructors for Inserting Triples
The following constructor formats are available for inserting triples into a model table. The only difference is that in the second format the data type for the object is CLOB, to accommodate very long literals.
SDO_RDF_TRIPLE_S ( model_name VARCHAR2, -- Model name subject VARCHAR2, -- Subject property VARCHAR2, -- Property object VARCHAR2) -- Object RETURN SELF; SDO_RDF_TRIPLE_S ( model_name VARCHAR2, -- Model name subject VARCHAR2, -- Subject property VARCHAR2, -- Property object CLOB) -- Object RETURN SELF; GET_OBJ_VALUE() RETURN VARCHAR2;
Example 1-8 uses the first constructor format to insert several triples.
Example 1-8 SDO_RDF_TRIPLE_S Constructor to Insert Triples
INSERT INTO articles_rdf_data VALUES (2,
SDO_RDF_TRIPLE_S ('articles','<http://nature.example.com/Article1>',
'<http://purl.org/dc/elements/1.1/creator>',
'"Jane Smith"'));
INSERT INTO articles_rdf_data VALUES (98,
SDO_RDF_TRIPLE_S ('articles:<http://examples.com/ns#Graph1>',
'<http://nature.example.com/Article102>',
'<http://purl.org/dc/elements/1.1/creator>',
'_:b1'));
INSERT INTO articles_rdf_data VALUES (97,
SDO_RDF_TRIPLE_S ('articles:<http://examples.com/ns#Graph1>',
'_:b2',
'<http://purl.org/dc/elements/1.1/creator>',
'_:b1'));
1.6 Using the SEM_MATCH Table Function to Query Semantic Data
To query semantic data, use the SEM_MATCH table function. This function has the following attributes:
SEM_MATCH( query VARCHAR2, models SEM_MODELS, rulebases SEM_RULEBASES, aliases SEM_ALIASES, filter VARCHAR2, index_status VARCHAR2, options VARCHAR2, graphs SEM_GRAPHS, named_graphs SEM_GRAPHS ) RETURN ANYDATASET;
The query attribute is required. The other attributes are optional (that is, each can be a null value).
The query attribute is a string literal (or concatenation of string literals) with one or more triple patterns, usually containing variables. (The query attribute cannot be a bind variable or an expression involving a bind variable.) A triple pattern is a triple of atoms followed by a period. Each atom can be a variable (for example, ?x), a qualified name (for example, rdf:type) that is expanded based on the default namespaces and the value of the aliases attribute, or a full URI (for example, <http://www.example.org/family/Male>). In addition, the third atom can be a numeric literal (for example, 3.14), a plain literal (for example, "Herman"), a language-tagged plain literal (for example, "Herman"@en), or a typed literal (for example, "123"^^xsd:int).
For example, the following query attribute specifies three triple patterns to find grandfathers (that is, grandparents who are also male) and the height of each of their grandchildren:
'{ ?x :grandParentOf ?y . ?x rdf:type :Male . ?y :height ?h }'
The models attribute identifies the model or models to use. Its data type is SEM_MODELS, which has the following definition: TABLE OF VARCHAR2(25). If you are querying a virtual model, specify only the name of the virtual model and no other models. (Virtual models are explained in Section 1.3.8.)
The rulebases attribute identifies one or more rulebases whose rules are to be applied to the query. Its data type is SDO_RDF_RULEBASES, which has the following definition: TABLE OF VARCHAR2(25). If you are querying a virtual model, this attribute must be null.
The aliases attribute identifies one or more namespaces, in addition to the default namespaces, to be used for expansion of qualified names in the query pattern. Its data type is SEM_ALIASES, which has the following definition: TABLE OF SEM_ALIAS, where each SEM_ALIAS element identifies a namespace ID and namespace value. The SEM_ALIAS data type has the following definition: (namespace_id VARCHAR2(30), namespace_val VARCHAR2(4000))
The following default namespaces (namespace_id and namespace_val attributes) are used by the SEM_MATCH table function and the SEM_CONTAINS and SEM_RELATED operators:
('ogc', 'http://www.opengis.net/ont/geosparql#')
('ogcf', 'http://www.opengis.net/def/function/geosparql/')
('ogcgml', 'http://www.opengis.net/ont/gml#')
('ogcsf', 'http://www.opengis.net/ont/sf#')
('orardf', 'http://xmlns.oracle.com/rdf/')
('orageo', 'http://xmlns.oracle.com/rdf/geo/')
('owl', 'http://www.w3.org/2002/07/owl#')
('rdf', 'http://www.w3.org/1999/02/22-rdf-syntax-ns#')
('rdfs', 'http://www.w3.org/2000/01/rdf-schema#')
('xsd', 'http://www.w3.org/2001/XMLSchema#')
You can override any of these defaults by specifying the namespace_id value and a different namespace_val value in the aliases attribute.
The filter attribute identifies any additional selection criteria. If this attribute is not null, it should be a string in the form of a WHERE clause without the WHERE keyword. For example: '(h >= ''6'')' to limit the result to cases where the height of the grandfather's grandchild is 6 or greater (using the example of triple patterns earlier in this section).
Note:
Instead of using thefilter attribute, you are encouraged to use the FILTER keyword inside your query pattern whenever possible (as explained in Section 1.6.2). Using the FILTER keyword is likely to give better performance because of internal optimizations. The filter argument, however, can be useful if you require SQL constructs that cannot be expressed with the FILTER keyword.The index_status attribute lets you query semantic data even when the relevant entailment does not have a valid status. (If you are querying a virtual model, this attribute refers to the entailment associated with the virtual model.) If this attribute is null, the query returns an error if the entailment does not have a valid status. If this attribute is not null, it must be the string INCOMPLETE or INVALID. For an explanation of query behavior with different index_status values, see Section 1.6.1.
The options attribute identifies options that can affect the results of queries. Options are expressed as keyword-value pairs. The following options are supported:
-
ALL_BGP_HASHandALL_BGP_NLare global query optimizer hints that specify that all inter-BGP joins (for example. the join between the root BGP and an OPTIONAL BGP) should use the specified join type. (BGP stands for basic graph pattern. From the W3C SPARQL Query Language for RDF Recommendation: "SPARQL graph pattern matching is defined in terms of combining the results from matching basic graph patterns. A sequence of triple patterns interrupted by a filter comprises a single basic graph pattern. Any graph pattern terminates a basic graph pattern."The
BGP_JOIN(USE_NL)andBGP_JOIN(USE_HASH)HINT0 query optimizer hints can be used to control the join type with finer granularity.Example 1-14 shows the ALL_BGP_HASH option used in a SEM_MATCH query.
-
ALL_LINK_HASHandALL_LINK_NLare global query optimizer hints that specify the join type for all RDF_LINK$ joins (that is, all joins between triple patterns within a BGP).ALL_LINK_HASHandALL_LINK_NLcan also be used within a HINT0 query optimizer hint for finer granularity. -
ALL_MAX_PP_DEPTH(n)is a global query optimizer hint that sets the maximum depth to use when evaluating * and + property path operators. The default value is 10. TheMAP_PP_DEPTH(n)HINT0 hint can be used to specify maximum depth with finer granularity. -
ALL_ORDEREDis a global query optimizer hint that specifies that the triple patterns in each BGP in the query should be evaluated in order.Example 1-14 shows the ALL_ORDERED option used in a SEM_MATCH query.
-
ALL_USE_PP_HASHandALL_USE_PP_NLare global query optimizer hints that specify the join type to use when evaluating property path expressions. TheUSE_PP_HASHandUSE_PP_NLHINT0 hints can be used for specifying join type with finer granularity. -
ALLOW_DUP=Tgenerates an underlying SQL statement that performs a "union all" instead of a union of the semantic models and inferred data (if applicable). This option may introduce more rows (duplicate triples) in the result set, and you may need to adjust the application logic accordingly. If you do not specify this option, duplicate triples are automatically removed across all the models and inferred data to maintain the set semantics of merged RDF graphs; however, removing duplicate triples increases query processing time. In general, specifying'ALLOW_DUP=T'improves performance significantly when multiple semantic models are involved in a SEM_MATCH query.If you are querying a virtual model, specifying
ALLOW_DUP=Tcauses the SEMV_vm_name view to be queried; otherwise, the SEMU_vm_name view is queried. -
ALLOW_PP_DUP=T allows duplicate results for + and * property path queries. Allowing duplicate results may return the first result rows faster. -
CLOB_AGG_SUPPORT=Tenables support for CLOB values for the following aggregates: MIN, MAX, GROUP_CONCAT, SAMPLE. Note that enabling CLOB support incurs a significant performance penalty. -
CLOB_EXP_SUPPORT=Tenables support for CLOB values for some built-in SPARQL functions. Note that enabling CLOB support incurs a significant performance penalty. -
CONSTRUCT_STRICT=Teliminates invalid RDF triples from the result of SPARQL CONSTRUCT or SPARQL DESCRIBE syntax queries. RDF triples with literals in the subject position or literals or blank nodes in the predicate position are considered invalid. -
CONSTRUCT_UNIQUE=Teliminates duplicate RDF triples from the result of SPARQL CONSTRUCT or SPARQL DESCRIBE syntax queries. -
DO_UNESCAPE=Tcauses characters in the following return columns to be unescaped according to the W3C N-Triples specification (http://www.w3.org/TR/rdf-testcases/#ntriples): var, var$_PREFIX, var$_SUFFIX, var$RDFCLOB, var$RDFLTYP, var$RDFLANG, and var$RDFTERM.See also the reference information for SEM_APIS.ESCAPE_CLOB_TERM, SEM_APIS.ESCAPE_CLOB_VALUE, SEM_APIS.ESCAPE_RDF_TERM, SEM_APIS.ESCAPE_RDF_VALUE, SEM_APIS.UNESCAPE_CLOB_TERM, SEM_APIS.UNESCAPE_CLOB_VALUE, SEM_APIS.UNESCAPE_RDF_TERM, and SEM_APIS.UNESCAPE_RDF_VALUE.
-
FINAL_VALUE_HASHandFINAL_VALUE_NLare global query optimizer hints that specify the join method that should be used to obtain the lexical values for any query variables that are not used in a FILTER clause. -
GRAPH_MATCH_UNNAMED=Tallows unnamed triples (nullG_ID) to be matched inside GRAPH clauses. That is, two triples will satisfy the graph join condition if their graphs are equal or if one or both of the graphs are null. This option may be useful when your dataset includes unnamed TBOX triples or unnamed entailed triples. -
HINT0={<hint-string>}(pronounced and written "hint" and the number zero) specifies one or more keywords with hints to influence the execution plan and results of queries. Conceptually, a graph pattern with n triple patterns and referring to m distinct variables results in an (n+m)-way join: n-way self-join of the target RDF model or models and optionally the corresponding entailment, and then m joins with RDF_VALUE$ for looking up the values for the m variables. A hint specification affects the join order and join type used for the query execution.The hint specification, <hint-string>, uses keywords, some of which have parameters consisting of a sequence or set of aliases, or references, for individual triple patterns and variables used in the query. Aliases for triple patterns are of the form ti where i refers to the 0-based ordinal numbers of triple patterns in the query. For example, the alias for the first triple pattern in a query is
t0, the alias for the second one ist1, and so on. Aliases for the variables used in a query are simply the names of those variables. Thus,?xwill be used in the hint specification as the alias for a variable?xused in the graph pattern.Hints used for influencing query execution plans include LEADING(<sequence of aliases>), USE_NL(<set of aliases>), USE_HASH(<set of aliases>), and INDEX(<alias> <index_name>). These hints have the same format and basic meaning as hints in SQL statements, which are explained in Oracle Database SQL Language Reference.
Example 1-10 shows the HINT0 option used in a SEM_MATCH query.
-
HTTP_METHOD=POST_PARindicates that the HTTP POST method with URL-encoded parameters pass should be used for the SERVICE request. The default option for requests is the HTTP GET method. For more information about SPARQL protocol, seehttp://www.w3.org/TR/2013/REC-sparql11-protocol-20130321/#protocol. -
INF_ONLY=Tqueries only the entailed graph for the specified models and rulebases. -
PLUS_RDFT=Tcan be used with SPARQL SELECT syntax (see Section 1.6.7.1, "Expressions in the SELECT Clause") to additionally return a var$RDFTERM CLOB column for each projected query variable. The value for this column is equivalent to the result of SEM_APIS.COMPOSE_RDF_TERM(var, var$RDFVTYP, var$RDFLTYP, var$RDFLANG, var$RDFCLOB). When using this option, the return columns for each variable var will be var, var$RDFVID, var$_PREFIX, var$_SUFFIX, var$RDFVTYP, var$RDFCLOB, var$RDFLTYP, var$RDFLANG, and var$RDFTERM. -
PLUS_RDFT=VCcan be used with SPARQL SELECT syntax (see Section 1.6.7.1, "Expressions in the SELECT Clause") to additionally return a var$RDFTERM VARCHAR2(4000) column for each projected query variable. The value for this column is equivalent to the result of SEM_APIS.COMPOSE_RDF_TERM(var, var$RDFVTYP, var$RDFLTYP, var$RDFLANG). When using this option, the return columns for each variable var will be var, var$RDFVID, var$_PREFIX, var$_SUFFIX, var$RDFVTYP, var$RDFCLOB, var$RDFLTYP, var$RDFLANG, and var$RDFTERM. -
PROJ__EXACT_VALUES=Tdisables canonicalization of values returned from functions and of constant values used in value assignment statements. Such values are canonicalized by default. -
SERVICE_CLOB=Fsets the column values of var$RDFCLOB to null instead of saving values when calling the service. If CLOB data is not needed in your application, performance can be improved by using this option to skip CLOB processing. -
SERVICE_ESCAPE=Fdisables character escaping for RDF literal values returned by SPARQL SERVICE calls. RDF literal values are escaped by default. If character escaping is not relevant for your application, performance can be improved by disabling character escaping. -
SERVICE_JPDWN=Tis a query optimizer hint for using nested loop join in SPARQL SERVICE. Example 1-70, "SPARQL SERVICE Join Push Down" shows theSERVICE_JPDWN=Toption used in a SEM_MATCH query. -
SERVICE_PROXY=<proxy-string>sets a proxy address to be used when performing http connections. The given proxy-string will be used in SERVICE queries. Example 1-73, "Setting Proxy Server in SPARQL SERVICE" shows a SEM_MATCH query including a proxy address. -
STRICT_AGG_CARD=Tuses SPARQL semantics (one null row) instead of SQL semantics (zero rows) for aggregate queries with graph patterns that fail to match. This option incurs a slight performance penalty. -
STRICT_DEFAULT=Trestricts the default graph to unnamed triples when no dataset information is specified.
The graphs attribute specifies the set of named graphs from which to construct the default graph for a SEM_MACH query. Its data type is SEM_GRAPHS, which has the following definition: TABLE OF VARCHAR2(4000). The default value for this attribute is NULL. When graphs is NULL, the "union all" of all graphs in the set of query models is used as the default graph.
The named_graphs attribute specifies the set of named graphs that can be matched by a GRAPH clause. Its data type is SEM_GRAPHS, which has the following definition: TABLE OF VARCHAR2(4000). The default value for this attribute is NULL. When named_graphs is NULL, all named graphs in the set of query models can be matched by a GRAPH clause.
The SEM_MATCH table function returns an object of type ANYDATASET, with elements that depend on the input variables. In the following explanations, var represents the name of a variable used in the query. For each variable var, the result elements have the following attributes: var, var$RDFVID, var$_PREFIX, var$_SUFFIX, var$RDFVTYP, var$RDFCLOB, var$RDFLTYP, and var$RDFLANG.
In such cases, var has the lexical value bound to the variable, var$RDFVID has the VALUE_ID of the value bound to the variable, var$_PREFIX and var$_SUFFIX are the prefix and suffix of the value bound to the variable, var$RDFVTYP indicates the type of value bound to the variable (URI, LIT [literal], or BLN [blank node]), var$RDFCLOB has the lexical value bound to the variable if the value is a long literal, var$RDFLTYP indicates the type of literal bound if a literal is bound, and var$RDFLANG has the language tag of the bound literal if a literal with language tag is bound. var$RDFCLOB is of type CLOB, while all other attributes are of type VARCHAR2.
For a literal value or a blank node, its prefix is the value itself and its suffix is null. For a URI value, its prefix is the left portion of the value up to and including the rightmost occurrence of any of the three characters / (slash), # (pound), or : (colon), and its suffix is the remaining portion of the value to the right. For example, the prefix and suffix for the URI value http://www.example.org/family/grandParentOf are http://www.example.org/family/ and grandParentOf, respectively.
Along with columns for variable values, a SEM_MATCH query that uses SPARQL SELECT syntax returns one additional NUMBER column, SEM$ROWNUM, which can be used to ensure the correct result ordering for queries that involve a SPARQL ORDER BY clause.
A SEM_MATCH query that uses SPARQL ASK syntax returns the columns ASK, ASK$RDFVID, ASK$_PREFIX, ASK$_SUFFIX, ASK$RDFVTYP, ASK$RDFCLOB, ASK$RDFLTYP, ASK$RDFLANG, and SEM$ROWNUM. This is equivalent to a SPARQL SELECT syntax query that projects a single ?ask variable.
A SEM_MATCH query that uses SPARQL CONSTRUCT or SPARQL DESCRIBE syntax returns columns that contain RDF triple data rather than query result bindings. Such queries return values for subject, predicate and object components. See Section 1.6.4, "Graph Patterns: Support for SPARQL CONSTRUCT Syntax"for details.
Example 1-9 selects all grandfathers (grandparents who are male) and their grandchildren from the family model, using inferencing from both the RDFS and family_rb rulebases. (This example is an excerpt from Example 1-89 in Section 1.12.2.)
Example 1-9 SEM_MATCH Table Function
SELECT x, y
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male}',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
Example 1-10 is functionally the same as Example 1-9, but it adds the HINT0 option.
Example 1-10 HINT0 Option with SEM_MATCH Table Function
SELECT x, y
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male}',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_Aliases(SEM_ALIAS('','http://www.example.org/family/')),
null,
null,
'HINT0={LEADING(t0 t1) USE_NL(?x ?y) GET_CANON_VALUE(?x ?y)}'));
Example 1-11 uses the Pathway/Genome BioPax ontology to get all chemical compound types that belong to both Proteins and Complexes:
Example 1-11 SEM_MATCH Table Function
SELECT t.r
FROM TABLE (SEM_MATCH (
'{?r rdfs:subClassOf :Proteins .
?r rdfs:subClassOf :Complexes}',
SEM_Models ('BioPax'),
SEM_Rulebases ('rdfs'),
SEM_Aliases (SEM_ALIAS('', 'http://www.biopax.org/release1/biopax-release1.owl')),
NULL)) t;
As shown in Example 1-11, the search pattern for the SEM_MATCH table function is specified using SPARQL-like syntax where the variable starts with the question-mark character (?). In this example, the variable ?r must match to the same term, and thus it must be a subclass of both Proteins and Complexes.
To use the SEM_RELATED operator to query an OWL ontology, see Section 2.3.
When you are querying multiple models or querying one or more models and the corresponding entailment, consider using virtual models (explained in Section 1.3.8) because of the potential performance benefits.
This section also contains the following topics:
1.6.1 Performing Queries with Incomplete or Invalid Entailments
You can query semantic data even when the relevant entailment does not have a valid status if you specify the string value INCOMPLETE or INVALID for the index_status attribute of the SEM_MATCH table function. (The entailment status is stored in the STATUS column of the MDSYS.SEM_RULES_INDEX_INFO view, which is described in Section 1.3.7. The SEM_MATCH table function is described in Section 1.6.)
The index_status attribute value affects the query behavior as follows:
-
If the entailment has a valid status, the query behavior is not affected by the value of the
index_statusattribute. -
If you provide no value or specify a null value for
index_status, the query returns an error if the entailment does not have a valid status. -
If you specify the string
INCOMPLETEfor theindex_statusattribute, the query is performed if the status of the entailment is incomplete or valid. -
If you specify the string
INVALIDfor theindex_statusattribute, the query is performed regardless of the actual status of the entailment (invalid, incomplete, or valid).
However, the following considerations apply if the status of the entailment is incomplete or invalid:
-
If the status is incomplete, the content of an entailment may be approximate, because some triples that are inferable (due to the recent insertions into the underlying models) may not actually be present in the entailment, and therefore results returned by the query may be inaccurate.
-
If the status is invalid, the content of the entailment may be approximate, because some triples that are no longer inferable (due to recent modifications to the underlying models or rulebases, or both) may still be present in the entailment, and this may affect the accuracy of the result returned by the query. In addition to possible presence of triples that are no longer inferable, some inferable rows may not actually be present in the entailment.
1.6.2 Graph Patterns: Support for Curly Brace Syntax, and OPTIONAL, FILTER, UNION, and GRAPH Keywords
The SEM_MATCH table function accepts the syntax for the graph pattern in which a sequence of triple patterns is enclosed within curly braces. The period is usually required as a separator unless followed by the OPTIONAL, FILTER, UNION, or GRAPH keyword. With this syntax, you can do any combination of the following:
-
Use the OPTIONAL construct to retrieve results even in the case of a partial match
-
Use the FILTER construct to specify a filter expression in the graph pattern to restrict the solutions to a query
-
Use the UNION construct to match one of multiple alternative graph patterns
-
Use the GRAPH construct (explained in Section 1.6.2.1) to scope graph pattern matching to a set of named graphs
Example 1-12 uses the syntax with curly braces and a period to express a graph pattern in the SEM_MATCH table function.
Example 1-12 Curly Brace Syntax
SELECT x, y
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male}',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
Example 1-13 uses the OPTIONAL construct to modify Example 1-12, so that it also returns, for each grandfather, the names of the games that he plays or null if he does not play any games.
Example 1-13 Curly Brace Syntax and OPTIONAL Construct
SELECT x, y, game
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male .
OPTIONAL{?x :plays ?game}
}',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null,
null,
'HINT0={LEADING(t0 t1) USE_NL(?x ?y)}'));
When multiple triple patterns are present in an OPTIONAL graph pattern, values for optional variables are returned only if a match is found for each triple pattern in the OPTIONAL graph pattern. Example 1-14 modifies Example 1-13 so that it returns, for each grandfather, the names of the games both he and his grandchildren play, or null if he and his grandchildren have no such games in common. It also uses global query optimizer hints to specify that triple patterns should be evaluated in order within each BGP and that a hash join should be used to join the root BGP with the OPTIONAL BGP.
Example 1-14 Curly Brace Syntax and Multi-Pattern OPTIONAL Construct
SELECT x, y, game
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male .
OPTIONAL{?x :plays ?game . ?y :plays ?game}
}',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null,
'ALL_ORDERED ALL_BGP_HASH'));
A single query can contain multiple OPTIONAL graph patterns, which can be nested or parallel. Example 1-15 modifies Example 1-14 with a nested OPTIONAL graph pattern. This example returns, for each grandfather, (1) the games he plays or null if he plays no games and (2) if he plays games, the ages of his grandchildren that play the same game, or null if he has no games in common with his grandchildren. Note that in Example 1-15 a value is returned for ?game even if the nested OPTIONAL graph pattern ?y :plays ?game . ?y :age ?age is not matched.
Example 1-15 Curly Brace Syntax and Nested OPTIONAL Construct
SELECT x, y, game, age
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male .
OPTIONAL{?x :plays ?game
OPTIONAL {?y :plays ?game . ?y :age ?age} }
}',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
Example 1-16 modifies Example 1-14 with a parallel OPTIONAL graph pattern. This example returns, for each grandfather, (1) the games he plays or null if he plays no games and (2) his email address or null if he has no email address. Note that, unlike nested OPTIONAL graph patterns, parallel OPTIONAL graph patterns are treated independently. That is, if an email address is found, it will be returned regardless of whether or not a game was found; and if a game was found, it will be returned regardless of whether an email address was found.
Example 1-16 Curly Brace Syntax and Parallel OPTIONAL Construct
SELECT x, y, game, email
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male .
OPTIONAL{?x :plays ?game}
OPTIONAL{?x :email ?email}
}',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
Example 1-17 uses the FILTER construct to modify Example 1-12, so that it returns grandchildren information for only those grandfathers who are residents of either NY or CA.
Example 1-17 Curly Brace Syntax and FILTER Construct
SELECT x, y
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male . ?x :residentOf ?z
FILTER (?z = "NY" || ?z = "CA")}',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
In addition to arithmetic operators (+, -, *, /), Boolean operators and logical connectives (||, &&, !), and comparison operators (<, >, <=, >=, =, !=), several built-in functions are available for use in FILTER clauses. Table 1-12 lists built-in functions that you can use in the FILTER clause. In the Description column of Table 1-12, x, y, and z are arguments of the appropriate types.
Table 1-12 Built-in Functions Available for FILTER Clause
| Function | Description |
|---|---|
|
ABS(RDF term) |
Returns the absolute value of |
|
BNODE(literal) or BNODE() |
Constructs a blank node that is distinct from all blank nodes in the dataset of the query, and those created by this function in other queries. The form with no arguments results in a distinct blank node in every call. The form with a simple literal results in distinct blank nodes for different simple literals, and the same blank node for calls with the same simple literal. |
|
BOUND(variable) |
BOUND(x) returns |
|
CEIL(RDF term) |
Returns the closest number with no fractional part which is not less than term. If term is a non-numerical value, returns null. |
|
COALESCE(term list) |
Returns the first element on the argument list that is evaluated without raising an error. Unbound variables raise an error if evaluated. Returns null if there are no valid elements in the term list. |
|
CONCAT(term list) |
Returns an |
|
CONTAINS(literal, match) |
Returns |
|
DATATYPE(literal) |
DATATYPE(x) returns a URI representing the datatype of |
|
DAY(argument) |
Returns an integer corresponding to the day part of argument. If the argument is not a |
|
ENCODE_FOR_URI(literal) |
Returns a string where the reserved characters in |
|
EXISTS(pattern) |
Returns |
|
FLOOR(RDF term) |
Returns the closest number with no fractional part which is less than |
|
HOURS(argument) |
Returns an integer corresponding to the hours part of |
|
IF(condition , expression1, expression2) |
Evaluates the condition and obtains the effective Boolean value. If true, the first expression is evaluated and its value returned. If false, the second expression is used. If the condition raises an error, the error is passed as the result of the IF statement. |
|
IRI(RDF term) |
Returns an IRI resolving the string representation of argument |
|
isBLANK(RDF term) |
isBLANK(x) returns |
|
isIRI(RDF term) |
isIRI(x) returns |
|
isLITERAL(RDF term) |
isLiteral(x) returns |
|
IsNUMERIC(RDF term) |
Returns |
|
isURI(RDF term) |
isURI(x) returns |
|
LANG(literal) |
LANG(x) returns a plain literal serializing the language tag of |
|
LANGMATCHES(literal, literal) |
LANGMATCHES(x, y) returns |
|
LCASE(literal) |
Returns a string where each character in literal is converted to its lowercase correspondent. |
|
MD5(literal) |
Returns the checksum for |
|
MINUTES(argument) |
Returns an integer corresponding to the minutes part of |
|
MONTH(argument) |
Returns an integer corresponding to the month part of |
|
NOT_EXISTS(pattern) |
Returns |
|
NOW() |
Returns an |
|
RAND() |
Generates a numeric value in the range of [0,1). |
|
REGEX(string, pattern) |
REGEX(x,y) returns |
|
REGEX(string, pattern, flags) |
REGEX(x,y,z) returns |
|
REPLACE(string, pattern, replacement) |
Returns a string where each match of the regular expression |
|
REPLACE(string, pattern, replacement, flags) |
Returns a string where each match of the regular expression For more information about the regular expressions supported, see the Oracle Regular Expression Support appendix in Oracle Database SQL Language Reference. |
|
ROUND(RDF term) |
Returns the closest number with no fractional part to |
|
sameTerm(RDF term, RDF term) |
sameTerm(x, y) returns |
|
SECONDS(argument) |
Returns an integer corresponding to the seconds part of |
|
SHA1(literal) |
Returns the checksum for |
|
SHA256(literal) |
Returns the checksum for |
|
SHA384(literal) |
Returns the checksum for |
|
SHA512(literal) |
Returns the checksum for |
|
STR(RDF term) |
STR(x) returns a plain literal of the string representation of |
|
STRAFTER(literal, literal) |
StrAfter (x,y) returns the portion of the string corresponding to substring that precedes in |
|
STRBEFORE(literal, literal) |
StrBefore (x,y) returns the portion of the string corresponding to the start of |
|
STRDT(string, datatype) |
Construct a literal term composed by the |
|
STRENDS(literal, match) |
Returns |
|
STRLANG (string, languageTag) |
Constructs a string composed by the |
|
STRLEN(literal) |
Returns the length of the lexical form of the |
|
STRSTARTS(literal, match) |
Returns |
|
STRUUID() |
Returns a string containing the scheme section of a new UUID. |
|
SUBSTR(term, startPos) |
Returns the string corresponding to the portion of |
|
SUBSTR(term, startPos, length) |
Returns the string corresponding to the portion of term that starts at |
|
term IN (term list) |
The expression x IN(term list) returns |
|
term NOT IN (term list) |
The expression x NOT IN(term list) returns |
|
TIMEZONE(argument) |
Returns the time zones section of |
|
TZ(argument) |
Returns an integer corresponding to the time zone part of |
|
UCASE(literal) |
Returns a string where each character in |
|
URI(RDF term) |
(Synonym for IRI(RDF term) |
|
UUID() |
Returns a URI with a new Universal Unique Identifier. The value and the version correspond to the PL/SQL function |
|
YEAR(argument) |
Returns an integer corresponding to the year part of |
See also the descriptions of the built-in functions defined in the SPARQL query language specification (http://www.w3.org/TR/sparql11-query/), to better understand the built-in functions available in SEM_MATCH.
The following XML Schema casting functions are available for use in FILTER clauses. These functions take an RDF term as input and return a new RDF term of the desired type or raise an error if the term cannot be cast to the desired type. Details of type casting can be found in Section 17.1 of the XPath query specification: http://www.w3.org/TR/xpath-functions/#casting-from-primitive-to-primitive. These functions use the XML Namespace xsd : http://www.w3.org/2001/XMLSchema#.
-
xsd:string (RDF term)
-
xsd:dateTime (RDF term)
-
xsd:boolean (RDF term)
-
xsd:integer (RDF term)
-
xsd:float (RDF term)
-
xsd:double (RDF term)
-
xsd:decimal (RDF term)
Example 1-18 uses the REGEX built-in function to select all grandfathers that have an Oracle email address. Note that backslash (\) characters in the regular expression pattern must be escaped in the query string; for example, \\. produces the following pattern: \.
Example 1-18 Curly Brace Syntax and FILTER with REGEX and STR Built-In Constructs
SELECT x, y, z
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male . ?x :email ?z
FILTER (REGEX(STR(?z), "@oracle\\.com$"))}',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
Example 1-19 uses the UNION construct to modify Example 1-17, so that grandfathers are returned only if they are residents of NY or CA or own property in NY or CA, or if both conditions are true (they reside in and own property in NY or CA).
Example 1-19 Curly Brace Syntax and UNION and FILTER Constructs
SELECT x, y
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male
{{?x :residentOf ?z} UNION {?x :ownsPropertyIn ?z}}
FILTER (?z = "NY" || ?z = "CA")}',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
If you use the syntax with curly braces to express a graph pattern:
-
The query always returns canonical lexical forms for the matching values for the variables.
-
Any hints specified in the
optionsargument using HINT0={<hint-string>} (explained in Section 1.6), should be constructed only on the basis of the portion of the graph pattern inside the root BGP. For example, the only valid aliases for use in a hint specification for the query in Example 1-13 aret0,t1,?x, and?y. Inline query optimizer hints can be used to influence other parts of the graph pattern (see Section 1.6.9). -
The FILTER construct is not supported for variables bound to long literals.
1.6.2.1 GRAPH Keyword Support
A SEM_MATCH query is executed against an RDF Dataset. An RDF Dataset is a collection of graphs that includes one unnamed graph, known as the default graph, and one or more named graphs, which are identified by a URI. Graph patterns that appear inside a GRAPH clause are matched against the set of named graphs, and graph patterns that do not appear inside a graph clause are matched against the default graph. The graphs and named_graphs SEM_MATCH parameters are used to construct the default graph and set of named graphs for a given SEM_MATCH query. A summary of possible dataset configurations is shown in Table 1-13.
Table 1-13 SEM_MATCH graphs and named_graphs Values, and Resulting Dataset Configurations
| Parameter Values | Default Graph | Set of Named Graphs |
|---|---|---|
|
|
Union All of all unnamed triples and all named graph triples. (But if the |
All named graphs |
|
|
Empty set |
{g1,…, gn} |
|
|
Union All of {g1,…, gm} |
Empty set |
|
|
Union All of {g1,…, gm} |
{gn,…, gz} |
Example 1-20 uses the GRAPH construct to scope graph pattern matching to a specific named graph. This example finds the names and email addresses of all people in the <http://www.example.org/family/Smith> named graph.
Example 1-20 Named Graph Construct
SELECT name, email
FROM TABLE(SEM_MATCH(
'{GRAPH :Smith {
?x :name ?name . ?x :email ?email } }',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
In addition to URIs, variables can appear after the GRAPH keyword. Example 1-21 uses a variable, ?g, with the GRAPH keyword, and uses the named_graphs parameter to restrict the possible values of ?g to the <http://www.example.org/family/Smith> and <http://www.example.org/family/Jones> named graphs. Aliases specified in SEM_ALIASES argument can be used in the graphs and named_graphs parameters.
Example 1-21 Using the named_graphs Parameter
SELECT name, email
FROM TABLE(SEM_MATCH(
'{GRAPH ?g {
?x :name ?name . ?x :email ?email } }',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null,null,null,null,
SEM_GRAPHS('<http://www.example.org/family/Smith>',
':Jones')));
Example 1-22 uses the default graph to query the union of the <http://www.example.org/family/Smith> and <http://www.example.org/family/Jones> named graphs.
Example 1-22 Using the graphs Parameter
FROM TABLE(SEM_MATCH(
'{?x :name ?name . ?x :email ?email }',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null,null,null,
SEM_GRAPHS('<http://www.example.org/family/Smith>',
':Jones'),
null));
See also the W3C SPARQL specification for more information on RDF data sets and the GRAPH construct, specifically: http://www.w3.org/TR/rdf-sparql-query/#rdfDataset
1.6.3 Graph Patterns: Support for SPARQL ASK Syntax
SEM_MATCH allows fully-specified SPARQL ASK queries in the query parameter.
ASK queries are used to test whether or not a solution exists for a given query pattern. In contrast to other forms of SPARQL queries, ASK queries do not return any information about solutions to the query pattern. Instead, such queries return "true"^^xsd:boolean if a solution exists and "false"^^xsd:boolean if no solution exists.
All SPARQL ASK queries return the same columns: ASK, ASK$RDFVID, ASK$_PREFIX, ASK$_SUFFIX, ASK$RDFVTYP, ASK$RDFCLOB, ASK$RDFLTYP, ASK$RDFLANG, SEM$ROWNUM. Note that these columns are the same as a SPARQL SELECT syntax query that projects a single ?ask variable.
SPARQL ASK queries will generally give better performance than an equivalent SPARQL SELECT syntax query because the ASK query does not have to retrieve lexical values for query variables, and query execution can stop after a single result has been found.
SPARQL ASK queries use the same syntax as SPARQL SELECT queries, but the topmost SELECT clause must be replaced with the keyword ASK.
Example 1-23 shows a SPARQL ASK query that determines whether or not any cameras are for sale with more than 10 megapixels that cost less than 50 dollars.
SELECT ask
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/electronics/>
ASK
WHERE
{?x :price ?p .
?x :megapixels ?m .
FILTER (?p < 50 && ?m > 10)
}',
SEM_Models('electronics'),
SEM_Rulebases('RDFS'),
null, null));
See also the W3C SPARQL specification for more information on SPARQL ASK queries, specifically: http://www.w3.org/TR/sparql11-query/#ask
1.6.4 Graph Patterns: Support for SPARQL CONSTRUCT Syntax
SEM_MATCH allows fully-specified SPARQL CONSTRUCT queries in the query parameter.
CONSTRUCT queries are used to build RDF graphs from stored RDF data. In contrast to SPARQL SELECT queries, CONSTRUCT queries return a set of RDF triples rather than a set of query solutions (variable bindings).
All SPARQL CONSTRUCT queries return the same columns from SEM_MATCH. These columns correspond to the subject, predicate and object of an RDF triple, and there are 10 columns for each triple component. In addition, a SEM$ROWNUM column is returned. More specifically, the following columns are returned:
SUBJ SUBJ$RDFVID SUBJ$_PREFIX SUBJ$_SUFFIX SUBJ$RDFVTYP SUBJ$RDFCLOB SUBJ$RDFLTYP SUBJ$RDFLANG SUBJ$RDFTERM SUBJ$RDFCLBT PRED PRED$RDFVID PRED$_PREFIX PRED$_SUFFIX PRED$RDFVTYP PRED$RDFCLOB PRED$RDFLTYP PRED$RDFLANG PRED$RDFTERM PRED$RDFCLBT OBJ OBJ$RDFVID OBJ$_PREFIX OBJ$_SUFFIX OBJ$RDFVTYP OBJ$RDFCLOB OBJ$RDFLTYP OBJ$RDFLANG OBJ$RDFTERM OBJ$RDFCLBT SEM$ROWNUM
For each component, COMP, COMP$RDFVID, COMP$_PREFIX, COMP$_SUFFIX, COMP$RDFVTYP, COMP$RDFCLOB, COMP$RDFLTYP, and COMP$RDFLANG correspond to the same values as those from SPARQL SELECT queries. COMP$RDFTERM holds a VARCHAR2(4000) RDF term in N-Triple syntax, and COMP$RDFCLBT holds a CLOB RDF term in N-Triple syntax.
SPARQL CONSTRUCT queries use the same syntax as SPARQL SELECT queries, except the topmost SELECT clause is replaced with a CONSTRUCT template. The CONSTRUCT template determines how to construct the result RDF graph using the results of the query pattern defined in the WHERE clause. A CONSTRUCT template consists of the keyword CONSTRUCT followed by sequence of SPARQL triple patterns that are enclosed within curly braces. The keywords OPTIONAL, UNION, FILTER, MINUS, BIND, VALUES, and GRAPH are not allowed within CONSTRUCT templates, and property path expressions are not allowed within CONSTRUCT templates. These keywords, however, are allowed within the query pattern inside the WHERE clause.
Example 1-24 shows a SPARQL CONSTRUCT query that builds an RDF graph of employee names using the foaf vocabulary.
SELECT subj$rdfterm, pred$rdfterm, obj$rdfterm
FROM TABLE(SEM_MATCH(
'PREFIX ent: <http://www.example.org/enterprise/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
CONSTRUCT
{?e foaf:givenName ?fname .
?e foaf:familyName ?lname
}
WHERE
{?e ent:fname ?fname .
?e ent:lname ?lname
}',
SEM_Models('enterprise'),
SEM_Rulebases('RDFS'),
null, null));
SPARQL CONSTRUCT queries build result RDF graphs in the following manner. For each result row returned by the WHERE clause, variable values are substituted into the CONSTRUCT template to create one or more RDF triples. Suppose the graph pattern in the WHERE clause of Example 1-24 returns the following result rows.
| E$RDFTERM | FNAME$RDFTERM | LNAME$RDFTERM |
|---|---|---|
| ent:employee1 | "Fred" | "Smith" |
| ent:employee2 | "Jane" | "Brown" |
| ent:employee3 | "Bill" | "Jones" |
The overall SEM_MATCH CONSTRUCT query in Example 1-24 would then return the following rows, which correspond to six RDF triples (two for each result row of the query pattern).
| SUBJ$RDFTERM | PRED$RDFTERM | OBJ$RDFTERM |
|---|---|---|
| ent:employee1 | foaf:givenName | "Fred" |
| ent:employee1 | foaf:familyName | "Smith" |
| ent:employee2 | foaf:givenName | "Jane" |
| ent:employee2 | foaf:familyName | "Brown" |
| ent:employee3 | foaf:givenName | "Bill" |
| ent:employee3 | foaf:familyName | "Jones" |
SPARQL SOLUTION modifiers can be used with CONSTRUCT queries. Example 1-25 shows the use of ORDER BY and LIMIT to build a graph about the top two highest-paid employees. Note that the LIMIT 2 clause applies to the query pattern not to the overall CONSTRUCT query. That is, the query pattern will return two result rows, but the overall CONSTRUCT query will return 6 RDF triples (three for each of the two employees bound to ?e).
Example 1-25 CONSTRUCT with Solution Modifiers
SELECT subj$rdfterm, pred$rdfterm, obj$rdfterm
FROM TABLE(SEM_MATCH(
'PREFIX ent: <http://www.example.org/enterprise/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
CONSTRUCT
{ ?e ent:fname ?fname .
?e ent:lname ?lname .
?e ent:dateOfBirth ?dob }
WHERE
{ ?e ent:fname ?fname .
?e ent:lname ?lname .
?e ent:salary ?sal
}
ORDER BY DESC(?sal)
LIMIT 2',
SEM_Models('enterprise'),
SEM_Rulebases('RDFS'),
null, null));
SPARQL 1.1 features are supported within CONSTRUCT query patterns. Example 1-26 shows the use of subqueries and SELECT expressions within a CONSTRUCT query.
Example 1-26 SPARQL 1.1 Features with CONSTRUCT
SELECT subj$rdfterm, pred$rdfterm, obj$rdfterm
FROM TABLE(SEM_MATCH(
'PREFIX ent: <http://www.example.org/enterprise/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
CONSTRUCT
{ ?e foaf:name ?name }
WHERE
{ SELECT ?e (CONCAT(?fname," ",?lname) AS ?name)
WHERE { ?e ent:fname ?fname .
?e ent:lname ?lname }
}',
SEM_Models('enterprise'),
SEM_Rulebases('RDFS'),
null, null));
Named graph data cannot be returned from SPARQL CONSTRUCT queries because, in accordance with the W3C SPARQL specification, only RDF triples are returned, not RDF quads. The FROM, FROM NAMED and GRAPH keywords, however, can be used when matching the query pattern defined in the WHERE clause.
Example 1-27 constructs an RDF graph with ent:name triples from the UNION of named graphs ent:g1 and ent:g2, ent:dateOfBirth triples from named graph ent:g3, and ent:ssn triples from named graph ent:g4.
Example 1-27 SPARQL CONSTRUCT with Named Graphs
SELECT subj$rdfterm, pred$rdfterm, obj$rdfterm
FROM TABLE(SEM_MATCH(
'PREFIX ent: <http://www.example.org/enterprise/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
CONSTRUCT
{ ?e ent:name ?name .
?e ent:dateOfBirth ?dob .
?e ent:ssn ?ssn
}
FROM ent:g1
FROM ent:g2
FROM NAMED ent:g3
FROM NAMED ent:g4
WHERE
{ ?e foaf:name ?name .
GRAPH ent:g3 { ?e ent:dateOfBirth ?dob }
GRAPH ent:g4 { ?e ent:ssn ?ssn }
}',
SEM_Models('enterprise'),
SEM_Rulebases('RDFS'),
null, null));
A short form of CONSTRUCT is supported when the CONSTRUCT template is exactly the same as the WHERE clause. In this case, only the keyword CONSTRUCT is needed, and the graph pattern in the WHERE clause will also be used as a CONSTRUCT template. Example 1-29 shows the short form of Example 1-28.
Example 1-28 SPARQL CONSTRUCT Normal Form
SELECT subj$rdfterm, pred$rdfterm, obj$rdfterm
FROM TABLE(SEM_MATCH(
'PREFIX ent: <http://www.example.org/enterprise/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
CONSTRUCT
{?e foaf:givenName ?fname .
?e foaf:familyName ?lname
}
WHERE
{?e ent:fname ?fname .
?e ent:lname ?lname
}',
SEM_Models('enterprise'),
SEM_Rulebases('RDFS'),
null, null));
Example 1-29 SPARQL CONSTRUCT Short Form
SELECT subj$rdfterm, pred$rdfterm, obj$rdfterm
FROM TABLE(SEM_MATCH(
'PREFIX ent: <http://www.example.org/enterprise/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
CONSTRUCT
WHERE
{?e ent:fname ?fname .
?e ent:lname ?lname
}',
SEM_Models('enterprise'),
SEM_Rulebases('RDFS'),
null, null));
There are two SEM_MATCH query options that influence the behavior of SPARQL CONSTRUCT: CONSTRUCT_UNIQUE=T and CONSTRUCT_STRICT=T. Using the CONSTRUCT_UNIQUE=T query option ensures that only unique RDF triples are returned from the CONSTRUCT query. Using the CONSTRUCT_STRICT=T query option ensures that only valid RDF triples are returned from the CONSTRUCT query. Valid RDF triples are those that have (1) a URI or blank node in the subject position, (2) a URI in the predicate position, and (3) a URI, blank node or RDF literal in the object position. Both of these query options are turned off by default for improved query performance.
1.6.4.1 Typical SPARQL CONSTRUCT Workflow
A typical workflow for SPARQL CONSTRUCT would be to execute a CONSTRUCT query to extract and/or transform RDF triple data from an existing semantic model and then load this data into an existing or new semantic model. The data loading can be accomplished through simple INSERT statements or executing the SEM_APIS.BULK_LOAD_FROM_STAGING_TABLE procedure.
Example 1-30 constructs foaf:name triples from existing ent:fname and ent:lname triples and then bulk loads these new triples back into the original model. Afterward, you can query the original model for foaf:name values.
Example 1-30 SPARQL CONSTRUCT Workflow
-- use create table as select to build a staging table
CREATE TABLE STAB(RDF$STC_sub, RDF$STC_pred, RDF$STC_obj) AS
SELECT subj$rdfterm, pred$rdfterm, obj$rdfterm
FROM TABLE(SEM_MATCH(
'PREFIX ent: <http://www.example.org/enterprise/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
CONSTRUCT
{ ?e foaf:name ?name }
WHERE
{ SELECT ?e (CONCAT(?fname," ",?lname) AS ?name)
WHERE { ?e ent:fname ?fname .
?e ent:lname ?lname }
}',
SEM_Models('enterprise'),
null, null, null));
-- grant privileges on STAB
GRANT SELECT ON STAB TO MDSYS;
-- bulk load data back into the enterprise model
BEGIN
SEM_APIS.BULK_LOAD_FROM_STAGING_TABLE(
model_name=>'enterprise',
table_owner=>'rdfuser',
table_name=>'stab',
flags=>' parallel_create_index parallel=4 ');
END;
/
-- query for foaf:name data
SELECT e$rdfterm, name$rdfterm
FROM TABLE(SEM_MATCH(
'PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT ?e ?name
WHERE { ?e foaf:name ?name }',
SEM_Models('enterprise'),
null, null, null));
See also the W3C SPARQL specification for more information on SPARQL CONSTRUCT queries, specifically: http://www.w3.org/TR/sparql11-query/#construct
1.6.5 Graph Patterns: Support for SPARQL DESCRIBE Syntax
SEM_MATCH allows fully-specified SPARQL DESCRIBE queries in the query parameter.
SPARQL DESCRIBE queries are useful for exploring RDF data sets. You can easily find information about a given resource or set of resources without knowing information about the exact RDF properties used in the data set. A DESCRIBE query returns a "description" of a resource r, where a "description" is the set of RDF triples in the query data set that contain r in either the subject or object position.
Like CONSTRUCT queries, DESCRIBE queries return an RDF graph instead of result bindings. Each DESCRIBE query, therefore, returns the same columns as a CONSTRUCT query (see Section 1.6.4, "Graph Patterns: Support for SPARQL CONSTRUCT Syntax" for a listing of return columns).
SPARQL DESCRIBE queries use the same syntax as SPARQL SELECT queries, except the topmost SELECT clause is replaced with a DESCRIBE clause. A DESCRIBE clause consists of the DESCRIBE keyword followed by a sequence of URIs and/or variables separated by whitespace or the DESCRIBE keyword followed by a single * (asterisk).
A short form of SPARQL DESCRIBE is provided to describe a single constant URI. In the short form, only a DESCRIBE clause is needed. Example 1-31 shows a short form SPARQL DESCRIBE query.
Example 1-31 SPARQL DESCRIBE Short Form
SELECT subj$rdfterm, pred$rdfterm, obj$rdfterm
FROM TABLE(SEM_MATCH(
'DESCRIBE <http://www.example.org/enterprise/emp_1>',
SEM_Models('enterprise'),
null, null, null));
The normal form of SPARQL DESCRIBE specifies a DESCRIBE clause and a SPARQL query pattern, possibly including solution modifiers. Example 1-32 shows a SPARQL DESCRIBE query that describes all employees whose departments are located in New Hampshire.
Example 1-32 SPARQL DESCRIBE Normal Form
SELECT subj$rdfterm, pred$rdfterm, obj$rdfterm
FROM TABLE(SEM_MATCH(
'PREFIX ent: <http://www.example.org/enterprise/>
DESCRIBE ?e
WHERE
{ ?e ent:department ?dept .
?dept ent:locatedIn "New Hampshire" }',
SEM_Models('enterprise'),
null, null, null));
With the normal form of DESCRIBE, as shown in Example 1-32, all resources bound to variables listed in the DESCRIBE clause are described. In Example 1-32, all employees returned from the query pattern and bound to ?e will be described. When DESCRIBE * is used, all visible variables in the query are described. Example 1-33 shows a modified version of Example 1-32 that describes both employees (bound to ?e) and departments (bound to ?dept).
SELECT subj$rdfterm, pred$rdfterm, obj$rdfterm
FROM TABLE(SEM_MATCH(
'PREFIX ent: <http://www.example.org/enterprise/>
DESCRIBE *
WHERE
{ ?e ent:department ?dept .
?dept ent:locatedIn "New Hampshire" }',
SEM_Models('enterprise'),
null, null, null));
Two SEM_MATCH query options affect SPARQL DESCRIBE queries: CONSTRUCT_UNIQUE=T and CONSTRUCT_STRICT=T. CONSTRUCT_UNIQUE=T ensures that duplicate triples are eliminated from the result, and CONSTRUCT_STRICT=T ensures that invalid triples are eliminated from the result. Both of these options are turned off by default. These options are described in more detail in Section 1.6.4, "Graph Patterns: Support for SPARQL CONSTRUCT Syntax".
See also the W3C SPARQL specification for more information on SPARQL DESCRIBE queries, specifically: http://www.w3.org/TR/sparql11-query/#describe
1.6.6 Graph Patterns: Support for SPARQL SELECT Syntax
In addition to curly-brace graph patterns, SEM_MATCH allows fully-specified SPARQL SELECT queries in the query parameter. When using the SPARQL SELECT syntax option, SEM_MATCH supports the following query constructs: BASE, PREFIX, SELECT, SELECT DISTINCT, FROM, FROM NAMED, WHERE, ORDER BY, LIMIT, and OFFSET. Each SPARQL SELECT syntax query must include a SELECT clause and a graph pattern.
A key difference between curly-brace and SPARQL SELECT syntax when using SEM_MATCH is that only variables appearing in the SPARQL SELECT clause are returned from SEM_MATCH when using SPARQL SELECT syntax.
One additional column, SEM$ROWNUM, is returned from SEM_MATCH when using SPARQL SELECT syntax. This NUMBER column can be used to order the results of a SEM_MATCH query so that the result order matches the ordering specified by a SPARQL ORDER BY clause.
Example 1-34 uses the following SPARQL constructs:
-
SPARQL PREFIX clause to specify an abbreviation for the
http://www.example.org/family/andhttp://xmlns.com/foaf/0.1/namespaces -
SPARQL SELECT clause to specify the set of variables to project out of the query
-
SPARQL WHERE clause to specify the query graph pattern
Example 1-34 SPARQL PREFIX, SELECT, and WHERE Clauses
SELECT y, name
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/family/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT ?y ?name
WHERE
{?x :grandParentOf ?y .
?x foaf:name ?name }',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
null, null));
Example 1-34 returns the following columns: y, y$RDFVID, y$_PREFIX, y$_SUFFIX, y$RDFVTYP, y$RDFCLOB, y$RDFLTYP, y$RDFLANG, name, name$RDFVID, name$_PREFIX, name$_SUFFIX, name$RDFVTYP, name$RDFCLOB, name$RDFLTYP, name$RDFLANG, and SEM$ROWNUM.
The SPARQL SELECT clause specifies either (A) a sequence of variables and/or expressions (see Section 1.6.7.1, "Expressions in the SELECT Clause"), or (B) * (asterisk), which projects all variables that appear in a specified triple pattern. Example 1-35 uses the SPARQL SELECT clause to select all variables that appear in a specified triple pattern.
Example 1-35 SPARQL SELECT * (All Variables in Triple Pattern)
SELECT x, y, name
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/family/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT *
WHERE
{?x :grandParentOf ?y .
?x foaf:name ?name }',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
null, null));
The DISTINCT keyword can be used after SELECT to remove duplicate result rows. Example 1-36 uses SELECT DISTINCT to select only the distinct names.
Example 1-36 SPARQL SELECT DISTINCT
SELECT name
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/family/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT DISTINCT ?name
WHERE
{?x :grandParentOf ?y .
?x foaf:name ?name }',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
null, null));
SPARQL FROM and FROM NAMED are used to specify the RDF dataset for a query. FROM clauses are used to specify the set of graphs that make up the default graph, and FROM NAMED clauses are used to specify the set of graphs that make up the set of named graphs. Example 1-37 uses FROM and FROM NAMED to select email addresses and friend of relationships from the union of the <http://www.friends.com/friends> and <http://www.contacts.com/contacts> graphs and grandparent information from the <http://www.example.org/family/Smith> and <http://www.example.org/family/Jones> graphs.
Example 1-37 RDF Dataset Specification Using FROM and FROM NAMED
SELECT x, y, z, email
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/family/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX friends: <http://www.friends.com/>
PREFIX contacts: <http://www.contacts.com/>
SELECT *
FROM friends:friends
FROM contacts:contacts
FROM NAMED :Smith
FROM NAMED :Jones
WHERE
{?x foaf:frendOf ?y .
?x :email ?email .
GRAPH ?g {
?x :grandParentOf ?z }
}',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
null, null));
The SPARQL ORDER BY clause can be used to order the results of SEM_MATCH queries. This clause specifies a sequence of comparators used to order the results of a given query. A comparator consists of an expression composed of variables, RDF terms, arithmetic operators (+, -, *, /), Boolean operators and logical connectives (||, &&, !), comparison operators (<, >, <=, >=, =, !=), and any functions available for use in FILTER expressions.
In a SPARQL ORDER BY clause:
-
Single variable ordering conditions do not require enclosing parenthesis, but parentheses are required for more complex ordering conditions.
-
An optional ASC() or DESC() order modifier can be used to indicate the desired order (ascending or descending, respectively). Ascending is the default order.
-
When using SPARQL ORDER BY in SEM_MATCH, the containing SQL query should be ordered by SEM$ROWNUM to ensure that the desired ordering is maintained through any enclosing SQL blocks.
Example 1-38 uses a SPARQL ORDER BY clause to select all cameras, and it specifies ordering by descending type and ascending total price (price * (1 - discount) * (1 + tax)).
SELECT *
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/electronics/>
SELECT *
WHERE
{?x :price ?p .
?x :discount ?d .
?x :tax ?t .
?x :cameraType ?cType .
}
ORDER BY DESC(?cType) ASC(?p * (1-?d) * (1+?t))',
SEM_Models('electronics'),
SEM_Rulebases('RDFS'),
null, null))
ORDER BY SEM$ROWNUM;
SPARQL LIMIT and SPARQL OFFSET can be used to select different subsets of the query solutions. Example 1-39 uses SPARQL LIMIT to select the five cheapest cameras, and Example 1-40 uses SPARQL LIMIT and OFFSET to select the fifth through tenth cheapest cameras.
SELECT *
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/electronics/>
SELECT ?x ?cType ?p
WHERE
{?x :price ?p .
?x :cameraType ?cType .
}
ORDER BY ASC(?p)
LIMIT 5',
SEM_Models('electronics'),
SEM_Rulebases('RDFS'),
null, null))
ORDER BY SEM$ROWNUM;
SELECT *
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/electronics/>
SELECT ?x ?cType ?p
WHERE
{?x :price ?p .
?x :cameraType ?cType .
}
ORDER BY ASC(?p)
LIMIT 5
OFFSET 5',
SEM_Models('electronics'),
SEM_Rulebases('RDFS'),
null, null))
ORDER BY SEM$ROWNUM;
The SPARQL BASE keyword is used to set a global prefix. All relative IRIs will be resolved with the BASE IRI using the basic algorithm described in Section 5.2 of the Uniform Resource Identifier (URI): Generic Syntax (RFC3986) (http://www.ietf.org/rfc/rfc3986.txt). Example 1-41 is a simple query using full URIs, and Example 1-42 is an equivalent query using a base IRI.
Example 1-41 Query Using Full URIs
SELECT *
FROM TABLE(SEM_MATCH(
'SELECT ?employee ?position
WHERE
{?x <http://www.example.org/employee> ?p .
?p <http://www.example.org/employee/name> ?employee .
?p <http://www.example.org/employee/position> ?pos .
?pos <http://www.example.org/positions/name> ?position
}',
SEM_Models('enterprise'),
null,
null, null))
ORDER BY 1,2;
Example 1-42 Query Using a Base IRI
SELECT *
FROM TABLE(SEM_MATCH(
'BASE <http://www.example.org/>
SELECT ?employee ?position
WHERE
{?x <employee> ?p .
?p <employee/name> ?employee .
?p <employee/position> ?pos .
?pos <positions/name> ?position
}',
SEM_Models('enterprise'),
null,
null, null))
ORDER BY 1,2;
The following order of operations is used when evaluating SPARQL SELECT queries:
-
Graph pattern matching
-
Grouping (see Section 1.6.7.3, "Grouping and Aggregation".)
-
Aggregates (see Section 1.6.7.3, "Grouping and Aggregation")
-
Having (see Section 1.6.7.3, "Grouping and Aggregation")
-
Values (see Section 1.6.7.5, "Value Assignment")
-
Select expressions
-
Order by
-
Projection
-
Distinct
-
Offset
-
Limit
See also the W3C SPARQL specification for more information on SPARQL BASE, PREFIX, SELECT, SELECT DISTINCT, FROM, FROM NAMED, WHERE, ORDER BY, LIMIT, and OFFSET constructs, specifically: http://www.w3.org/TR/sparql11-query/
1.6.7 Graph Patterns: Support for SPARQL 1.1 Constructs
SEM_MATCH supports the following SPARQL 1.1 constructs:
-
An expanded set of functions (all items in Table 1-12, "Built-in Functions Available for FILTER Clause" in Section 1.6.2, "Graph Patterns: Support for Curly Brace Syntax, and OPTIONAL, FILTER, UNION, and GRAPH Keywords")
1.6.7.1 Expressions in the SELECT Clause
Expressions can be used in the SELECT clause to project the value of an expression from a query. A SELECT expression is composed of variables, RDF terms, arithmetic operators (+, -, *, /), Boolean operators and logical connectives (||, &&, !), comparison operators (<, >, <=, >=, =, !=), and any functions available for use in FILTER expressions. The expression must be aliased to a single variable using the AS keyword, and the overall <expression> AS <alias> fragment must be enclosed in parentheses. The alias variable cannot already be defined in the query. A SELECT expression may reference the result of a previous SELECT expression (that is, an expression that appears earlier in the SELECT clause).
Example 1-43 uses a SELECT expression to project the total price for each camera.
Example 1-43 SPARQL SELECT Expression
SELECT *
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/electronics/>
SELECT ?x ((?p * (1-?d) * (1+?t)) AS ?totalPrice)
WHERE
{?x :price ?p .
?x :discount ?d .
?x :tax ?t .
?x :cameraType ?cType .
}',
SEM_Models('electronics'),
SEM_Rulebases('RDFS'),
null, null));
Example 1-44 uses two SELECT expressions to project the discount price with and without sales tax.
Example 1-44 SPARQL SELECT Expressions (2)
SELECT *
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/electronics/>
SELECT ?x ((?p * (1-?d)) AS ?preTaxPrice) ((?preTaxPrice * (1+?t)) AS ?finalPrice)
WHERE
{?x :price ?p .
?x :discount ?d .
?x :tax ?t .
?x :cameraType ?cType .
}',
SEM_Models('electronics'),
SEM_Rulebases('RDFS'),
null, null));
1.6.7.2 Subqueries
Subqueries are allowed with SPARQL SELECT syntax. That is, fully-specified SPARQL SELECT queries may be embedded within other SPARQL SELECT queries. Subqueries have many uses, for example, limiting the number of results from a subcomponent of a query.
Example 1-45 uses a subquery to find the manufacturer that makes the cheapest camera and then finds all other cameras made by this manufacturer.
Example 1-45 SPARQL SELECT Subquery
SELECT *
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/electronics/>
SELECT ?c1
WHERE {?c1 rdf:type :Camera .
?c1 :manufacturer ?m .
{
SELECT ?m
WHERE {?c2 rdf:Type :Camera .
?c2 :price ?p .
?c2 :manufacturer ?m .
}
ORDER BY ASC(?p)
LIMIT 1
}
}',
SEM_Models('electronics'),
SEM_Rulebases('RDFS'),
null, null));
Subqueries are logically evaluated first, and the results are projected up to the outer query. Note that only variables projected in the subquery's SELECT clause are visible to the outer query.
1.6.7.3 Grouping and Aggregation
The GROUP BY keyword used to perform grouping. Syntactically, the GROUP BY keyword must appear after the WHERE clause and before any solution modifiers such as ORDER BY or LIMIT.
Example 1-46 shows a query that uses the GROUP BY keyword to find all the different types of cameras.
Example 1-46 Simple Grouping Query
SELECT *
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/electronics/>
SELECT ?cType
WHERE
{?x rdf:type :Camera .
?x :cameraType ?cType .
}
GROUP BY ?cType',
SEM_Models('electronics'),
SEM_Rulebases('RDFS'),
null, null));
A grouping query partitions the query results into a collection of groups based on a grouping expression (?cType in Example 1-46) such that each result within a group has the same values for the grouping expression. The final result of the grouping operation will include one row for each group.
A grouping expression consists of a sequence of one or more of the following: a variable, an expression, or a value assignment of the form (<expression> as <alias>). Example 1-47 shows a grouping query that uses one of each type of component in the grouping expression.
Example 1-47 Complex Grouping Expression
SELECT *
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/electronics/>
SELECT ?cType ?totalPrice
WHERE
{?x rdf:type :Camera .
?x :cameraType ?cType .
?x :manufacturer ?m .
?x :price ?p .
?x :tax ?t .
}
GROUP BY ?cType (STR(?m)) ((?p*(1+?t)) AS ?totalPrice)',
SEM_Models('electronics'),
SEM_Rulebases('RDFS'),
null, null));
Aggregates are used to compute values across results within a group. An aggregate operates over a collection of values and produces a single value as a result. SEM_MATCH supports the following built-in Aggregates: COUNT, SUM, MIN, MAX, AVG, GROUP_CONCAT and SAMPLE. These aggregates are described in Table 1-14.
Table 1-14 Built-in Aggregates
| Aggregate | Description |
|---|---|
|
AVG(expression) |
Returns the numeric average of expression over the values within a group. |
|
COUNT(* | expression) |
Counts the number of times expression has a bound, non-error value within a group; asterisk (*) counts the number of results within a group. |
|
GROUP_CONCAT(expression [; SEPARATOR = "STRING"]) |
Performs string concatenation of expression over the values within a group. If provided, an optional separator string will be placed between each value. |
|
MAX(expression) |
Returns the maximum value of expression within a group based on the ordering defined by SPARQL ORDER BY. |
|
MIN(expression) |
Returns the minimum value of expression within a group based on the ordering defined by SPARQL ORDER BY. |
|
SAMPLE(expression) |
Returns expression evaluated for a single arbitrary value from a group. |
|
SUM(expression) |
Calculates the numeric sum of expression over the values within a group. |
Example 1-48 uses aggregates to select the maximum, minimum, and average price for each type of camera.
SELECT *
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/electronics/>
SELECT ?cType
(MAX(?p) AS ?maxPrice)
(MIN(?p) AS ?minPrice)
(AVG(?p) AS ?avgPrice)
WHERE
{?x rdf:type :Camera .
?x :cameraType ?cType .
?x :manufacturer ?m .
?x :price ?p .
}
GROUP BY ?cType',
SEM_Models('electronics'),
SEM_Rulebases('RDFS'),
null, null));
If an aggregate is used without a grouping expression, then the entire result set is treated as a single group. Example 1-49 computes the total number of cameras for the whole data set.
Example 1-49 Aggregation Without Grouping
SELECT *
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/electronics/>
SELECT (COUNT(?x) as ?cameraCnt)
WHERE
{ ?x rdf:type :Camera
}',
SEM_Models('electronics'),
SEM_Rulebases('RDFS'),
null, null));
The DISTINCT keyword can optionally be used as a modifier for each aggregate. When DISTINCT is used, duplicate values are removed from each group before computing the aggregate. Syntactically, DISTINCT must appear as the first argument to the aggregate. Example 1-50 uses DISTINCT to find the number of distinct camera manufacturers. In this case, duplicate values of STR(?m) are removed before counting.
Example 1-50 Aggregation with DISTINCT
SELECT *
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/electronics/>
SELECT (COUNT(DISTINCT STR(?m)) as ?mCnt)
WHERE
{ ?x rdf:type :Camera .
?x :manufacturer ?m
}',
SEM_Models('electronics'),
SEM_Rulebases('RDFS'),
null, null));
The HAVING keyword can be used to filter groups based on constraints. HAVING expressions can be composed of variables, RDF terms, arithmetic operators (+, -, *, /), Boolean operators and logical connectives (||, &&, !), comparison operators (<, >, <=, >=, =, !=), aggregates, and any functions available for use in FILTER expressions. Syntactically, the HAVING keyword appears after the GROUP BY clause and before any other solution modifiers such as ORDER BY or LIMIT.
Example 1-51 uses a HAVING expression to find all manufacturers that sell cameras for less than $200.
SELECT *
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/electronics/>
SELECT ?m
WHERE
{ ?x rdf:type :Camera .
?x :manufacturer ?m .
?x :price ?p
}
GROUP BY ?m
HAVING (MIN(?p) < 200)
ORDER BY ASC(?m)',
SEM_Models('electronics'),
SEM_Rulebases('RDFS'),
null, null));
Certain restrictions on variable references apply when using grouping and aggregation. Only group-by variables (single variables in the GROUP BY clause) and alias variables from GROUP BY value assignments can be used in non-aggregate expressions in the SELECT or HAVING clauses.
1.6.7.4 Negation
SEM_MATCH supports two forms of negation in SPARQL query patterns: NOT EXISTS and MINUS. NOT EXISTS can be used to filter results based on whether or not a graph pattern matches, and MINUS can be used to remove solutions based on their relation to another graph pattern.
Example 1-52 uses a NOT EXISTS FILTER to select those cameras that do not have any user reviews.
Example 1-52 Negation with NOT EXISTS
SELECT *
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/electronics/>
SELECT ?x ?cType ?p
WHERE
{?x :price ?p .
?x :cameraType ?cType .
FILTER( NOT EXISTS({?x :userReview ?r}) )
}',
SEM_Models('electronics'),
SEM_Rulebases('RDFS'),
null, null));
Conversely, the EXISTS operator can be used to ensure that a pattern matches. Example 1-53 uses an EXISTS FILTER to select only those cameras that have a user review.
SELECT *
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/electronics/>
SELECT ?x ?cType ?p
WHERE
{?x :price ?p .
?x :cameraType ?cType .
FILTER( EXISTS({?x :userReview ?r}) )
}',
SEM_Models('electronics'),
SEM_Rulebases('RDFS'),
null, null));
Example 1-54 uses MINUS to arrive at the same result as Example 1-52, "Negation with NOT EXISTS". Only those solutions that are not compatible with solutions from the MINUS pattern are included in the result. That is, if a solution has the same values for all shared variables as a solution from the MINUS pattern, it is removed from the result.
Example 1-54 Negation with MINUS
SELECT *
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/electronics/>
SELECT ?x ?cType ?p
WHERE
{?x :price ?p .
?x :cameraType ?cType .
MINUS {?x :userReview ?r}
}',
SEM_Models('electronics'),
SEM_Rulebases('RDFS'),
null, null));
NOT EXISTS and MINUS represent two different styles of negation and have different results in certain cases. One such case occurs when no variables are shared between the negation pattern and the rest of the query. For example, the NOT EXISTS query in Example 1-55, "Negation with NOT EXISTS (2)" removes all solutions because {?subj ?prop ?obj} matches any triple, but the MINUS query in Example 1-56, "Negation with MINUS (2)" removes no solutions because there are no shared variables.
1.6.7.5 Value Assignment
SEM_MATCH provides a variety of ways to assign values to variables in a SPARQL query.
The value of an expression can be assigned to a new variable in three ways: (1) expressions in the SELECT clause, (2) expressions in the GROUP BY clause, and (3) the BIND keyword. In each case, the new variable must not already be defined in the query. After assignment, the new variable can be used in the query and returned in results. As discussed in Section 1.6.7.1, "Expressions in the SELECT Clause", the syntax for value assignment is (<expression> AS <alias>) where alias is the new variable, for example, ((?price * (1+?tax)) AS ?totalPrice).
Example 1-57 uses a nested SELECT expression to compute the total price of a camera and assign the value to a variable (?totalPrice). This variable is then used in a FILTER in the outer query to find cameras costing less than $200.
Example 1-57 Nested SELECT Expression
SELECT *
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/electronics/>
SELECT ?x ?cType ?totalPrice
WHERE
{?x :cameraType ?cType .
{ SELECT ?x ( ((?price*(1+?tax)) AS ?totalPrice )
WHERE { ?x :price ?price .
?x :tax ?tax }
}
FILTER (?totalPrice < 200)
}',
SEM_Models('electronics'),
SEM_Rulebases('RDFS'),
null, null));
The BIND keyword can be used inside a basic graph pattern to assign a value and is syntactically more compact than an equivalent nested SELECT expression. Example 1-58 uses the BIND keyword to expresses a query that is logically equivalent to Example 1-57, "Nested SELECT Expression".
SELECT *
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/electronics/>
SELECT ?x ?cType ?totalPrice
WHERE
{?x :cameraType ?cType .
?x :price ?price .
?x :tax ?tax .
BIND ( ((?price*(1+?tax)) AS ?totalPrice )
FILTER (?totalPrice < 200)
}',
SEM_Models('electronics'),
SEM_Rulebases('RDFS'),
null, null));
Value assignments in the GROUP BY clause can subsequently be used in the SELECT clause, the HAVING clause, and the outer query (in the case of a nested grouping query). Example 1-59 uses a GROUP BY expression to find the maximum number of megapixels for cameras at each price point less than $1000.
Example 1-59 GROUP BY Expression
SELECT *
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/electronics/>
SELECT ?totalPrice (MAX(?mp) as ?maxMP)
WHERE
{?x rdf:type :Camera .
?x :price ?price .
?x :tax ?tax .
GROUP BY ( ((?price*(1+?tax)) AS ?totalPrice )
HAVING (?totalPrice < 1000)
}',
SEM_Models('electronics'),
SEM_Rulebases('RDFS'),
null, null));
In addition to the preceding three ways to assign the value of an expression to a new variable, the VALUES keyword can be used to introduce an unordered solution sequence that is combined with the query results through a join operation. A VALUES block can appear inside a query pattern or at the end of a SPARQL SELECT query block after any solution modifiers. The VALUES construct can be used in subqueries.
Example 1-60 uses the VALUES keyword to constrain the query results to DSLR cameras made by :Company1 or any type of camera made by :Company2. The keyword UNDEF is used to represent an unbound variable in the solution sequence.
SELECT *
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/electronics/>
SELECT ?x ?cType ?m
WHERE
{ ?x rdf:type :Camera .
?x :cameraType ?cType .
?x :manufacturer ?m
}
VALUES (?cType ?m)
{ ("DSLR" :Company1)
(UNDEF :Company2)
}',
SEM_Models('electronics'),
SEM_Rulebases('RDFS'),
null, null));
A simplified syntax can be used for the common case of a single variable. Specifically, the parentheses around the variable and each solution can be omitted. Example 1-61 uses the simplified syntax to constrain the query results to cameras made by :Company1 or :Company2.
Example 1-61 Simplified VALUES Syntax
SELECT *
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/electronics/>
SELECT ?x ?cType ?m
WHERE
{ ?x rdf:type :Camera .
?x :cameraType ?cType .
?x :manufacturer ?m
}
VALUES ?m
{ :Company1
:Company2
}',
SEM_Models('electronics'),
SEM_Rulebases('RDFS'),
null, null));
Example 1-62 also constrains the query results to any camera made by :Company1 or :Company2, but specifies the VALUES block inside the query pattern.
Example 1-62 Inline VALUES Block
SELECT *
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/electronics/>
SELECT ?x ?cType ?m
WHERE
{ VALUES ?m { :Company1 :Company2 }
?x rdf:type :Camera .
?x :cameraType ?cType .
?x :manufacturer ?m
}',
SEM_Models('electronics'),
SEM_Rulebases('RDFS'),
null, null));
1.6.7.6 Property Paths
A SPARQL Property Path describes a possible path between two RDF resources (nodes) in an RDF graph. A property path appears in the predicate position of a triple pattern and uses a regular expression-like syntax to place constraints on the properties (edges) making up a path from the subject of the triple pattern to the object of a triple pattern. Property paths allow SPARQL queries to match arbitrary length paths in the RDF graph and also provide a more concise way to express other graph patterns.
Table 1-15 describes the syntax constructs available for constructing SPARQL Property Paths. Note that iri is either an IRI or a prefixed name, and elt is a property path element, which may itself be composed of other property path elements.
Table 1-15 Property Path Syntax Constructs
| Syntax Construct | Matches |
|---|---|
|
iri |
An IRI or a prefixed name. A path of length 1 (one). |
|
^elt |
Inverse path (object to subject). |
|
!iri or !(iri1 | … | irin) |
Negated property set. An IRI that is not one of irii. |
|
!^iri or !(iri1 | … | irij | ^irij+1 | … | ^irin) |
Negated property set with some inverse properties. An IRI that is not one of irii, nor one of irij+1...irin as reverse paths. !^iri is short for !(^iri). The order of properties and inverse properties is not important. They can occur in mixed order. |
|
(elt) |
A group path elt; brackets control precedence. |
|
elt1 / elt2 |
A sequence path of elt1, followed by elt2. |
|
elt1 | elt2 |
An alternative path of elt1, or elt2 (all possibilities are tried). |
|
elt* |
A path of zero or more occurrences of elt. |
|
elt+ |
A path of one or more occurrences of elt. |
|
elt? |
A path of zero or one occurrence of elt. |
The precedence of the syntax constructs is as follows (from highest to lowest):
-
IRI, prefixed names
-
Negated property sets
-
Groups
-
Unary operators *, ?, +
-
Unary ^ inverse links
-
Binary operator /
-
Binary operator |
Precedence is left-to-right within groups.
Example 1-63 uses a property path to find all Males based on transitivity of the rdfs:subClassOf relationship. A property path allows matching an arbitrary number of consecutive rdfs:subClassOf relations.
Example 1-63 SPARQL Property Path (Using rdfs:subClassOf Relations)
SELECT x, name
FROM TABLE(SEM_MATCH(
'{ ?x foaf:name ?name .
?x rdf:type ?t .
?t rdfs:subClassOf* :Male }',
SEM_Models('family'),
null,
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')
SEM_ALIAS('foaf',' http://xmlns.com/foaf/0.1/')),
null));
Example 1-64 uses a property path to find all of Scott's close friends (those people reachable within two hops using foaf:friendOf or foaf:knows relationships).
Example 1-64 SPARQL Property Path (Using foaf:friendOf or foaf:knows Relationships)
SELECT name
FROM TABLE(SEM_MATCH(
'{ { :Scott (foaf:friendOf | foaf:knows) ?f }
UNION
{ :Scott (foaf:friendOf | foaf:knows)/(foaf:friendOf | foaf:knows) ?f }
?f foaf:name ?name .
FILTER (!sameTerm(?f, :Scott)) }',
SEM_Models('family'),
null,
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/'),
SEM_ALIAS('foaf',' http://xmlns.com/foaf/0.1/')),
null));
Special Considerations for Property Path Operators + and *
In general, truly unbounded graph traversals using the + (plus sign) and * (asterisk) operator can be very expensive. For this reason, a depth-limited version of the + and * operator is used by default, and the default depth limit is 10. In addition, the depth-limited implementation can be run in parallel. The ALL_PP_MAX_DEPTH(n) SEM_MATCH query option or the PP_MAX_DEPTH(n) inline HINT0 query optimizer hint can be used to change the depth-limit setting. To achieve a truly unbounded traversal, you can set a depth limit of less than 1 to fall back to a CONNECT BY-based implementation.
Example 1-65 specifies a maximum depth of 12 for all property path expressions with the ALL_PP_MAX_DEPTH(n) query option value.
Example 1-65 Specifying Property Path Maximum Depth Value
SELECT x, name
FROM TABLE(SEM_MATCH(
'{ ?x foaf:name ?name .
?x rdf:type ?t .
?t rdfs:subClassOf* :Male }',
SEM_Models('family'),
null,
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')
SEM_ALIAS('foaf',' http://xmlns.com/foaf/0.1/')),
null,
null,
' ALL_PP_MAX_DEPTH(12) '));
Query Hints for Property Paths
Other query hints are available to influence the performance of property path queries. The ALLOW_PP_DUP=T query option can be used with * and + queries to allow duplicate results. Allowing duplicate results may return the first rows from a query faster. In addition, ALL_USE_PP_HASH and ALL_USE_PP_NL query options are available to influence the join types used when evaluating property path expressions. Analogous USE_PP_HASH and USE_PP_NL inline HINT0 query optimizer hints can also be used.
Example 1-66 shows an inline HINT0 query optimizer hint that requests a nested loop join for evaluating the property path expression.
Example 1-66 Specifying Property Path Join Hint
SELECT x, name
FROM TABLE(SEM_MATCH(
'{ # HINT0={ USE_PP_NL }
?x foaf:name ?name .
?x rdf:type ?t .
?t rdfs:subClassOf* :Male }',
SEM_Models('family'),
null,
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')
SEM_ALIAS('foaf',' http://xmlns.com/foaf/0.1/')),
null));
1.6.8 Graph Patterns: Support for SPARQL 1.1 Federated Query
SEM_MATCH supports SPARQL 1.1 Federated Query (see http://www.w3.org/TR/sparql11-federated-query/#SPROT). The SERVICE construct can be used to retrieve results from a specified SPARQL endpoint URL. With this capability, you can combine local RDF data (native RDF data or RDF views of relational data) with other, possibly remote, RDF data served by a W3C standards-compliant SPARQL endpoint.
Example 1-67 shows a query that uses a SERVICE clause to retrieve all triples from the SPARQL endpoint available at http://www.example1.org/sparql.
Example 1-67 SPARQL SERVICE Clause to Retrieve All Triples
SELECT s, p, o
FROM TABLE(SEM_MATCH(
'SELECT ?s ?p ?o
WHERE {
SERVICE <http://www.example1.org/sparql>{ ?s ?p ?o }
}',
SEM_Models('electronics'),
null, null, null, null, ' '));
Example 1-68 joins remote RDF data with local RDF data. This example joins camera types ?cType from local model electronics with the camera names ?name from the SPARQL endpoint at http://www.example1.org/sparql.
Example 1-68 SPARQL SERVICE Clause to Join Remote and Local RDF Data
SELECT cType, name
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/electronics/>
SELECT ?cType ?name
WHERE {
?s :cameraType ?cType
SERVICE <http://www.example1.org/sparql>{ ?s :name ?name }
}',
SEM_Models('electronics'),
null, null, null, null, ' '));
This section also contains the following topics:
1.6.8.1 Privileges Required to Execute Federated SPARQL Queries
You need certain database privileges to use the SERVICE construct within SEM_MATCH queries. You should be granted EXECUTE privilege on the SPARQL_SERVICE MDSYS function by a user with DBA privileges: The following example grants this access to a user named RDFUSER:
grant execute on mdsys.sparql_service to rdfuser;
Also, an Access Control List (ACL) should be used to grant the CONNECT privilege to the user attempting a federated query. Example 1-69 creates a new ACL to grant the user RDFUSER the CONNECT privilege and assigns the domain * to the ACL. For more information about ACLs, see Oracle Database PL/SQL Packages and Types Reference.
Example 1-69 Access Control List and Host Assignment
dbms_network_acl_admin.create_acl ( acl => 'rdfuser.xml', description => 'Allow rdfuser to query SPARQL endpoints', principal => 'RDFUSER', is_grant => true, privilege => 'connect' ); dbms_network_acl_admin.assign_acl ( acl => 'rdfuser.xml', host => '*' );
After the necessary privileges are granted, you are ready to execute federated queries from SEM_MATCH
1.6.8.2 SPARQL SERVICE Join Push Down
The SPARQL SERVICE Join Push Down (SERVICE_JPDWN=T) feature can be used to improve the performance of certain SPARQL SERVICE queries. By default, the query pattern within the SERVICE clause is executed first on the remote SPARQL endpoint. The full result of this remote execution is then joined with the local portion of the query. This strategy can result in poor performance if the local portion of the query is very selective and the remote portion of the query is very unselective.
Example 1-70 shows the SPARQL SERVICE Join Push Down feature.
Example 1-70 SPARQL SERVICE Join Push Down
SELECT s, prop, obj
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/electronics/>
SELECT ?s ?prop ?obj
WHERE {
?s rdf:type :Camera .
?s :modelName "Camera 12345"
SERVICE <http://www.example1.org/sparql> { ?s ?prop ?obj }
}',
SEM_Models('electronics'),
null, null, null, null, ' SERVICE_JPDWN=T '));
In Example 1-70, the local portion of the query will return a very small number of rows, but the remote portion of the query is completely unbound and will return the entire remote dataset. When the SERVICE_JPDWN=T option is specified, SEM_MATCH performs a nested-loop style evaluation by first executing the local portion of the query and then executing a modified version of the remote query once for each row returned by the local portion. The remote query is modified with a FILTER clause that effectively performs a substitution for the join variable ?s. For example, if <urn:camera1> and <urn:camera2> are returned from the local portion of Example 1-70 as bindings for ?s, then the following two queries are sent to the remote endpoint: { ?s ?prop ?obj FILTER (?s = <urn:camera1>) } and { s ?prop ?obj FILTER (?s = <urn:camera2>) }.
The SPARQL SERVICE Join Push Down feature cannot be used in a query that contains more than one SERVICE clause.
1.6.8.3 SPARQL SERVICE SILENT
When the SILENT keyword is used in federated queries, errors while accessing the specified remote SPARQL endpoint will be ignored. If the SERVICE SILENT request fails, a single solution with no bindings will be returned.
Example 1-71 uses SERVICE with the SILENT keyword inside an OPTIONAL clause, so that, when connection errors accessing http://www.example1.org/sparql appear, such errors will be ignored and all the rows retrieved from triple ?s :cameratype ?k will be combined with a null value for ?n.
Example 1-71 SPARQL SERVICE with SILENT Keyword
SELECT s, n
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/electronics/>
SELECT ?s ?n
WHERE {
?s :cameraType ?k
OPTIONAL { SERVICE SILENT <http://www.example1.org/sparql>{ ?k :name ?n } }
}',
SEM_Models('electronics'),
null, null, null, null));
1.6.8.4 Using a Proxy Server with SPARQL SERVICE
The following methods are available for sending SPARQL SERVICE requests through an HTTP proxy:
-
Specifying the HTTP proxy that should be used for requests in the current session. This can be done through the SET_PROXY function of UTL_HTTP package. Example 1-72 sets the proxy
proxy.example.comto be used for HTTP requests, excluding those to hosts in the domainexample2.com. (For more information about the SET_PROXY procedure, see Oracle Database PL/SQL Packages and Types Reference.) -
Using the SERVICE_PROXY SEM_MATCH option, which allows setting the proxy address for SPARQL SERVICE request. However, in this case no exceptions can be specified, and all requests are sent to the given proxy server. Example 1-73 shows a SEM_MATCH query where the proxy address
proxy.example.comat port 80 is specified.
1.6.8.5 Accessing SPARQL Endpoints with HTTP Basic Authentication
To allow accessing of SPARQL endpoints with HTTP Basic Authentication, user credentials should be saved in Session Context SDO_SEM_HTTP_CTX. A user with DBA privileges must grant EXECUTE on this context to the user that wishes to use basic authentication. The following example grants this access to a user named RDFUSER:
grant execute on mdsys.sdo_sem_http_ctx to rdfuser;
After the privilege is granted, the user should save the user name and password for each SPARQL Endpoint with HTTP Authentication through functions mdsys.sdo_sem_http_ctx.set_usr and mdsys.sdo_sem_http_ctx.set_pwd. The following example sets a user name and password for the SPARQL endpoint at http://www.example1.org/sparql:
BEGIN
mdsys.sdo_sem_http_ctx.set_usr('http://www.example1.org/sparql','user');
mdsys.sdo_sem_http_ctx.set_pwd('http://www.example1.org/sparql','pwrd');
END;
/
1.6.9 Inline Query Optimizer Hints
In SEM_MATCH, the SPARQL comment construct has been overloaded to allow inline HINT0 query optimizer hints. In SPARQL, the hash (#) character indicates that the remainder of the line is a comment. To associate an inline hint with a particular BGP, place a HINT0 hint string inside a SPARQL comment and insert the comment between the opening curly bracket ({) and the first triple pattern in the BGP. Inline hints enable you to influence the execution plan for each BGP in a query. Example 1-74 shows a query with inline query optimizer hints.
Example 1-74 Inline Query Optimizer Hints
SELECT x, y, hp, cp
FROM TABLE(SEM_MATCH(
'{ # HINT0={ LEADING(t0) USE_NL(?x ?y ?bd) }
?x :grandParentOf ?y . ?x rdf:type :Male . ?x :birthDate ?bd
OPTIONAL { # HINT0={ LEADING(t0 t1) BGP_JOIN(USE_HASH) }
?x :homepage ?hp . ?x :cellPhoneNum ?cp }
}',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
The BGP_JOIN hint influences inter-BGP joins and has the following syntax: BGP_JOIN(<join_type>), where <join_type> is USE_HASH or USE_NL. Example 1-74 uses the BGP_JOIN(USE_HASH) hint to specify that a hash join should be used when joining the OPTIONAL BGP with its parent BGP.
Inline optimizer hints override any hints passed to SEM_MATCH through the options argument. For example, a global ALL_ORDERED hint applies to each BGP that does not specify an inline optimizer hint, but those BGPs with an inline hint use the inline hint instead of the ALL_ORDERED hint.
1.6.10 Full-Text Search
The Oracle-specific orardf:textContains SPARQL FILTER function uses full-text indexes on the MDSYS.RDF_VALUE$ table. This function has the following syntax (where orardf is a built-in prefix that expands to <http://xmlns.oracle.com/rdf/>):
orardf:textContains(variable, pattern)
The first argument to orardf:textContains must be a local variable (that is, a variable present in the BGP that contains the orardf:textContains filter), and the second argument must be a constant plain literal.
For example, orardf:textContains(x, y) returns true if x matches the expression y, where y is a valid expression for the Oracle Text SQL operator CONTAINS. For more information about such expressions, see Oracle Text Reference.
Before using orardf:textContains, you must create an Oracle Text index for the RDF network. To create such an index, invoke the SEM_APIS.ADD_DATATYPE_INDEX procedure as follows:
EXECUTE SEM_APIS.ADD_DATATYPE_INDEX('http://xmlns.oracle.com/rdf/text');
Performance for wildcard searches like orardf:textContains(?x, "%abc%") can be improved by using prefix and substring indexes. You can include any of the following options to the SEM_APIS.ADD_DATATYPE_INDEX procedure:
-
prefix_index=true– for adding prefix index -
prefix_min_length=<number>– minimum length for prefix index tokens -
prefix_max_length=<number>– maximum length for prefix index tokens -
substring_index=true– for adding substring index
For more information about Oracle Text indexing elements, see Oracle Text Reference.
When performing large bulk loads into a semantic network with a text index, the overall load time may be faster if you drop the text index, perform the bulk load, and then re-create the text index. See Section 1.9 for more information about data type indexing.
After creating a text index, you can use the orardf:textContains FILTER function in SEM_MATCH queries. Example 1-75 uses orardf:textContains to find all grandfathers whose names start with the letter A or B.
SELECT x, y, hp, cp
FROM TABLE(SEM_MATCH(
'{ ?x :grandParentOf ?y . ?x rdf:type :Male . ?x :name ?n
FILTER (orardf:textContains(?n, " A% | B% ")) }',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
1.6.11 Spatial Support
RDF Semantic Graph supports storage and querying of spatial geometry data through the OGC GeoSPARQL standard and through Oracle-specific SPARQL extensions. Geometry data can be stored as orageo:WKTLiteral or ogc:wktLiteral typed literals, and geometry data can be queried using several query functions for spatial operations. Spatial indexing for increased performance is also supported.
orageo is a built-in prefix that expands to <http://xmlns.oracle.com/rdf/geo/>, ogc is a built-in prefix that expands to <http://www.opengis.net/ont/geosparql#>, and ogcf is a built-in prefix that expands to <http://www.opengis.net/def/function/geosparql>.
This section covers the following topics:
1.6.11.1 OGC GeoSPARQL Support
RDF Semantic Graph supports the following conformance classes for the OGC GeoSPARQL standard (http://www.opengeospatial.org/standards/geosparql) using well-known text (WKT) serialization and the Simple Features relation family.
-
Core
-
Topology Vocabulary Extension (Simple Features)
-
Geometry Extension (WKT, 1.2.0)
-
Geometry Topology Extension (Simple Features, WKT, 1.2.0)
-
RDFS Entailment Extension (Simple Features, WKT, 1.2.0)
Specifics for representing and querying spatial data using GeoSPARQL are covered in sections that follow this one.
1.6.11.2 Representing Spatial Data in RDF
Spatial geometries can be represented in RDF as orageo:WKTLiteral or ogc:wktLiteral typed literals. Example 1-76 shows the orageo:WKTLiteral encoding for a simple point geometry; Example 1-77 shows the GeoSPARQL encoding for the same point.
Example 1-76 Spatial Point Geometry Represented as orageo:WKTLiteral
"Point(-83.4 34.3)"^^<http://xmlns.oracle.com/rdf/geo/WKTLiteral>
Example 1-77 Spatial Point Geometry Represented as ogc:wktLiteral
"Point(-83.4 34.3)"^^<http://www.opengis.net/ont/geosparql#wktLiteral>
Both orageo:WKTLiteral and ogc:wktLiteral encodings consist of an optional spatial reference system URI, followed by a Well-Known Text (WKT) string that encodes a geometry value. The spatial reference system URI and the WKT string should be separated by a whitespace character. (In this document the term geometry literal is used to refer to both orageo:WKTLiteral and ogc:wktLiteral typed literals.)
Supported spatial reference system URIs have the following form <http://xmlns.oracle.com/rdf/geo/srid/{srid}>, where {srid} is a valid spatial reference system ID from Oracle Spatial and Graph. If a geometry literal value does not include a spatial reference system URI, then the default spatial reference system, WGS84 Longitude-Latitude (URI <http://xmlns.oracle.com/rdf/geo/srid/8307>), is used. The same default spatial reference system is used when geometry literal values are encountered in a query string.
Several geometry types can be represented as geometry literal values, including point, linestring, polygon, polyhedral surface, triangle, TIN, multipoint, multi-linestring, multipolygon, and geometry collection. Up to 500,000 vertices per geometry are supported for two-dimensional geometries.
Example 1-78 shows some RDF spatial data (in N-triple format) encoded using orageo:WKTLiteral values. In this example, the first two geometries (in lot1) use the default coordinate system (SRID 8307), but the other two geometries (in lot2) specify SRID 8265.
Example 1-78 Spatial Data Encoded Using orageo:WKTLiteral Values
# spatial data for lot1 using the default WGS84 Longitude-Latitude spatial reference system <urn:lot1> <urn:hasExactGeometry> "Polygon((-83.6 34.1, -83.6 34.5, -83.2 34.5, -83.2 34.1, -83.6 34.1))"^^<http://xmlns.oracle.com/rdf/geo/WKTLiteral> . <urn:lot1> <urn:hasPointGeometry> "Point(-83.4 34.3)"^^<http://xmlns.oracle.com/rdf/geo/WKTLiteral> . # spatial data for lot2 using the NAD83 Longitude-Latitude spatial reference system <urn:lot2> <urn:hasExactGeometry> "<http://xmlns.oracle.com/rdf/geo/srid/8265> Polygon((-83.6 34.1, -83.6 34.3, -83.4 34.3, -83.4 34.1, -83.6 34.1))"^^<http://xmlns.oracle.com/rdf/geo/WKTLiteral> . <urn:lot2> <urn:hasPointGeometry> "<http://xmlns.oracle.com/rdf/geo/srid/8265> Point(-83.5 34.2)"^^<http://xmlns.oracle.com/rdf/geo/WKTLiteral> .
For more information, see the chapter about coordinate systems (spatial reference systems) in Oracle Spatial and Graph Developer's Guide. See also the material about the WKT geometry representation in the Open Geospatial Consortium (OGC) Simple Features document, available at: http://www.opengeospatial.org/standards/sfa
1.6.11.3 Indexing Spatial Data
Before you can use any of the SPARQL extension functions (introduced in Section 1.6.11.4) to query spatial data, you must create a spatial index on the RDF network by calling the SEM_APIS.ADD_DATATYPE_INDEX procedure.
When you create the spatial index, you must specify the following information:
-
SRID - The ID for the spatial reference system in which to create the spatial index. Any valid spatial reference system ID from Oracle Spatial and Graph can be used as an SRID value.
-
TOLERANCE – The tolerance value for the spatial index. Tolerance is a positive number indicating how close together two points must be to be considered the same point. The units for this value are determined by the default units for the SRID used (for example, meters for WGS84 Long-Lat). Tolerance is explained in detail in Oracle Spatial and Graph Developer's Guide.
-
DIMENSIONS - A text string encoding dimension information for the spatial index. Each dimension is represented by a sequence of three comma-separated values: name, minimum value, and maximum value. Each dimension is enclosed in parentheses, and the set of dimensions is enclosed by an outer parenthesis.
Example 1-79 adds a spatial data type index on the RDF network, specifying the WGS84 Longitude-Latitude spatial reference system, a tolerance value of 10 meters, and the recommended dimensions for the indexing of spatial data that uses this coordinate system. The TOLERANCE, SRID, and DIMENSIONS keywords are case sensitive, and creating a data type index for <http://xmlns.oracle.com/rdf/geo/WKTLiteral> will also index <http://www.opengis.net/ont/geosparql#wktLiteral> geometry literals, and vice versa (that is, creating a data type index for <http://www.opengis.net/ont/geosparql#wktLiteral> will also index <http://xmlns.oracle.com/rdf/geo/WKTLiteral> geometry literals).
Example 1-79 Adding a Spatial Data Type Index on RDF Data
EXECUTE sem_apis.add_datatype_index('http://xmlns.oracle.com/rdf/geo/WKTLiteral', options=>'TOLERANCE=10 SRID=8307 DIMENSIONS=((LONGITUDE,-180,180) (LATITUDE,-90,90))');
No more than one spatial data type index is supported for an RDF network. Geometry literal values stored in the RDF network are automatically normalized to the spatial reference system used for the index, so a single spatial index can simultaneously support geometry literal values from different spatial reference systems. This coordinate transformation is done transparently for indexing and spatial computations. When geometry literal values are returned from a SEM_MATCH query, the original, untransformed geometry is returned.
For more information about spatial indexing, see the chapter about indexing and querying spatial data in Oracle Spatial and Graph Developer's Guide.
1.6.11.4 Querying Spatial Data
Several SPARQL extension functions are available for performing spatial queries in SEM_MATCH. For example, for spatial RDF data, you can find the area and perimeter (length) of a geometry, the distance between two geometries, and the centroid and the minimum bounding rectangle (MBR) of a geometry, and you can check various topological relationships between geometries.
Appendix B contains reference and usage information about the available functions, grouped into two categories:
-
GeoSPARQL functions
-
Oracle-specific functions
1.6.12 Best Practices for Query Performance
This section describes some recommended practices for using the SEM_MATCH table function to query semantic data. It includes the following subsections:
-
Section 1.6.12.1, "FILTER Constructs Involving xsd:dateTime, xsd:date, and xsd:time"
-
Section 1.6.12.2, "Function-Based Indexes for FILTER Constructs Involving Typed Literals"
-
Section 1.6.12.3, "FILTER Constructs Involving Relational Expressions"
-
Section 1.6.12.4, "Optimizer Statistics and Dynamic Sampling"
-
Section 1.6.12.6, "Compression on Systems with OLTP Index Compression"
1.6.12.1 FILTER Constructs Involving xsd:dateTime, xsd:date, and xsd:time
By default, SEM_MATCH complies with the XML Schema standard for comparison of xsd:date, xsd:time, and xsd:dateTime values. According to this standard, when comparing two calendar values c1 and c2 where c1 has an explicitly specified time zone and c2 does not have a specified time zone, c2 is converted into the interval [c2-14:00, c2+14:00]. If c2-14:00 <= c1 <= c2+14:00, then the comparison is undefined and will always evaluate to false. If c1 is outside this interval, then the comparison is defined.
However, the extra logic required to evaluate such comparisons (value with a time zone and value without a time zone) can significantly slow down queries with FILTER constructs that involve calendar values. For improved query performance, you can disable this extra logic by specifying FAST_DATE_FILTER=T in the options parameter of the SEM_MATCH table function. When FAST_DATE_FILTER=T is specified, all calendar values without time zones are assumed to be in Greenwich Mean Time (GMT).
Note that using FAST_DATE_FILTER=T does not affect query correctness when either (1) all calendar values in the data set have a time zone or (2) all calendar values in the data set do not have a time zone.
1.6.12.2 Function-Based Indexes for FILTER Constructs Involving Typed Literals
The evaluation of SEM_MATCH queries involving the FILTER construct often requires executing one or more SQL functions against the RDF_VALUE$ table. For example, the filter (?x < "1929-11-16Z"^^xsd:date) invokes the SEM_APIS.GETV$DATETZVAL function.
Function-based indexes can be used to improve the performance of queries that contain a filter condition involving a typed literal. For example, an xsd:date function-based index may speed up evaluation of the filter (?x < "1929-11-16Z"^^xsd:date).
Convenient interfaces are provided for creating, altering, and dropping these function-based indexes. For more information, see Section 1.9, "Using Data Type Indexes".
Note, however, that the existence of these function-based indexes on the MDSYS.RDF_VALUE$ table can significantly slow down bulk load operations. In many cases it may be faster to drop the indexes, perform the bulk load, and then re-create the indexes, as opposed to doing the bulk load with the indexes in place.
1.6.12.3 FILTER Constructs Involving Relational Expressions
The following recommendations apply to FILTER constructs involving relational expressions:
-
The
sameTermbuilt-in function is more efficient than using=or!=when comparing two variables in a FILTER clause, so (for example) usesameTerm(?a, ?b)instead of(?a = ?b)and use(!sameTerm(?a, ?b))instead of(?a != ?b)whenever possible. -
When comparing values in FILTER expressions, you may get better performance by reducing the use of negation. For example, it is more efficient to evaluate
(?x <= "10"^^xsd:int)than it is to evaluate the expression(!(?x > "10"^^xsd:int)).
1.6.12.4 Optimizer Statistics and Dynamic Sampling
Having sufficient statistics for the query optimizer is critical for good query performance. In general, you should ensure that you have gathered basic statistics for the semantic network using the SEM_PERF.GATHER_STATS procedure (described in Chapter 13).
Due to the inherent flexibility of the RDF data model, static information may not produce optimal execution plans for SEM_MATCH queries. Dynamic sampling can often produce much better query execution plans. Dynamic sampling levels can be set at the session or system level using the optimizer_dynamic_sampling parameter, and at the individual query level using the dynamic_sampling(level) SQL query hint. In general, it is good to experiment with dynamic sampling levels between 3 and 6. For information about estimating statistics with dynamic sampling, see Oracle Database SQL Tuning Guide.
Example 1-80 uses a SQL hint for a dynamic sampling level of 6.
Example 1-80 SQL Hint for Dynamic Sampling
SELECT /*+ DYNAMIC_SAMPLING(6) */ x, y
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y .
?x rdf:type :Male .
?x :birthDate ?bd }',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null, null, '' ));
1.6.12.5 Multi-Partition Queries
The following recommendations apply to the use of multiple semantic models, semantic models plus entailments, and virtual models:
-
If you execute SEM_MATCH queries against multiple semantic models or against semantic models plus entailments, you can probably improve query performance if you create a virtual model (see Section 1.3.8) that contains all the models and entailments you are querying and then query this single virtual model.
-
Use the
ALLOW_DUP=Tquery option. If you do not use this option, then an expensive (in terms of processing) duplicate-elimination step is required during query processing, in order to maintain set semantics for RDF data. However, if you use this option, the duplicate-elimination step is not performed, and this results in significant performance gains.
1.6.12.6 Compression on Systems with OLTP Index Compression
On systems where OLTP index compression is supported (such as Exadata). you can take advantage of the feature to improve the compression ratio for some of the B-tree indexes used by the semantic network.
For example, a DBA can use the following command to change the compression scheme on the MDSYS.RDF_VAL_NAMETYLITLNG_IDX index from prefix compression to OLTP index compression:
SQL> alter index mdsys.RDF_VAL_NAMETYLITLNG_IDX rebuild compress for oltp high;
1.6.12.7 Unbounded Property Path Expressions
A depth-limited search should be used for + and * property path operators whenever possible. The depth-limited implementation for * and + is likely to significantly outperform the CONNECT BY-based implementation in large and/or highly connected graphs. A depth limit of 10 is used by default. For a given graph, depth limits larger than the graph's diameter are not useful. See Section 1.6.7.6, "Property Paths" for more information on setting depth limits.
A backward chaining style inference using rdfs:subClassOf+ for ontologies with very deep class hierarchies may be an exception to this rule. In such cases, unbounded CONNECT BY-based evaluations may perform better than depth-limited evaluations with very high depth limits (for example, 50).
1.6.12.8 Grouping and Aggregation
MIN, MAX and GROUP_CONCAT aggregates require special logic to fully capture SPARQL semantics for input of non-uniform type (for example, MAX(?x)). For certain cases where a uniform input type can be determined at compile time (for example, MAX(STR(?x)) – plain literal input), optimizations for built-in SQL aggregates can be used. Such optimizations generally give an order of magnitude increase in performance. The following cases are optimized:
-
MIN/MAX(<plain literal>)
-
MIN/MAX(<numeric>)
-
MIN/MAX(<dateTime>)
-
GROUP_CONCAT(<plain literal>)
Example 1-81 uses MIN/MAX(<numeric>) optimizations.
1.6.13 Special Considerations When Using SEM_MATCH
The following considerations apply to SPARQL queries executed by RDF Semantic Graph using SEM_MATCH:
-
Value assignment
-
A compile-time error is raised when undefined variables are referenced in the source of a value assignment.
-
-
Grouping and aggregation
-
Non-grouping variables (query variables not used for grouping and therefore not valid for projection) cannot be reused as a target for value assignment.
-
Non-numeric values are ignored by the AVG and SUM aggregates.
-
By default, SEM_MATCH returns no rows for an aggregate query with a graph pattern that fails to match. The W3C specification requires a single, null row for this case. W3C-compliant behavior can be obtained with the
STRICT_AGG_CARD=Tquery option for a small performance penalty.
-
-
ORDER BY
-
When using SPARQL ORDER BY in SEM_MATCH, the containing SQL query should be ordered by SEM$ROWNUM to ensure that the desired ordering is maintained through any enclosing SQL blocks.
-
-
Numeric computations
-
The native Oracle NUMBER type is used internally for all arithmetic operations, and the results of all arithmetic operations are serialized as
xsd:decimal. Note that the native Oracle NUMBER type is more precise than both BINARY_FLOAT and BINARY_DOUBLE. See Oracle Database SQL Language Reference for more information on the NUMBER built-in data type. -
Division by zero causes a runtime error instead of producing an unbound value.
-
-
Negation
-
EXISTS and NOT EXISTS filters that reference potentially unbound variables are not supported in the following contexts:
-
Non-aliased expressions in GROUP BY
-
Input to aggregates
-
Expressions in ORDER BY
-
FILTER expressions within OPTIONAL graph patterns that also reference variables that do not appear inside of the OPTIONAL graph pattern
The first three cases can be realized by first assigning the result of the EXISTS or NOT EXISTS filter to a variable using a BIND clause or SELECT expression.
These restrictions do not apply to EXISTS and NOT EXISTS filters that only reference definitely bound variables.
-
-
-
Blank nodes
-
Blank nodes are not supported within graph patterns.
-
The
BNODE(literal)function returns the same blank node value every time it is called with the same literal argument.
-
-
Property paths
-
Unbounded operators + and * use a 10-hop depth limit by default for performance reasons. This behavior can be changed to a truly unbounded search by setting a depth limit of 0. See Section 1.6.7.6, "Property Paths" for details.
-
-
Long literals (CLOBs)
-
SPARQL functions and aggregates do not support long literals by default.
-
Specifying the
CLOB_EXP_SUPPORT=Tquery option enables long literal support for the following SPARQL functions: IF, COALESCE, STRLANG, STRDT, SUBSTR, STRBEFORE, STRAFTER, CONTAINS, STRLEN, STRSTARTS, STRENDS. -
Specifying the
CLOB_AGG_SUPPORT=Tquery option enables long literal support for the following aggregates: MIN, MAX, SAMPLE, GROUP_CONCAT.
-
-
Canonicalization of RDF literals
-
By default, RDF literals returned from SPARQL functions and constant RDF literals used in value assignment statements (BIND, SELECT expressions, GROUP BY expressions) are canonicalized. This behavior is consistent with the SPARQL 1.1 D-Entailment Regime.
-
Canonicalization can be disabled with the
PROJ_EXACT_VALUES=Tquery option.
-
1.7 Loading and Exporting Semantic Data
To load semantic data into a model, use one or more of the following options:
-
Bulk load or append data into the semantic data store from a staging table, with each row containing the three components -- subject, predicate, and object -- of an RDF triple and optionally a named graph. This is explained in Section 1.7.1.
This is the fastest option for loading large amounts of data; however, it cannot handle triples containing object values with more than 4000 bytes.
-
Batch load using a Java client interface to load or append data from an N-Triple format file into the semantic data store (see Section 1.7.2).
This option is slower than bulk loading, but it handles triples containing object values with more than 4000 bytes. However, this option does not handle named graphs.
-
Load into the application table using SQL INSERT statements that call the SDO_RDF_TRIPLE_S constructor, which results in the corresponding RDF triple, possibly including a graph name, to be inserted into the semantic data store, as explained in Section 1.7.3.
This option is convenient for loading small amounts of data.
To export semantic data, that is, to retrieve semantic data from Oracle Database where the results are in N-Triple or N-Quad format that can be stored in a staging table, use the SQL queries described in Section 1.7.4.
Note:
Effective with Oracle Database Release 12.1, you can export and import a semantic network using the full database export and import features of the Oracle Data Pump utility, as explained in Section 1.7.5, "Exporting or Importing a Semantic Network Using Oracle Data Pump".1.7.1 Bulk Loading Semantic Data Using a Staging Table
You can load semantic data (and optionally associated non-semantic data) in bulk using a staging table. Call the SEM_APIS.LOAD_INTO_STAGING_TABLE procedure (described in Chapter 11) to load the data, and you can have during the load operation to check for syntax correctness. Then, you can call the SEM_APIS.BULK_LOAD_FROM_STAGING_TABLE procedure to load the data into the semantic store from the staging table. (If the data was not parsed during the load operation into the staging table, you must specify the PARSE keyword in the flags parameter when you call the SEM_APIS.BULK_LOAD_FROM_STAGING_TABLE procedure.)
The following example shows the format for the staging table, including all required columns and the required names for these columns, plus the optional RDF$STC_graph column which must be included if one or more of the RDF triples to be loaded include a graph name:
CREATE TABLE stage_table (
RDF$STC_sub varchar2(4000) not null,
RDF$STC_pred varchar2(4000) not null,
RDF$STC_obj varchar2(4000) not null,
RDF$STC_graph varchar2(4000)
);
If you also want to load non-semantic data, specify additional columns for the non-semantic data in the CREATE TABLE statement. The non-semantic column names must be different from the names of the required columns. The following example creates the staging table with two additional columns (SOURCE and ID) for non-semantic attributes.
CREATE TABLE stage_table_with_extra_cols (
source VARCHAR2(4000),
id NUMBER,
RDF$STC_sub varchar2(4000) not null,
RDF$STC_pred varchar2(4000) not null,
RDF$STC_obj varchar2(4000) not null,
RDF$STC_graph varchar2(4000)
);
Note:
For either form of the CREATE TABLE statement, you may want to add the COMPRESS clause to use table compression, which will reduce the disk space requirements and may improve bulk-load performance.Both the invoker and the MDSYS user must have the following privileges: SELECT privilege on the staging table, and INSERT privilege on the application table.
See also the following:
1.7.1.1 Loading the Staging Table
You can load semantic data into the staging table, as a preparation for loading it into the semantic store, in several ways. Some of the common ways are the following:
-
Using Oracle SQL*Loader to load the staging table, as described in Section 1.7.1.1.1
-
Using an external table to load the staging table, as described in Section 1.7.1.1.2
1.7.1.1.1 Loading N-Triple Format Data into a Staging Table Using SQL*Loader
You can use the SQL*Loader utility to parse and load semantic data into a staging table. If you installed the demo files from the Oracle Database Examples media (see Oracle Database Examples Installation Guide), a sample control file is available at $ORACLE_HOME/md/demo/network/rdf_demos/bulkload.ctl. You can modify and use this file if the input data is in N-Triple format.
Objects longer than 4000 bytes cannot be loaded. If you use the sample SQL*Loader control file, triples (rows) containing such long values will be automatically rejected and stored in a SQL*Loader "bad" file. However, you can load these rejected rows by inserting them into the application table using SQL INSERT statements (see Section 1.7.3).
1.7.1.1.2 Loading N-Quad Format Data into a Staging Table Using an External Table
You can use an Oracle external table to load N-Quad format data (extended triple having four components) into a staging table, as follows:
-
Call the SEM_APIS.CREATE_SOURCE_EXTERNAL_TABLE procedure to create an external table, and then use the SQL STATEMENT ALTER TABLE to alter the external table to include the relevant input file name or names. You must have READ and WRITE privileges for the directory object associated with folder containing the input file or files.
-
After you create the external table, grant the MDSYS user SELECT and INSERT privileges on the table.
-
Call the SEM_APIS.LOAD_INTO_STAGING_TABLE procedure to populate the staging table.
-
After the loading is finished, issue a COMMIT statement to complete the transaction.
Rows where the objects and graph URIs (combined) are longer than 4000 bytes will be rejected and stored in a "bad" file. However, you can load these rejected rows by inserting them into the application table using SQL INSERT statements (see Section 1.7.3).
Example 1-82 shows the use of an external table to load a staging table.
Example 1-82 Using an External Table to Load a Staging Table
-- Create a source external table (note: table names are case sensitive)
BEGIN
sem_apis.create_source_external_table(
source_table => 'stage_table_source'
,def_directory => 'DATA_DIR'
,bad_file => 'CLOBrows.bad'
);
END;
/
grant SELECT on "stage_table_source" to MDSYS;
-- Use ALTER TABLE to target the appropriate file(s)
alter table "stage_table_source" location ('demo_datafile.nt');
-- Load the staging table (note: table names are case sensitive)
BEGIN
sem_apis.load_into_staging_table(
staging_table => 'STAGE_TABLE'
,source_table => 'stage_table_source'
,input_format => 'N-QUAD');
END;
/
1.7.1.2 Recording Event Traces During Bulk Loading
If a table named RDF$ET_TAB exists in the invoker's schema and if the MDSYS user has been granted the INSERT and UPDATE privileges on this table, event traces for some of the tasks performed during executions of the SEM_APIS.BULK_LOAD_FROM_STAGING_TABLE procedure will be added to the table. You may find the content of this table useful if you ever need to report any problems in bulk load. The RDF$ET_TAB table must be created as follows:
CREATE TABLE RDF$ET_TAB ( proc_sid VARCHAR2(30), proc_sig VARCHAR2(200), event_name varchar2(200), start_time timestamp, end_time timestamp, start_comment varchar2(1000) DEFAULT NULL, end_comment varchar2(1000) DEFAULT NULL ); GRANT INSERT, UPDATE on RDF$ET_TAB to MDSYS;
1.7.2 Batch Loading N-Triple Format Semantic Data Using the Java API
Note:
The Java classoracle.spatial.rdf.client.BatchLoader described in this section has been deprecated, and it does not support loading of N-Quad data.
You are instead encouraged to use the bulk loading capabilities of the RDF Semantic Graph support for Apache Jena, as described in Section 7.12, "Bulk Loading Using RDF Semantic Graph Support for Apache Jena".
You can perform a batch (bulk) load operation for N-Triple format semantic data using the Java class oracle.spatial.rdf.client.BatchLoader, which is packaged in <ORACLE_HOME>/md/jlib/sdordf.jar. Before performing a batch load operation, ensure that the following are true:
-
The semantic data is in N-Triple format. (Several tools are available for converting RDF/XML to N-Triple format; see the Oracle Technology Network or perform a Web search for information about RDF/XML to N-Triple conversion.)
-
Oracle Database Release 11 or later, with Oracle Spatial and Graph, is installed, and partitioning is enabled.
-
A semantic technologies network, an application table, and its corresponding semantic model have been created in the database.
-
The CLASSPATH definition includes
ojdbc6.jar. -
You are using JDK version 1.5 or later. (You can use the Java version packaged under
<ORACLE_HOME>/jdk/bin.)
To run the oracle.spatial.rdf.client.BatchLoader class, use a command (on a single command line) in the following general form (replacing the sample example database connection information with your own connection information).
-
Linux systems:
java -Ddb.user=scott -Ddb.password=password -Ddb.host=127.0.0.1 -Ddb.port=1522 -Ddb.sid=orcl -classpath ${ORACLE_HOME}/md/jlib/sdordf.jar:${ORACLE_HOME}/jdbc/lib/ojdbc6.jar oracle.spatial.rdf.client.BatchLoader <N-TripleFile> <tablename> <tablespaceName> <modelName> -
Windows systems:
java -Ddb.user=scott -Ddb.password=password -Ddb.host=127.0.0.1 -Ddb.port=1522 -Ddb.sid=orcl -classpath %ORACLE_HOME%\md\jlib\sdordf.jar;%ORACLE_HOME%\jdbc\lib\ojdbc6.jar oracle.spatial.rdf.client.BatchLoader <N-TripleFile> <tablename> <tablespaceName> <modelName>
The values for -Ddb.user and -Ddb.password must correspond either to the owner of the model <modelName> or to a DBA user.
By default, BatchLoader assumes there are at least two columns, a column named ID of type NUMBER and a column named TRIPLE of type SDO_RDF_TRIPLE_S, in the user's application table. However, you can override the default names by using the JVM properties -DidColumn=<idColumnName> and -DtripleColumn=<tripleColumnName>. The ID column is not required; and to prevent BatchLoader from generating a sequence-like identifier in the ID column for each triple inserted, specify the JVM property -DjustTriple=true.
If the application table is not empty and if you want the batch loading to be done in append mode, specify an additional JVM property: -Dappend=true. Moreover, in append mode you might want to choose a different starting value for ID column in user's application table, and to accomplish this you can add the JVM property -DstartID=<startingIntegerValue> to the command line. By default, the ID column starts at 1 and is increased sequentially as new triples are inserted into the application table.
To skip the first n triples in <N-TripleFile>, add the JVM property -Dskip=<numberOfTriplesSkipped> to the command line.
To load an N-Triple file with a character set different from the default, specify the JVM property -Dcharset=<charsetName>. For example, -Dcharset="UTF-8" will recognize UTF-8 encoding. However, for UTF-8 characters to be stored properly in the N-Triple file, the Oracle database must be configured to use a corresponding universal character set, such as AL32UTF8.
The BatchLoader class supports loading an N-Triple file in compressed format. If the <N-TripleFile> has a file extension of .zip or .jar, the file will be uncompressed and loaded at the same time.
1.7.3 Loading Semantic Data Using INSERT Statements
To load semantic data using INSERT statements, the data should be encoded using < > (angle brackets) for URIs, _: (underscore colon) for blank nodes, and " " (quotation marks) for literals. Spaces are not allowed in URIs or blank nodes. Use the SDO_RDF_TRIPLE_S constructor to insert the data, as described in Section 1.5.1. You must have INSERT privilege on the application table.
Note:
If URIs are not encoded with< > and literals with " ", statements will still be processed. However, the statements will take longer to load, since they will have to be further processed to determine their VALUE_TYPE values.The following example includes statements with URIs, a blank node, a literal, a literal with a language tag, and a typed literal:
INSERT INTO nsu_data VALUES (SDO_RDF_TRIPLE_S('nsu', '<http://nature.example.com/nsu/rss.rdf>',
'<http://purl.org/rss/1.0/title>', '"Nature''s Science Update"'));
INSERT INTO nsu_data VALUES (SDO_RDF_TRIPLE_S('nsu', '_:BNSEQN1001A',
'<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>',
'<http://www.w3.org/1999/02/22-rdf-syntax-ns#Seq>'));
INSERT INTO nsu_data VALUES (SDO_RDF_TRIPLE_S('nsu',
'<http://nature.example.com/cgi-taf/dynapage.taf?file=/nature/journal/v428/n6978/index.html>',
'<http://purl.org/dc/elements/1.1/language>', '"English"@en-GB'));
INSERT INTO nature VALUES (SDO_RDF_TRIPLE_S('nsu', '<http://dx.doi.org/10.1038/428004b>',
'<http://purl.org/dc/elements/1.1/date>', '"2004-03-04"^^xsd:date'));
To convert semantic XML data to INSERT statements, you can edit the sample rss2insert.xsl XSLT file to convert all the features in the semantic data XML file. The blank node constructor is used to insert statements with blank nodes. After editing the XSLT, download the Xalan XSLT processor (http://xml.apache.org/xalan-j/) and follow the installation instructions. To convert a semantic data XML file to INSERT statements using your edited version of the rss2insert.xsl file, use a command in the following format:
java org.apache.xalan.xslt.Process –in input.rdf -xsl rss2insert.xsl –out output.nt
1.7.3.1 Loading Data into Named Graphs Using INSERT Statements
To load an RDF triple with a non-null graph name using an INSERT statement, you must append the graph name, enclosed within angle brackets (< >), after the model name and colon (:) separator character, as shown in the following example:
INSERT INTO articles_rdf_data VALUES (99,
SDO_RDF_TRIPLE_S ('articles:<http://examples.com/ns#Graph1>',
'<http://nature.example.com/Article101>',
'<http://purl.org/dc/elements/1.1/creator>',
'"John Smith"'));
1.7.4 Exporting Semantic Data
This section contains the following topics related to exporting semantic data, that is, retrieving semantic data from Oracle Database where the results are in N-Triple or N-Quad format that can be stored in a staging table.
1.7.4.1 Retrieving Semantic Data from an Application Table
Semantic data can be retrieved from an application table using the member functions of SDO_RDF_TRIPLE_S, as shown in Example 1-83.
Example 1-83 Retrieving Semantic Data from an Application Table
-- -- Retrieves model-graph, subject, predicate, and object -- SQL> SELECT a.triple.GET_MODEL() AS model_graph, a.triple.GET_SUBJECT() AS sub, a.triple.GET_PROPERTY() pred, a.triple.GET_OBJECT() obj FROM articles_rdf_data a where id in (2,99); MODEL_GRAPH ------------------------------------------------------------ SUB ------------------------------------------------------------ PRED ------------------------------------------------------------ OBJ ------------------------------------------------------------ ARTICLES <http://nature.example.com/Article1> <http://purl.org/dc/elements/1.1/creator> "Jane Smith" ARTICLES:<http://examples.com/ns#Graph1> <http://nature.example.com/Article101> <http://purl.org/dc/elements/1.1/creator> "John Smith" -- -- Retrieves graph, subject, predicate, and object -- SQL> select (case sep_pos when 0 then NULL else substr(model_graph,sep_pos+1) end) graph, sub, pred, obj from (SELECT instr(a.triple.GET_MODEL(),':') AS sep_pos, a.triple.GET_MODEL() AS model_graph, a.triple.GET_SUBJECT() AS sub, a.triple.GET_PROPERTY() pred, a.triple.GET_OBJECT() obj FROM articles_rdf_data a where id in (2,99)); GRAPH -------------------------------------------------------------------------------- SUB ------------------------------------------------------------ PRED ------------------------------------------------------------ OBJ ------------------------------------------------------------ <http://nature.example.com/Article1> <http://purl.org/dc/elements/1.1/creator> "Jane Smith" <http://examples.com/ns#Graph1> <http://nature.example.com/Article101> <http://purl.org/dc/elements/1.1/creator> "John Smith"
1.7.4.2 Retrieving Semantic Data from an RDF Model
Semantic data can be retrieved from an RDF model using the SEM_MATCH table function (described in Section 1.6), as shown in Example 1-84.
Example 1-84 Retrieving Semantic Data from an RDF Model
--
-- Retrieves graph, subject, predicate, and object
--
SQL> select to_char(g$rdfterm) graph, to_char(x$rdfterm) sub, to_char(p$rdfterm) pred, y$rdfterm obj from table(sem_match('Select ?g ?x ?p ?y FROM NAMED <http://examples.com/ns#Graph1> {GRAPH ?g {?x ?p ?y}}',sem_models('articles'),null,null,null,null,' GRAPH_MATCH_UNNAMED=T PLUS_RDFT=T '));
GRAPH
------------------------------------------------------------
SUB
------------------------------------------------------------
PRED
------------------------------------------------------------
OBJ
---------------------------------------------------------------------------
<http://examples.com/ns#Graph1>
_:m99g3C687474703A2F2F6578616D706C65732E636F6D2F6E73234772617068313Egmb2
<http://purl.org/dc/elements/1.1/creator>
_:m99g3C687474703A2F2F6578616D706C65732E636F6D2F6E73234772617068313Egmb1
<http://examples.com/ns#Graph1>
<http://nature.example.com/Article102>
<http://purl.org/dc/elements/1.1/creator>
_:m99g3C687474703A2F2F6578616D706C65732E636F6D2F6E73234772617068313Egmb1
<http://examples.com/ns#Graph1>
<http://nature.example.com/Article101>
<http://purl.org/dc/elements/1.1/creator>
"John Smith"
<http://nature.example.com/Article1>
<http://purl.org/dc/elements/1.1/creator>
"Jane Smith"
1.7.4.3 Removing Model and Graph Information from Retrieved Blank Node Identifiers
Blank node identifiers retrieved during the retrieval of semantic data can be trimmed to remove the occurrence of model and graph information using the transformations shown in the code excerpt in Example 1-85, which are applicable to VARCHAR2 (for example, subject component) and CLOB (for example, object component) data, respectively.
Example 1-85 Retrieving Semantic Data from an Application Table
--
-- Transformation on column "sub VARCHAR2"
-- holding blank node identifier values
--
Select (case substr(sub,1,2) when '_:' then '_:' || substr(sub,instr(sub,'m',1,2)+1) else sub end) from …
--
-- Transformation on column "obj CLOB"
-- holding blank node identifier values
--
Select (case dbms_lob.substr(obj,2,1) when '_:' then to_clob('_:' || substr(obj,instr(obj,'m',1,2)+1)) else obj end) from …
Example 1-86 shows the results obtained after using these two transformations in Example 1-85 on the sub and obj columns, respectively, using the semantic data retrieval query described in Section 1.7.4.2.
Example 1-86 Results from Applying Transformations from Example 1-85
--
-- Results obtained by applying transformations on the sub and pred cols
--
SQL> select (case substr(sub,1,2) when '_:' then '_:' || substr(sub,instr(sub,'m',1,2)+1) else sub end) sub, pred, (case dbms_lob.substr(obj,2,1) when '_:' then to_clob('_:' || substr(obj,instr(obj,'m',1,2)+1)) else obj end) obj from (select to_char(g$rdfterm) graph, to_char(x$rdfterm) sub, to_char(p$rdfterm) pred, y$rdfterm obj from table(sem_match('Select ?g ?x ?p ?y FROM NAMED <http://examples.com/ns#Graph1> {GRAPH ?g {?x ?p ?y}}',sem_models('articles'),null,null,null,null,' GRAPH_MATCH_UNNAMED=T PLUS_RDFT=T ')));
SUB
------------------------------------------------------------
PRED
------------------------------------------------------------
OBJ
---------------------------------------------------------------------------
_:b2
<http://purl.org/dc/elements/1.1/creator>
_:b1
<http://nature.example.com/Article102>
<http://purl.org/dc/elements/1.1/creator>
_:b1
1.7.5 Exporting or Importing a Semantic Network Using Oracle Data Pump
Effective with Oracle Database Release 12.1, you can export and import a semantic network using the full database export and import features of the Oracle Data Pump utility. The network is moved as part of the full database export or import, where the whole database is represented in an Oracle dump (.dmp) file.
The following usage notes apply to using Data Pump to export or import a semantic network:
-
The target database for an import must have the RDF Semantic Graph software installed, and there cannot be a pre-existing semantic network.
-
Semantic networks using fine-grained access control (triple-level or resource-level OLS or VPD) cannot be exported or imported.
-
Version-enabled semantic networks using Workspace Manager cannot be exported or imported.
-
Semantic document indexes for SEM_CONTAINS (MDSYS.SEMCONTEXT index type) and semantic indexes for SEM_RELATED (MDSYS.SEM_INDEXTYPE index type) must be dropped before an export and re-created after an import.
-
Only default privileges for semantic network objects (those that exist just after object creation) are preserved during export and import. For example, if user A creates semantic model
Mand grants SELECT on MDSYS.RDFM_M to user B, only user A's SELECT privilege on MDSYS.RDFM_M will be present after the import. User B will not have SELECT privilege on MDSYS.RDFM_M after the import. Instead, user B's SELECT privilege will have to be granted again. -
The Data Pump command line option
transform=oid:nmust be used when exporting or importing semantic network data. For example, use a command in the following format:impdp system/<password-for-system> directory=dpump_dir dumpfile=rdf.dmp full=YES version=12 transform=oid:n
For Data Pump usage information and examples, see the relevant chapters in Part I of Oracle Database Utilities.
1.8 Using Semantic Network Indexes
Semantic network indexes are nonunique B-tree indexes that you can add, alter, and drop for use with models and entailments in a semantic network. You can use such indexes to tune the performance of SEM_MATCH queries on the models and entailments in the network. As with any indexes, semantic network indexes enable index-based access that suits your query workload. This can lead to substantial performance benefits, such as in the following example scenarios:
-
If your graph pattern is
'{<John> ?p <Mary>}', you may want to have a usable'CSP' or'SCP'index for the target model or models and on the corresponding entailment, if used in the query. -
If your graph pattern is
'{?x <talksTo> ?y . ?z ?p ?y}', you may want to have a usable semantic network index on the relevant model or models and entailment, withCas the leading key (for example,'C'or'CPS').
However, using semantic network indexes can affect overall performance by increasing the time required for DML, load, and inference operations.
You can create and manage semantic network indexes using the following subprograms:
All of these subprograms have an index_code parameter, which can contain any sequence of the following letters (without repetition): P, C, S, G, M. These letters used in the index_code correspond to the following columns in the SEMM_* and SEMI_* views: P_VALUE_ID, CANON_END_NODE_ID, START_NODE_ID, G_ID, and MODEL_ID.
The SEM_APIS.ADD_SEM_INDEX procedure creates a semantic network index that results in creation of a nonunique B-tree index in UNUSABLE status for each of the existing models and entailments. The name of the index is RDF_LNK_<index_code>_IDX and the index is owned by MDSYS. This operation is allowed only if the invoker has DBA role. The following example shows creation of the PSCGM index with the following key: <P_VALUE_ID, START_NODE_ID, CANON_END_NODE_ID, G_ID, MODEL_ID>.
EXECUTE SEM_APIS.ADD_SEM_INDEX('PSCGM');
After you create a semantic network index, each of the corresponding nonunique B-tree indexes is in the UNUSABLE status, because making it usable can cause significant time and resources to be used, and because subsequent index maintenance operations might involve performance costs that you do not want to incur. You can make a semantic network index usable or unusable for specific models or entailments that you own by calling the SEM_APIS.ALTER_SEM_INDEX_ON_MODEL and SEM_APIS.ALTER_SEM_INDEX_ON_ENTAILMENT procedures and specifying 'REBUILD' or 'UNUSABLE' as the command parameter. Thus, you can experiment by making different semantic network indexes usable and unusable, and checking for any differences in performance. For example, the following statement makes the PSCGM index usable for the FAMILY model:
EXECUTE SEM_APIS.ALTER_SEM_INDEX_ON_MODEL('FAMILY','PSCGM','REBUILD');
Also note the following:
-
Independent of any semantic network indexes that you create, when a semantic network is created, one of the indexes that is automatically created is an index that you can manage by referring to the
index_codeas'PSCGM'when you call the subprograms mentioned in this section. -
When you create a new model or a new entailment, a new nonunique B-tree index is created for each of the semantic network indexes, and each such B-tree index is in the USABLE status.
-
Including the MODEL_ID column in a semantic network index key (by including 'M' in the
index_codevalue) may improve query performance. This is particularly relevant when virtual models are used.
1.8.1 MDSYS.SEM_NETWORK_INDEX_INFO View
Information about all network indexes on models and entailments is maintained in the MDSYS.SEM_NETWORK_INDEX_INFO view, which includes (a partial list) the columns shown in Table 1-16 and one row for each network index.
Table 1-16 MDSYS.SEM_NETWORK_INDEX_INFO View Columns (Partial List)
| Column Name | Data Type | Description |
|---|---|---|
|
NAME |
VARCHAR2(30) |
Name of the RDF model or entailment |
|
TYPE |
VARCHAR2(10) |
Type of object on which the index is built: |
|
ID |
NUMBER |
ID number for the model or entailment, or zero (0) for an index on the network |
|
INDEX_CODE |
VARCHAR2(25) |
Code for the index (for example, |
|
INDEX_NAME |
VARCHAR2(30) |
Name of the index (for example, |
|
LAST_REFRESH |
TIMESTAMP(6) WITH TIME ZONE |
Timestamp for the last time this content was refreshed |
In addition to the columns listed in Table 1-16, the MDSYS.SEM_NETWORK_INDEX_INFO view contains columns from the ALL_INDEXES and ALL_IND_PARTITIONS views (both described in Oracle Database Reference), including:
-
From the ALL_INDEXES view: UNIQUENESS, COMPRESSION, PREFIX_LENGTH
-
From the ALL_IND_PARTITIONS view: STATUS, TABLESPACE_NAME, BLEVEL, LEAF_BLOCKS, NUM_ROWS, DISTINCT_KEYS, AVG_LEAF_BLOCKS_PER_KEY, AVG_DATA_BLOCKS_PER_KEY, CLUSTERING_FACTOR, SAMPLE_SIZE, LAST_ANALYZED
Note that the information in the MDSYS.SEM_NETWORK_INDEX_INFO view may sometimes be stale. You can refresh this information by using the SEM_APIS.REFRESH_SEM_NETWORK_INDEX_INFO procedure.
1.9 Using Data Type Indexes
Data type indexes are indexes on the values of typed literals stored in a semantic network. These indexes may significantly improve the performance of SEM_MATCH queries involving certain types of FILTER expressions. For example, a data type index on xsd:dateTime literals may speed up evaluation of the filter (?x < "1929-11-16T13:45:00Z"^^xsd:dateTime). Indexes can be created for several data types, which are listed in Table 1-17.
Table 1-17 Data Types for Data Type Indexing
| Data Type URI | Oracle Type | Index Type |
|---|---|---|
|
http://www.w3.org/2001/XMLSchema#decimal |
NUMBER |
Non-unique B-tree (creates a single index for all xsd numeric types, including |
|
http://www.w3.org/2001/XMLSchema#string |
VARCHAR2 |
Non-unique B-tree (creates a single index for |
|
http://www.w3.org/2001/XMLSchema#time |
TIMESTAMP WITH TIMEZONE |
Non-unique B-tree |
|
http://www.w3.org/2001/XMLSchema#date |
TIMESTAMP WITH TIMEZONE |
Non-unique B-tree |
|
http://www.w3.org/2001/XMLSchema#dateTime |
TIMESTAMP WITH TIMEZONE |
Non-unique B-tree |
|
http://xmlns.oracle.com/rdf/text |
(Not applicable) |
CTXSYS.CONTEXT |
|
http://xmlns.oracle.com/rdf/geo/WKTLiteral |
SDO_GEOMETRY |
MDSYS.SPATIAL_INDEX |
|
http://www.opengis.net/geosparql#wktLiteral |
SDO_GEOMETRY |
MDSYS.SPATIAL_INDEX |
The suitability of data type indexes depends on your query workload. Data type indexes on xsd data types can be used for filters that compare a variable with a constant value, and are particularly useful when queries have an unselective graph pattern with a very selective filter condition. Appropriate data type indexes are required for queries with spatial or text filters.
While data type indexes improve query performance, overhead from incremental index maintenance can degrade the performance of DML and bulk load operations on the semantic network. For bulk load operations, it may often be faster to drop data type indexes, perform the bulk load, and then re-create the data type indexes.
You can add, alter, and drop data type indexes using the following procedures, which are described in Chapter 11:
Information about existing data type indexes is maintained in the MDSYS.SEM_DTYPE_INDEX_INFO view, which has the columns shown in Table 1-18 and one row for each data type index.
Table 1-18 MDSYS.SEM_DTYPE_INDEX_INFO View Columns
| Column Name | Data Type | Description |
|---|---|---|
|
DATATYPE |
VARCHAR2(51) |
Data type URI |
|
INDEX_NAME |
VARCHAR2(30) |
Name of the index |
|
STATUS |
VARCHAR2(8) |
Status of the index: |
|
TABLESPACE_NAME |
VARCHAR2(30) |
Tablespace for the index |
You can use the HINT0 hint to ensure that data type indexes are used during query evaluation, as shown in Example 1-87, which finds all grandfathers who were born before November 16, 1929.
Example 1-87 Using HINT0 to Ensure Use of Data Type Index
SELECT x, y
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male . ?x :birthDate ?bd
FILTER (?bd <= "1929-11-15T23:59:59Z"^^xsd:dateTime) }',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null, null,
'HINT0={ LEADING(?bd) INDEX(?bd rdf_v$dateTime_idx) }
FAST_DATE_FILTER=T' ));
1.10 Managing Statistics for Semantic Models and the Semantic Network
Statistics are critical to the performance of SPARQL queries and OWL inference against semantic data stored in an Oracle database. Oracle Database Release 11g introduced SEM_APIS.ANALYZE_MODEL, SEM_APIS.ANALYZE_ENTAILMENT, and SEM_PERF.GATHER_STATS to analyze semantic data and keep statistics up to date. These APIs are straightforward to use and they are targeted at regular users who may not care about the internal details about table and partition statistics.
You can export, import, set, and delete model and entailment statistics, and can export, import, and delete network statistics, using the following subprograms:
This section contains the following topics related to managing statistics for semantic models and the semantic network:
1.10.1 Saving Statistics at a Model Level
If queries and inference against an existing model are executed efficiently, as the owner of the model, you can save the statistics of the existing model.
-- Login as the model owner (for example, SCOTT)
-- Create a stats table. This is required.
execute dbms_stats.create_stat_table('scott','rdf_stat_tab');
-- You must grant access to MDSYS
SQL> grant select, insert, delete, update on scott.rdf_stat_tab to MDSYS;
-- Now export the statistics of model TEST
execute sdo_rdf.export_model_stats('TEST','rdf_stat_tab', 'model_stat_saved_on_AUG_10', true, 'SCOTT', 'OBJECT_STATS');
You can also save the statistics of an entailment (entailed graph) by using SEM_APIS.EXPORT_ENTAILMENT_STATS.
execute sem_apis.create_entailment('test_inf',sem_models('test'),sem_rulebases('owl2rl'),0,null);
PL/SQL procedure successfully completed.
execute sem_apis.export_entailment_stats('TEST_INF','rdf_stat_tab', 'inf_stat_saved_on_AUG_10', true, 'SCOTT', 'OBJECT_STATS');
1.10.2 Restoring Statistics at a Model Level
As the owner of a model, can restore the statistics that were previously saved with SEM_APIS.EXPORT_MODEL_STATS. This may be necessary if updates have been applied to this model and statistics have been re-collected. A change in statistics might cause a plan change to existing SPARQL queries, and if such a plan change is undesirable, then an old set of statistics can be restored.
execute sem_apis.import_model_stats('TEST','rdf_stat_tab', 'model_stat_saved_on_AUG_10', true, 'SCOTT', false, true, 'OBJECT_STATS');
You can also restore the statistics of an entailment (entailed graph) by using SEM_APIS.IMPORT_ENTAILMENT_STATS.
execute sem_apis.import_entailment_stats('TEST','rdf_stat_tab', 'inf_stat_saved_on_AUG_10', true, 'SCOTT', false, true, 'OBJECT_STATS');
1.10.3 Saving Statistics at the Network Level
You can save statistics at the network level.
-- First, create a user RDF_ADMIN and assign access to package SEM_PERF to RDF_ADMIN
--
-- As SYS
--
create user RDF_ADMIN identified by RDF_ADMIN;
grant connect, resource, unlimited tablespace to RDF_ADMIN;
grant execute on sem_perf to RDF_ADMIN;
conn RDF_ADMIN/<password>
execute dbms_stats.create_stat_table('RDF_ADMIN','rdf_stat_tab');
grant select, insert, delete, update on RDF_ADMIN.rdf_stat_tab to MDSYS;
--
-- This API call will save the statistics of both MDSYS.RDF_VALUE$ table
-- and MDSYS.RDF_LINK$
--
execute sem_perf.export_network_stats('rdf_stat_tab', 'NETWORK_ALL_saved_on_Aug_10', true, 'RDF_ADMIN', 'OBJECT_STATS');
--
-- Alternatively, you can save statistics of the MDSYS.RDF_VALUE$ table
--
execute sem_perf.export_network_stats('rdf_stat_tab', 'NETWORK_VALUE_TAB_saved_on_Aug_10', true, 'RDF_ADMIN', 'OBJECT_STATS', options=> mdsys.sdo_rdf.VALUE_TAB_ONLY);
--
-- Or, you can save statistics of the MDSYS.RDF_LINK$ table
--
execute sem_perf.export_network_stats('rdf_stat_tab', 'NETWORK_LINK_TAB_saved_on_Aug_10', true, 'RDF_ADMIN', 'OBJECT_STATS', options=> mdsys.sdo_rdf.LINK_TAB_ONLY);
1.10.4 Restoring Statistics at the Network Level
The privileged user from Section 1.10.3 can restore the network level statistics using SEM_PERF.IMPORT_NETWORK_STATS.
conn RDF_ADMIN/<password>
execute sem_perf.import_network_stats('rdf_stat_tab', 'NETWORK_ALL_saved_on_Aug_10', true, 'RDF_ADMIN', false, true, 'OBJECT_STATS');
1.10.5 Setting Statistics at a Model Level
As the owner of a model, you can manually adjust the statistics for this model. (However, before you adjust statistics, you should save the statistics first so that they can be restored if necessary.) The following example sets two metrics: number of rows and number of blocks for the model.
execute sem_apis.set_model_stats('TEST', numrows=>10, numblks=>1,no_invalidate=>false);
You can also set the statistics for the entailment by using SEM_APIS.SET_ENTAILMENT_STATS.
execute sem_apis.set_entailment_stats('TEST_INF', numrows=>10, numblks=>1,no_invalidate=>false);
1.10.6 Deleting Statistics at a Model Level
Removing statistics can also have an impact on execution plans. As owner of a model, you can remove the statistics for the model.
execute sem_apis.delete_model_stats('TEST', no_invalidate=> false);
You can also remove the statistics for the entailment by using SEM_APIS.DELETE_ENTAILMENT_STATS. (However, before you remove statistics of a model or an entailment, you should save the statistics first so that they can be restored if necessary.)
execute sem_apis.delete_entailment_stats('TEST_INF', no_invalidate=> false);
1.11 Quick Start for Using Semantic Data
To work with semantic data in an Oracle database, follow these general steps:
-
Create a tablespace for the system tables. You must be connected as a user with appropriate privileges to create the tablespace. The following example creates a tablespace named RDF_TBLSPACE:
CREATE TABLESPACE rdf_tblspace DATAFILE '/oradata/orcl/rdf_tblspace.dat' SIZE 1024M REUSE AUTOEXTEND ON NEXT 256M MAXSIZE UNLIMITED SEGMENT SPACE MANAGEMENT AUTO;
-
Create a semantic data network.
Creating a semantic data network adds semantic data support to an Oracle database. You must create a semantic data network as a user with DBA privileges, specifying a valid tablespace with adequate space. Create the network only once for an Oracle database.
The following example creates a semantic data network using a tablespace named RDF_TBLSPACE (which must already exist):
EXECUTE SEM_APIS.CREATE_SEM_NETWORK('rdf_tblspace'); -
Connect as the database user under whose schema you will store your semantic data; do not perform the following steps while connected as SYS, SYSTEM, or MDSYS.
-
Create a table to store references to the semantic data. (You do not need to be connected as a user with DBA privileges for this step and the remaining steps.)
This table must contain a column of type SDO_RDF_TRIPLE_S, which will contain references to all data associated with a single model.
The following example creates a table named ARTICLES_RDF_DATA:
CREATE TABLE articles_rdf_data (id NUMBER, triple SDO_RDF_TRIPLE_S);
-
Create a model.
When you create a model, you specify the model name, the table to hold references to semantic data for the model, and the column of type SDO_RDF_TRIPLE_S in that table.
The following command creates a model named ARTICLES, which will use the table created in the preceding step.
EXECUTE SEM_APIS.CREATE_SEM_MODEL('articles', 'articles_rdf_data', 'triple'); -
Where possible, create Oracle database indexes on conditions that will be specified in the WHERE clause of SELECT statements, to provide better performance for direct queries against the application table's SDO_RDF_TRIPLE_S column. (These indexes are not relevant if the SEM_MATCH table function is being used.) The following example creates such indexes:
-- Create indexes on the subjects, properties, and objects -- in the ARTICLES_RDF_DATA table. CREATE INDEX articles_sub_idx ON articles_rdf_data (triple.GET_SUBJECT()); CREATE INDEX articles_prop_idx ON articles_rdf_data (triple.GET_PROPERTY()); CREATE INDEX articles_obj_idx ON articles_rdf_data (TO_CHAR(triple.GET_OBJECT()));
After you create the model, you can insert triples into the table, as shown in the examples in Section 1.12.
1.12 Semantic Data Examples (PL/SQL and Java)
This section contains the following PL/SQL examples:
In addition to the examples in this guide, see the sample code at http://www.oracle.com/technetwork/indexes/samplecode/semantic-sample-522114.html.
1.12.1 Example: Journal Article Information
This section presents a simplified PL/SQL example of model for statements about journal articles. Example 1-88 contains descriptive comments, refer to concepts that are explained in this chapter, and uses functions and procedures documented in Chapter 11.
Example 1-88 Using a Model for Journal Article Information
-- Basic steps:
-- After you have connected as a privileged user and called
-- SEM_APIS.CREATE_SEM_NETWORK to add RDF support,
-- connect as a regular database user and do the following.
-- 1. For each desired model, create a table to hold its data.
-- 2. For each model, create a model (SEM_APIS.CREATE_SEM_MODEL).
-- 3. For each table to hold semantic data, insert data into the table.
-- 4. Use various subprograms and constructors.
-- Create the table to hold data for the model.
CREATE TABLE articles_rdf_data (id NUMBER, triple SDO_RDF_TRIPLE_S);
-- Create the model.
EXECUTE SEM_APIS.CREATE_SEM_MODEL('articles', 'articles_rdf_data', 'triple');
-- Information to be stored about some fictitious articles:
-- Article1, titled "All about XYZ" and written by Jane Smith, refers
-- to Article2 and Article3.
-- Article2, titled "A review of ABC" and written by Joe Bloggs,
-- refers to Article3.
-- Seven SQL statements to store the information. In each statement:
-- Each article is referred to by its complete URI The URIs in
-- this example are fictitious.
-- Each property is referred to by the URL for its definition, as
-- created by the Dublin Core Metadata Initiative.
-- Insert rows into the table.
-- Article1 has the title "All about XYZ".
INSERT INTO articles_rdf_data VALUES (1,
SDO_RDF_TRIPLE_S ('articles','<http://nature.example.com/Article1>',
'<http://purl.org/dc/elements/1.1/title>','"All about XYZ"'));
-- Article1 was created (written) by Jane Smith.
INSERT INTO articles_rdf_data VALUES (2,
SDO_RDF_TRIPLE_S ('articles','<http://nature.example.com/Article1>',
'<http://purl.org/dc/elements/1.1/creator>',
'"Jane Smith"'));
-- Article1 references (refers to) Article2.
INSERT INTO articles_rdf_data VALUES (3,
SDO_RDF_TRIPLE_S ('articles',
'<http://nature.example.com/Article1>',
'<http://purl.org/dc/terms/references>',
'<http://nature.example.com/Article2>'));
-- Article1 references (refers to) Article3.
INSERT INTO articles_rdf_data VALUES (4,
SDO_RDF_TRIPLE_S ('articles',
'<http://nature.example.com/Article1>',
'<http://purl.org/dc/terms/references>',
'<http://nature.example.com/Article3>'));
-- Article2 has the title "A review of ABC".
INSERT INTO articles_rdf_data VALUES (5,
SDO_RDF_TRIPLE_S ('articles',
'<http://nature.example.com/Article2>',
'<http://purl.org/dc/elements/1.1/title>',
'"A review of ABC"'));
-- Article2 was created (written) by Joe Bloggs.
INSERT INTO articles_rdf_data VALUES (6,
SDO_RDF_TRIPLE_S ('articles',
'<http://nature.example.com/Article2>',
'<http://purl.org/dc/elements/1.1/creator>',
'"Joe Bloggs"'));
-- Article2 references (refers to) Article3.
INSERT INTO articles_rdf_data VALUES (7,
SDO_RDF_TRIPLE_S ('articles',
'<http://nature.example.com/Article2>',
'<http://purl.org/dc/terms/references>',
'<http://nature.example.com/Article3>'));
COMMIT;
-- Query semantic data.
SELECT SEM_APIS.GET_MODEL_ID('articles') AS model_id FROM DUAL;
SELECT SEM_APIS.GET_TRIPLE_ID(
'articles',
'<http://nature.example.com/Article2>',
'<http://purl.org/dc/terms/references>',
'<http://nature.example.com/Article3>') AS RDF_triple_id FROM DUAL;
SELECT SEM_APIS.IS_TRIPLE(
'articles',
'<http://nature.example.com/Article2>',
'<http://purl.org/dc/terms/references>',
'<http://nature.example.com/Article3>') AS is_triple FROM DUAL;
-- Use SDO_RDF_TRIPLE_S member functions in queries.
SELECT a.triple.GET_TRIPLE() AS triple
FROM articles_rdf_data a WHERE a.id = 1;
SELECT a.triple.GET_SUBJECT() AS subject
FROM articles_rdf_data a WHERE a.id = 1;
SELECT a.triple.GET_PROPERTY() AS property
FROM articles_rdf_data a WHERE a.id = 1;
SELECT a.triple.GET_OBJECT() AS object
FROM articles_rdf_data a WHERE a.id = 1;
1.12.2 Example: Family Information
This section presents a simplified PL/SQL example of a model for statements about family tree (genealogy) information. Example 1-88 contains descriptive comments, refer to concepts that are explained in this chapter, and uses functions and procedures documented in Chapter 11.
The family relationships in this example reflect the family tree shown in Figure 1-3. This figure also shows some of the information directly stated in the example: Cathy is the sister of Jack, Jack and Tom are male, and Cindy is female.
Example 1-89 Using a Model for Family Information
-- Basic steps:
-- After you have connected as a privileged user and called
-- SEM_APIS.CREATE_SEM_NETWORK to enable RDF support,
-- connect as a regular database user and do the following.
-- 1. For each desired model, create a table to hold its data.
-- 2. For each model, create a model (SEM_APIS.CREATE_SEM_MODEL).
-- 3. For each table to hold semantic data, insert data into the table.
-- 4. Use various subprograms and constructors.
-- Create the table to hold data for the model.
CREATE TABLE family_rdf_data (id NUMBER, triple SDO_RDF_TRIPLE_S);
-- Create the model.
execute SEM_APIS.create_sem_model('family', 'family_rdf_data', 'triple');
-- Insert rows into the table. These express the following information:
-----------------
-- John and Janice have two children, Suzie and Matt.
-- Matt married Martha, and they have two children:
-- Tom (male, height 5.75) and Cindy (female, height 06.00).
-- Suzie married Sammy, and they have two children:
-- Cathy (height 5.8) and Jack (male, height 6).
-- Person is a class that has two subslasses: Male and Female.
-- parentOf is a property that has two subproperties: fatherOf and motherOf.
-- siblingOf is a property that has two subproperties: brotherOf and sisterOf.
-- The domain of the fatherOf and brotherOf properties is Male.
-- The domain of the motherOf and sisterOf properties is Female.
------------------------
-- John is the father of Suzie.
INSERT INTO family_rdf_data VALUES (1,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/John>',
'<http://www.example.org/family/fatherOf>',
'<http://www.example.org/family/Suzie>'));
-- John is the father of Matt.
INSERT INTO family_rdf_data VALUES (2,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/John>',
'<http://www.example.org/family/fatherOf>',
'<http://www.example.org/family/Matt>'));
-- Janice is the mother of Suzie.
INSERT INTO family_rdf_data VALUES (3,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Janice>',
'<http://www.example.org/family/motherOf>',
'<http://www.example.org/family/Suzie>'));
-- Janice is the mother of Matt.
INSERT INTO family_rdf_data VALUES (4,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Janice>',
'<http://www.example.org/family/motherOf>',
'<http://www.example.org/family/Matt>'));
-- Sammy is the father of Cathy.
INSERT INTO family_rdf_data VALUES (5,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Sammy>',
'<http://www.example.org/family/fatherOf>',
'<http://www.example.org/family/Cathy>'));
-- Sammy is the father of Jack.
INSERT INTO family_rdf_data VALUES (6,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Sammy>',
'<http://www.example.org/family/fatherOf>',
'<http://www.example.org/family/Jack>'));
-- Suzie is the mother of Cathy.
INSERT INTO family_rdf_data VALUES (7,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Suzie>',
'<http://www.example.org/family/motherOf>',
'<http://www.example.org/family/Cathy>'));
-- Suzie is the mother of Jack.
INSERT INTO family_rdf_data VALUES (8,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Suzie>',
'<http://www.example.org/family/motherOf>',
'<http://www.example.org/family/Jack>'));
-- Matt is the father of Tom.
INSERT INTO family_rdf_data VALUES (9,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Matt>',
'<http://www.example.org/family/fatherOf>',
'<http://www.example.org/family/Tom>'));
-- Matt is the father of Cindy
INSERT INTO family_rdf_data VALUES (10,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Matt>',
'<http://www.example.org/family/fatherOf>',
'<http://www.example.org/family/Cindy>'));
-- Martha is the mother of Tom.
INSERT INTO family_rdf_data VALUES (11,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Martha>',
'<http://www.example.org/family/motherOf>',
'<http://www.example.org/family/Tom>'));
-- Martha is the mother of Cindy.
INSERT INTO family_rdf_data VALUES (12,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Martha>',
'<http://www.example.org/family/motherOf>',
'<http://www.example.org/family/Cindy>'));
-- Cathy is the sister of Jack.
INSERT INTO family_rdf_data VALUES (13,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Cathy>',
'<http://www.example.org/family/sisterOf>',
'<http://www.example.org/family/Jack>'));
-- Jack is male.
INSERT INTO family_rdf_data VALUES (14,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Jack>',
'<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>',
'<http://www.example.org/family/Male>'));
-- Tom is male.
INSERT INTO family_rdf_data VALUES (15,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Tom>',
'<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>',
'<http://www.example.org/family/Male>'));
-- Cindy is female.
INSERT INTO family_rdf_data VALUES (16,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Cindy>',
'<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>',
'<http://www.example.org/family/Female>'));
-- Person is a class.
INSERT INTO family_rdf_data VALUES (17,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Person>',
'<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>',
'<http://www.w3.org/2000/01/rdf-schema#Class>'));
-- Male is a subclass of Person.
INSERT INTO family_rdf_data VALUES (18,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Male>',
'<http://www.w3.org/2000/01/rdf-schema#subClassOf>',
'<http://www.example.org/family/Person>'));
-- Female is a subclass of Person.
INSERT INTO family_rdf_data VALUES (19,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Female>',
'<http://www.w3.org/2000/01/rdf-schema#subClassOf>',
'<http://www.example.org/family/Person>'));
-- siblingOf is a property.
INSERT INTO family_rdf_data VALUES (20,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/siblingOf>',
'<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>',
'<http://www.w3.org/1999/02/22-rdf-syntax-ns#Property>'));
-- parentOf is a property.
INSERT INTO family_rdf_data VALUES (21,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/parentOf>',
'<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>',
'<http://www.w3.org/1999/02/22-rdf-syntax-ns#Property>'));
-- brotherOf is a subproperty of siblingOf.
INSERT INTO family_rdf_data VALUES (22,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/brotherOf>',
'<http://www.w3.org/2000/01/rdf-schema#subPropertyOf>',
'<http://www.example.org/family/siblingOf>'));
-- sisterOf is a subproperty of siblingOf.
INSERT INTO family_rdf_data VALUES (23,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/sisterOf>',
'<http://www.w3.org/2000/01/rdf-schema#subPropertyOf>',
'<http://www.example.org/family/siblingOf>'));
-- A brother is male.
INSERT INTO family_rdf_data VALUES (24,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/brotherOf>',
'<http://www.w3.org/2000/01/rdf-schema#domain>',
'<http://www.example.org/family/Male>'));
-- A sister is female.
INSERT INTO family_rdf_data VALUES (25,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/sisterOf>',
'<http://www.w3.org/2000/01/rdf-schema#domain>',
'<http://www.example.org/family/Female>'));
-- fatherOf is a subproperty of parentOf.
INSERT INTO family_rdf_data VALUES (26,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/fatherOf>',
'<http://www.w3.org/2000/01/rdf-schema#subPropertyOf>',
'<http://www.example.org/family/parentOf>'));
-- motherOf is a subproperty of parentOf.
INSERT INTO family_rdf_data VALUES (27,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/motherOf>',
'<http://www.w3.org/2000/01/rdf-schema#subPropertyOf>',
'<http://www.example.org/family/parentOf>'));
-- A father is male.
INSERT INTO family_rdf_data VALUES (28,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/fatherOf>',
'<http://www.w3.org/2000/01/rdf-schema#domain>',
'<http://www.example.org/family/Male>'));
-- A mother is female.
INSERT INTO family_rdf_data VALUES (29,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/motherOf>',
'<http://www.w3.org/2000/01/rdf-schema#domain>',
'<http://www.example.org/family/Female>'));
-- Use SET ESCAPE OFF to prevent the caret (^) from being
-- interpreted as an escape character. Two carets (^^) are
-- used to represent typed literals.
SET ESCAPE OFF;
-- Cathy's height is 5.8 (decimal).
INSERT INTO family_rdf_data VALUES (30,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Cathy>',
'<http://www.example.org/family/height>',
'"5.8"^^xsd:decimal'));
-- Jack's height is 6 (integer).
INSERT INTO family_rdf_data VALUES (31,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Jack>',
'<http://www.example.org/family/height>',
'"6"^^xsd:integer'));
-- Tom's height is 05.75 (decimal).
INSERT INTO family_rdf_data VALUES (32,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Tom>',
'<http://www.example.org/family/height>',
'"05.75"^^xsd:decimal'));
-- Cindy's height is 06.00 (decimal).
INSERT INTO family_rdf_data VALUES (33,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Cindy>',
'<http://www.example.org/family/height>',
'"06.00"^^xsd:decimal'));
COMMIT;
-- RDFS inferencing in the family model
BEGIN
SEM_APIS.CREATE_ENTAILMENT(
'rdfs_rix_family',
SEM_Models('family'),
SEM_Rulebases('RDFS'));
END;
/
-- Select all males from the family model, without inferencing.
SELECT m
FROM TABLE(SEM_MATCH(
'{?m rdf:type :Male}',
SEM_Models('family'),
null,
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
-- Select all males from the family model, with RDFS inferencing.
SELECT m
FROM TABLE(SEM_MATCH(
'{?m rdf:type :Male}',
SEM_Models('family'),
SDO_RDF_Rulebases('RDFS'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
-- General inferencing in the family model
EXECUTE SEM_APIS.CREATE_RULEBASE('family_rb');
INSERT INTO mdsys.semr_family_rb VALUES(
'grandparent_rule',
'(?x :parentOf ?y) (?y :parentOf ?z)',
NULL,
'(?x :grandParentOf ?z)',
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')));
COMMIT;
-- Because a new rulebase has been created, and it will be used in the
-- entailment, drop the preceding entailment and then re-create it.
EXECUTE SEM_APIS.DROP_ENTAILMENT ('rdfs_rix_family');
-- Re-create the entailment.
BEGIN
SEM_APIS.CREATE_ENTAILMENT(
'rdfs_rix_family',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'));
END;
/
-- Select all grandfathers and their grandchildren from the family model,
-- without inferencing. (With no inferencing, no results are returned.)
SELECT x grandfather, y grandchild
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male}',
SEM_Models('family'),
null,
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
-- Select all grandfathers and their grandchildren from the family model.
-- Use inferencing from both the RDFS and family_rb rulebases.
SELECT x grandfather, y grandchild
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male}',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
-- Set up to find grandfathers of tall (>= 6) grandchildren
-- from the family model, with RDFS inferencing and
-- inferencing using the "family_rb" rulebase.
UPDATE mdsys.semr_family_rb SET
antecedents = '(?x :parentOf ?y) (?y :parentOf ?z) (?z :height ?h)',
filter = '(h >= ''6'')',
aliases = SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/'))
WHERE rule_name = 'GRANDPARENT_RULE';
-- Because the rulebase has been updated, drop the preceding entailment,
-- and then re-create it.
EXECUTE SEM_APIS.DROP_ENTAILMENT ('rdfs_rix_family');
-- Re-create the entailment.
BEGIN
SEM_APIS.CREATE_ENTAILMENT(
'rdfs_rix_family',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'));
END;
/
-- Find the entailment that was just created (that is, the
-- one based on the specified model and rulebases).
SELECT SEM_APIS.LOOKUP_ENTAILMENT(SEM_MODELS('family'),
SEM_RULEBASES('RDFS','family_rb')) AS lookup_entailment FROM DUAL;
-- Select grandfathers of tall (>= 6) grandchildren, and their
-- tall grandchildren.
SELECT x grandfather, y grandchild
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male}',
SEM_Models('family'),
SEM_RuleBases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
1.13 Software Naming Changes Since Release 11.1
Because the support for semantic data has been expanded beyond the original focus on RDF, the names of many software objects (PL/SQL packages, functions and procedures, system tables and views, and so on) have been changed as of Oracle Database Release 11.1. In most cases, the change is to replace the string RDF with SEM. although in some cases it may be to replace SDO_RDF with SEM.
All valid code that used the pre-Release 11.1 names will continue to work; your existing applications will not be broken. However, it is suggested that you change old applications to use new object names, and you should use the new names for any new applications. This manual will document only the new names.
Table 1-19 lists the old and new names for some objects related to support for semantic technologies, in alphabetical order by old name.
Table 1-19 Semantic Technology Software Objects: Old and New Names
| Old Name | New Name |
|---|---|
|
RDF_ALIAS data type |
SEM_ALIAS |
|
RDF_MODEL$ view |
SEM_MODEL$ |
|
RDF_RULEBASE_INFO view |
SEM_RULEBASE_INFO |
|
RDF_RULES_INDEX_DATASETS view |
SEM_RULES_INDEX_DATASETS |
|
RDF_RULES_INDEX_INFO view |
SEM_RULES_INDEX_INFO |
|
RDFI_rules-index-name view |
SEMI_rules-index-name |
|
RDFM_model-name view |
SEMM_model-name |
|
RDFR_rulebase-name view |
SEMR_rulebase-name |
|
SDO_RDF package |
SEM_APIS |
|
SDO_RDF_INFERENCE package |
SEM_APIS |
|
SDO_RDF_MATCH table function |
SEM_MATCH |
|
SDO_RDF_MODELS data type |
SEM_MODELS |
|
SDO_RDF_RULEBASES data type |
SEM_RULEBASES |
1.14 For More Information About RDF Semantic Graph
For more information about RDF Semantic Graph support and related topics, you may find the following resources helpful:
-
Oracle Spatial and Graph RDF Semantic Graph page (OTN), which includes links for downloads, technical and business white papers, a discussion forum, and other sources of information:
http://www.oracle.com/technetwork/database/options/spatialandgraph/overview/rdfsemantic-graph-1902016.html -
World Wide Web Consortium (W3C) RDF Primer:
http://www.w3.org/TR/rdf-primer/ -
World Wide Web Consortium (W3C) OWL Web Ontology Language Reference:
http://www.w3.org/TR/owl-ref/