2 Getting Started with the DMU
This chapter introduces the Database Migration Assistant for Unicode (DMU) and describes the basic workflow of migrating a character set using this utility.
This chapter contains the following sections:
Using the Database Migration Assistant for Unicode: A Roadmap
This section provides an overview of the tasks involved in working with the DMU.
To work with the Database Migration Assistant for Unicode:
-
Review the requirements.
Ensure that your environment meets the requirements to work successfully with the DMU.
See "Overview of Database Requirements", "Overview of Java Runtime Requirements", and "Overview of DMU Security Considerations".
-
Perform basic preparatory tasks, such as installing the DMU, reviewing the main user interface, creating a database connection, reviewing the user interface, and installing the DMU repository.
See "Installing the DMU", "Creating a Database Connection", "Installing the Migration Repository", and "Introduction to the DMU User Interface".
-
Scan the database to discover any possible problems that could prevent a successful migration to Unicode.
-
Cleanse the database of the possible problems that you discovered during the scanning phase.
See "Cleansing the Data".
-
Convert the database to Unicode.
-
Validate the database to verify that the character set is now Unicode and contains no exceptional data.
Introduction to the DMU Interface and Navigation
From the DMU home page, you can perform the basic tasks associated with migrating a database to Unicode.
This is the page that loads when you click the DMU icon. See "Introduction to the DMU User Interface".
You can access context-sensitive online help by clicking the Help link displayed at the top of every page. On any help page, click Help or press the F1 key.
Navigational features of the DMU include the following:
-
Subpage links at the top of the page. These links take you to the various subpages that organize management tasks into distinct categories.
-
Drill-down links that provide increasing levels of detail.
Overview of Requirements and Security Considerations
This section describes requirements and restrictions you should consider when using the Database Migration Assistant for Unicode, as well as the first steps you must take to start the utility.
Overview of Database Requirements
A database must meet certain requirements to be supported by the DMU. These requirements are:
-
The release of Oracle Database must be 10.2.0.4, 10.2.0.5, 11.1.0.7, 11.2.0.1, or later. Check the latest version of the DMU release notes for any additional patches that must be installed in the database. The release notes also list further database releases that are supported with appropriate patches.
-
The database character set must be ASCII-based, so, for example, databases running on the EBCDIC-based platforms IBM z/OS and Fujitsu BS2000 are not supported.
-
The
SYS.DBMS_DUMA_INTERNALpackage must be installed in the database.This package is available as part of the database installation. It must be created manually by running the script
?/rdbms/admin/prvtdumi.plbfrom the Oracle home of the database. You must log in asSYSDBAto run the script. -
Oracle Database Vault must be disabled before starting the migration process, because DMU has not been certified to work with it enabled.
-
The database must be opened in read/write mode.
Additional requirements pertain to databases that the DMU should convert. Without meeting these requirements, the DMU can still be used for scanning and cleansing the database. These requirements are:
-
All database objects, including objects created by standard PL/SQL packages, such as
DBMS_RULE,DBMS_DATA_MINING, orDBMS_WM, must be named using only standard characters from the ASCII character set. Similarly, expressions ofCHECKconstraints, virtual columns and other database features must be specified only using those characters. In other words, the data dictionary of the database cannot contain non-ASCII characters. However, there is some character data in the data dictionary in which non-ASCII characters are allowed.See "Converting Data Dictionary Tables" for more details.
-
No OLAP analytical workspaces, other than predefined system workspaces and certain predefined Oracle Applications workspaces, can exist in the database.
-
No flashback data archives can exist in the database.
-
No data to be converted can reside in a read-only or offline tablespace.
-
Neither cluster key columns nor partitioning key columns can be defined with character length semantics.
-
No convertible data can be present in tables in the recycle bin.
-
No convertible data can be present in a reference partitioning key column.
This release of the DMU supports the migration of pluggable databases (PDBs) in Oracle Database 12c. In order to convert a PDB using the DMU in a container database (CDB), the root container's character set must be the same as the migration target character set (AL32UTF8 or UTF8). When this requirement is not met, the DMU can still be used for scanning and cleansing PDBs but the conversion operation will be disallowed.
This release of the DMU also supports the migration of Oracle E-Business Suite and PeopleSoft databases to Unicode. The migration workflow is mostly the same as that of a regular database instance. Note that you should not perform any data cleansing actions that require modifying the database schema of Oracle E-Business Suite or PeopleSoft applications since such modifications will not be supported by Oracle. In addition, this release of the DMU does not support migrating databases for PeopleSoft Application versions older than 9.0 or PeopleTools versions older than 8.48.
Overview of Java Runtime Requirements
The Java JDK 1.6 or later must be available on the host running the DMU. The DMU will ask for the location of the Java Runtime executable file (java.exe or java, depending on the platform) the first time it is started.
From the Java SE download page on http://www.oracle.com, you can download the newest Java JDK for Linux, Solaris, and Microsoft Windows operating systems for Intel x86, Intel x64, Intel Itanium, and SPARC processors. Look for the installation instructions for your platform on the relevant Oracle Technology Network documentation page at http://www.oracle.com/technetwork/java/javase/downloads/index.html.
For other platforms, such as Hewlett-Packard HP/US or IBM AIX, visit the vendor's website.
Overview of DMU Security Considerations
This release of the Database Migration Assistant for Unicode requires that the database users connecting to a database have the SYSDBA privilege.
As such, a user should not grant any privileges for the migration repository database objects to any other database users. This applies to any object with a name starting with DUM$ or DBMS_DUMA.
If the DMU is installed on a shared workstation or on a server, you ensure that only the owning operating system user can modify the installed files. This security measure prevents malicious users from modifying the executable files to take advantage of the fact that the DMU connects to a database with the SYSDBA privilege. The modified utility could compromise the database security by running unexpected SQL statements with administrative privileges.
Review Your Preparations for Migration
Before you start the migration process, collect the following information about your database and its use by applications to help you set up the DMU properly:
-
Is your database supported by the DMU?
Verify that the version of your database software is supported by the DMU as described in "Overview of Database Requirements". The platform on which the database is installed must be ASCII-based (that is, not IBM z/OS or Fujitsu BS2000). Your database must not have Oracle Database Vault installed.
-
What is the target character set?
You have to decide if the target character set of the migration is AL32UTF8 or UTF8. Oracle recommends AL32UTF8, which is a proper implementation of the UTF-8 encoding form of the Unicode Standard. The DMU supports migration to the older character set UTF8 for databases that must support database client software based on Oracle 8i Client libraries, or that must support applications certified with UTF8 but not with AL32UTF8, for example, Oracle Applications Release 11i. The UTF8 character set, despite its name, is an implementation of the CESU-8 compatibility encoding form of the Unicode Standard. CESU-8 is very similar to UTF-8 except for the way the supplementary characters are stored (that is, characters with Unicode code points U+010000 and higher). Oracle does not generally update the definition of UTF8 to synchronize it with the newest versions of the Unicode Standard, while Oracle does update the definition of AL32UTF8.
-
Which languages and character sets can be stored in the database?
The very nature of character set encodings and the very nature of character storage in an Oracle database make it impossible to automatically and precisely recognize what language in what character set is represented by a given sequence of bytes in a column value. The DMU scanning process can tell if there are bytes in a character value that are invalid in the declared character set of this value, but not more. If almost all bytes of the declared character set are assigned to single-byte codes of some characters, such as the case of CL8MSWIN1251, which defines all bytes except 0x98, then virtually any sequence of bytes declared as encoded in this character set will appear as valid to the scanning process. Therefore, even if an application uses the pass-through configuration to store data in the database that it interprets in a character set different from the database character set (see "Invalid Binary Storage Representation of Data") the DMU might not see any invalid codes and it might not signal the mismatch between the real (application) character set of the data and the declared database character set. Hence, it is very important that you research, for example, by asking application developers and administrators, what languages or character sets are most probably stored in your database. This will help you to manually analyze the contents of the database, if necessary, to supplement the automatic analysis by the DMU.
-
Which columns might contain data in foreign languages?
If your database contains data mainly in one language and only a few table columns might contain other languages, for example foreign customer names and street addresses, a list of all such columns facilitates the manual search for invalid data stored in the pass-through configuration, if the existence of such data becomes probable after analysis of the information gathered in the previous list item.
-
Which character columns might contain binary data?
Some applications might connect to your database in the pass-through configuration and use character columns to store data that is binary in nature, such as text encrypted without using the Transparent Data Encryption feature of the database, images, text in a binary format of a word processor, and so on. Obtain a list of those applications from application developers or administrators to further help you analyze the contents of your database.
See "Cleansing Scenario 3: Cleansing Invalid Representation Issues" for information about resolving invalid binary representation issues using the collected information.
-
What is the real character set of your database?
Determine if the character data in your database is actually to be interpreted in a particular common character set of the clients connecting to database and not in the declared database character set. To improve the effectiveness and accuracy of the analysis that you perform with the help of the DMU to verify that the database can be converted to Unicode.
One way to determine if the real character set of your database differs from the declared database character set is to look for the following characteristics:
-
The database (declared) character set is US7ASCII, or WE8ISO8859P1, or WE8ISO8859P15.
-
The client character set, declared in the
NLS_LANGclient setting, is the same as the database character set. If theNLS_LANGis not specified at all, the client character set defaults to US7ASCII.NLS_LANGaffects only C or C++ clients connecting through an OCI API. Java clients connecting through a JDBC API are always UTF8 clients. -
All database client software runs on the Microsoft Windows platform and works in one of the Windows character sets, which are also known as ANSI Code Pages. This character set depends on the language version of Windows: WE8MSWIN1252 – US and Western European versions, EE8MSWIN1250 – Central European versions (for example, Polish), CL8MSWIN1251 – Cyrillic versions (for example, Russian), AR8MSWIN1256 – Arabic version, and so on.
This Microsoft Windows character set common to all clients is the real database character set that was to be identified.
If your database is used in a correct character set configuration, that is, the
NLS_LANGsetting always correctly corresponds to the real character set of the database clients, the real character set of the database is its declared character set. -
-
What is the connection information for your database?
To migrate a database with the DMU, you must have the
SYSDBAprivilege and the required connection credentials (user name and password). If the database to be migrated is a pluggable database (PDB) in Oracle Database 12c, you can connect as a user with theSYSDBAprivilege in the local PDB for scanning and cleansing operations but you must connect as theSYSuser or a common user with theSYSDBAprivilege in both the local PDB and the CDB for converting the database to Unicode.You need to know the host name or IP address of the database server, the port number on which the database listener listens for connection requests, and the service name of the database. For performance reasons, Oracle recommends that you connect to a service that is configured for dedicated connections, that it, not using the Shared Server feature.
After you have collected the preceding information, you can install the DMU.
See Also:
Oracle Database Security Guide for further security considerationsPerforming First Tasks With the DMU
The basic introductory steps are:
Installing the DMU
Before installing the DMU, always download the current release notes available for the DMU version you are using. Oracle recommends that the DMU be run on the database server host or on a workstation connected to the database server host with a fast and reliable local area network.
The DMU does not come with an installer. Install the utility by uncompressing the installation file into a directory of your choice.
-
To install the DMU, uncompress the downloaded archive file to any directory on the host on which you want to run the DMU.
-
After you have uncompressed the archive file, ensure that the DMU files are writable only to you and other authorized operating system users. This is very important because unprivileged users with access to the DMU host could modify the DMU files to make the DMU execute arbitrary SQL statements when the DMU is later started with
SYSDBAcredentials. Such SQL statements could compromise database security. -
After you have installed the DMU, initialize the database for the migration process with the DMU.
Creating a Database Connection
You must create a connection to the database that you want to analyze or migrate.
To create a database connection:
-
Before you can start migrating a database with the DMU, you must provide database connection details to the tool. To do this, right-click the Databases node in the Navigator pane to open the context menu, or open the File menu from the menu bar, and select New Database Connection. The Create Database Connection dialog box, shown in Figure 2-1 is displayed. In this dialog, enter connection details, such as login ID, password, host name, port number, and the database service name.
Figure 2-1 Creating a Database Connection
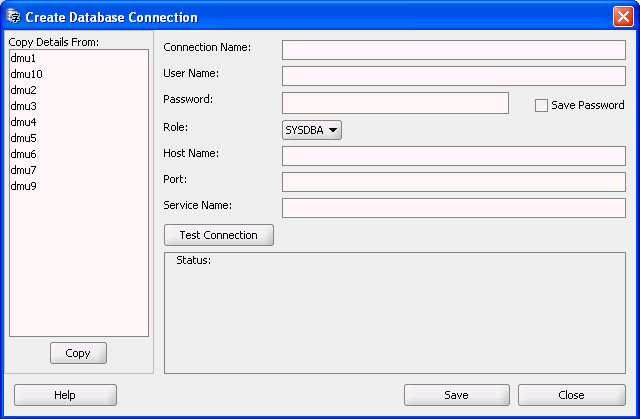
Description of "Figure 2-1 Creating a Database Connection"
-
Enter the following information to define a connection:
-
Connection Name
Give a descriptive name to the connection so that you can easily identify to which database the DMU is connected.
-
User Name
Specify a database user name to use for authentication with the database. In this release, DMU requires the user to have the
SYSDBAprivilege. -
Password
Specify the password for the database user.
-
Role
In this DMU release, only the
SYSDBArole is supported. -
Host Name
Specify the DNS name or the IP address of the database host.
-
Port
Specify the TCP/IP port on which the Net Services (TNS) listener listens for database connection requests.
-
Service Name
Specify the service name of the database instance to which you want to connect.
If you select the Save Password check box, the password you specify will be saved along with other connection details in an obfuscated form in a configuration file in your user directory. Because obfuscation is a reversible operation, use this feature only for passwords to test databases with no production data or only on very well protected hosts. Ensure that the configuration files storing your preferences and connection information are readable only by you. On UNIX platforms, the files are in the directory
$HOME/.dmu/. On Microsoft Windows, the files are in the directory%USERPROFILE%\Application Data\DMU\. Otherwise, you risk compromising the security of your database. If you deselect the Save Password check box, you will be prompted for the password each time you open the connection. -
You can test the connection by clicking Test Connection. If the connection can be established, the Status box will show "Success". Otherwise, it will show an error message describing the connection problem. You can create the connection and close the dialog box by clicking Save.
After a connection has been created, a new database node with the name of the connection is added to the Navigator pane. You can open the node, that is, connect to the database, by right-clicking it and choosing Connect from the context menu. Only one connection can be open in the DMU at the same time, thus the DMU will ask you for permission to close any currently open connection before it will open a new one.
You can change the details of an existing connection, such as user name or host name, by right-clicking the corresponding database node and choosing Connection Details from the context menu. The Modify Database Connection dialog box that is shown has the same elements as the Create Database Connection dialog box.
You can rename a connection by selecting Rename Connection or delete a connection by selecting Delete from the context menu of the corresponding database node. The Connection Details, Rename Connection, and Delete menu items are available in the context menu of a database node only if the node is not currently connected.
Installing the Migration Repository
The DMU uses a repository to manage the information necessary for each step of the migration. Repository contents include items such as objects to be processed, details on data that had an error flagged, and the progress of a scan or a conversion. For any database without a migration repository, an automatic repository creation wizard begins each time you connect to that database. You can also start the wizard from the DMU user interface.
To install the Migration Repository:
-
If you connect to a database for the first time, the DMU automatically prompts you to install the repository. If you are not prompted to install the repository, you can install it by right-clicking the database you want to use, and selecting Configure DMU Repository. You can also select Configure DMU Repository from the Migration menu. In all of these cases, the Repository Configuration Wizard appears. Figure 2-2 shows how it appears.
Figure 2-2 Repository Configuration Wizard - Select Task
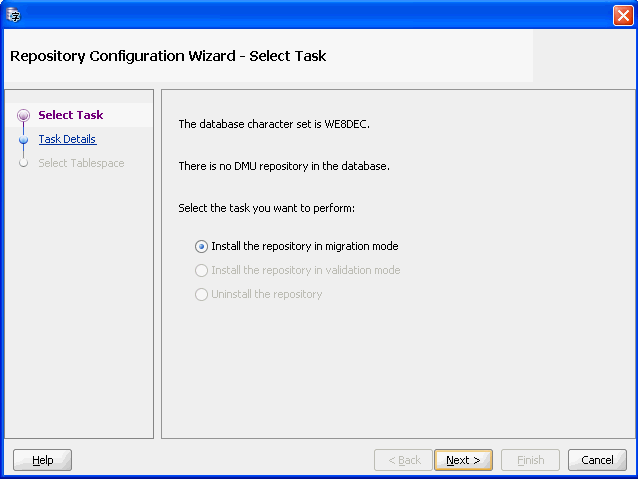
Description of "Figure 2-2 Repository Configuration Wizard - Select Task"
-
On the first page of the wizard, the only choice available is Install the repository in migration mode. After selecting this, click Next.
After you click Next, the second page of the Repository Configuration Wizard is shown. Figure 2-3, "Repository Configuration Wizard - Task Details" is an example of this page.
Figure 2-3 Repository Configuration Wizard - Task Details
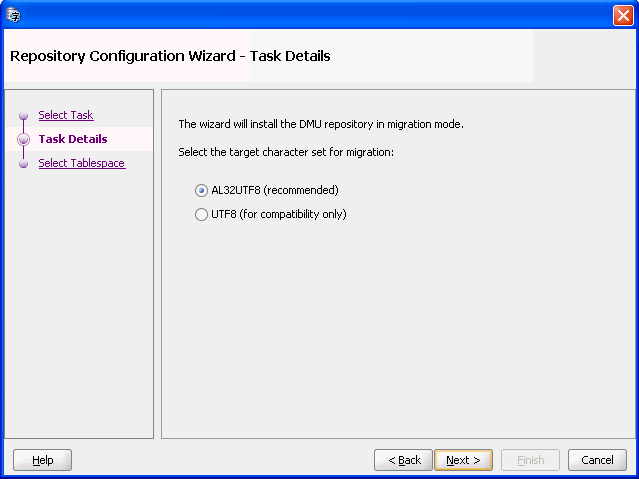
Description of "Figure 2-3 Repository Configuration Wizard - Task Details"
-
Here, you select the target character set for the migration. You can choose between AL32UTF8, the normally recommended character set, and UTF8, which might be required for compatibility with certain applications, such as Oracle Applications 11i. After selecting the character set, click Next. Figure 2-4, "Repository Configuration Wizard - Select Tablespace" appears.
Figure 2-4 Repository Configuration Wizard - Select Tablespace
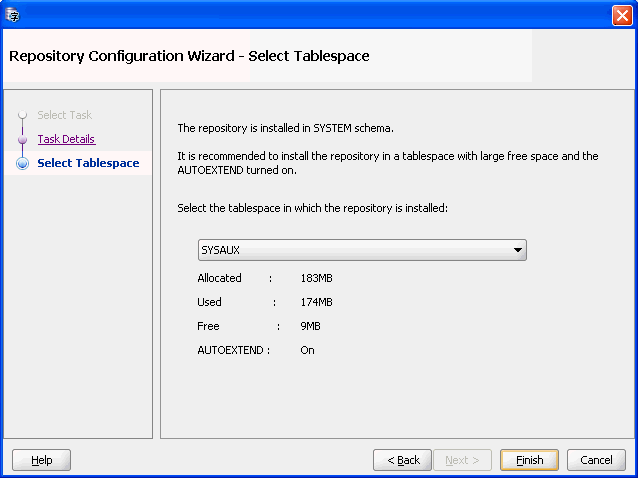
Description of "Figure 2-4 Repository Configuration Wizard - Select Tablespace"
-
On the third page, you can select the tablespace in which you want to install the repository. The default tablespace is
SYSAUX. Oracle recommends that a separate, empty tablespace be used for the migration repository. This helps to avoid fragmentation of the production tablespaces. Ensure that the amount of free space available in the chosen tablespace is sufficient to hold the repository contents. Because the amount of space required by the repository heavily depends on the rowid collection level you choose for scanning and the amount of character data in the database that requires conversion or has convertibility issues, the space required by the repository is difficult to estimate. Therefore, Oracle recommends that you enable the autoextend option on the data files of the repository tablespace to allow the tablespace to grow, if necessary. Define the maximum size constraints for the data files to avoid exhausting the entire disk space.Note that the tablespace for installing the DMU repository must have a block size of 8K or above.
Click Finish to install the repository.
After you have the repository installed, you can begin working on the data.
Following the Status of the Migration
After a database connection has been established, the Migration Status tab is displayed in the Client pane of the DMU main window. You can follow the progress of the migration process by looking at the information on this tab. This tab shows the important milestones in the DMU process: installing the repository, scanning the database for problems, resolving any problems encountered, and then converting the data. The Migration Status tab shows the completion status of each milestone, suggests a next action, and lists issues that prevented a successful conversion. All this information indicates the progress in the workflow. Return to the Migration Status tab periodically to enable the Database Migration Assistant for Unicode to guide you through the migration process.
An example of Migration Status tab content is shown in Figure 2-5. The Migration Status tab describes each of the four main steps of the migration: installation of the migration repository, scanning of the database, resolution of migration issues, and conversion of the database. The tab shows the status of each of the steps and suggests the next action to take. You can click the More links to open help pages that expand the presented information.
The Status area of the section "Step 1: Install Migration Repository" informs you if the connected database contains a migration repository. It can also report that the installed repository is in an incompatible version. Until the repository is installed in the correct version, you cannot proceed to the following steps of the migration process. Follow the advice given in the Next Action area. If the text in this area is a link, click the link to start the recommended action. See "Installing the Migration Repository".
The Status area of the section "Step 2: Scan the Database" reports the scan status of the database. The database might be in any of the following conditions:
-
Not yet scanned – no scan has been executed yet after the migration repository has been created
-
Being scanned – a scan is running in the database just now
-
Partially scanned – only part of the database has been scanned
-
Entirely scanned – all tables in the database have valid scan results
-
Contained invalidated results – scanning results for some tables have been invalidated because the table structure has been modified since the last scan
If the database has not been entirely scanned, see "Scanning the Database" and scan all those tables that have missing or invalid scan results.
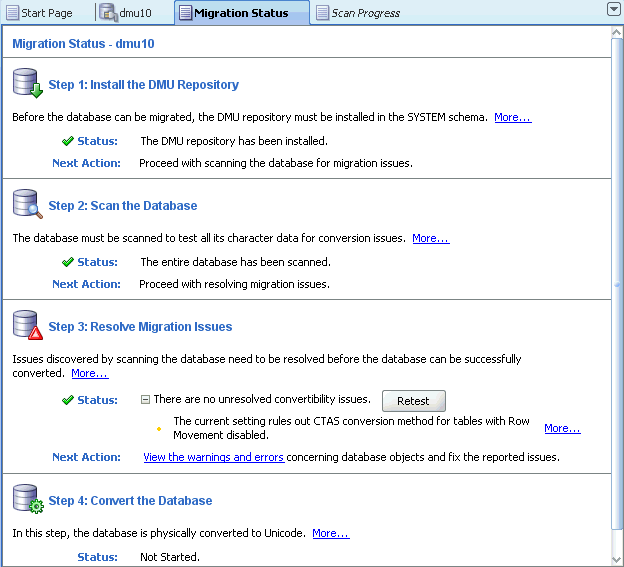
The information presented in the Status area of the "Step 3: Resolve Migration Issues" section might contain a list of issues that must be resolved before you can start the actual conversion of the database content. Click the plus icon to the left of the text "Unresolved convertibility issues found" to see the issues. The issues are classified as warnings and blocking issues.
Warnings, marked with a yellow color, describe features and configuration details of the database that might cause problems during conversion in some situations and not cause any problems in other situations. The DMU is not able to automatically analyze the probability of these problems to arise. Some warnings describe configuration details of the database that might decrease the performance of the database conversion, but which the DMU cannot change itself because of the possible side effects. You might see the following warnings:
-
User-defined OLAP analytical workspaces are present in the database.
-
The database is a standby database.
-
There are external tables with convertible data in the database.
-
There are convertible primary key-based object identifiers (OIDs) in the database.
-
The current setting rules out the CTAS conversion method for tables with row movement disabled.
-
Turning off the
FORCELOGGINGmode of the database or tablespaces might improve conversion performance, though at the expense of the ability to perform media recovery. -
The conversion of some partitioned tables might fail due to error ORA-14402, because the tables do not have the row movement option enabled.
-
Some tables have been excluded from conversion.
-
Convertibility issues in some of the columns will be ignored and the columns will be converted despite the resulting data.
You can choose to ignore some of the warnings and start the conversion, but ensure that you understand all the implications.
Blocking issues, marked with red color, are issues that prevent the DMU to enter the conversion phase. They are known to cause problems in the database, if ignored. You must resolve all blocking issues before you can proceed with converting the database. After all issues are resolved, the Status area for the "Step 3: Resolve Migration Issues" section shows "No unresolved convertibility issue found" and proceeding to the conversion is considered safe.
The Status area of the section "Step 4: Convert Database" informs you if the database conversion has ready been started and, later, if it has already finished successfully.
To view the status of a migration:
-
Click the Migration Status tab in the Client pane.
-
If you have modified the database outside of the DMU to resolve some of the convertibility issues, click Retest to let the DMU recheck the database and update the status information.
-
To reopen the tab at any time, select Migration Status Panel from the Migration menu.
Introduction to the DMU User Interface
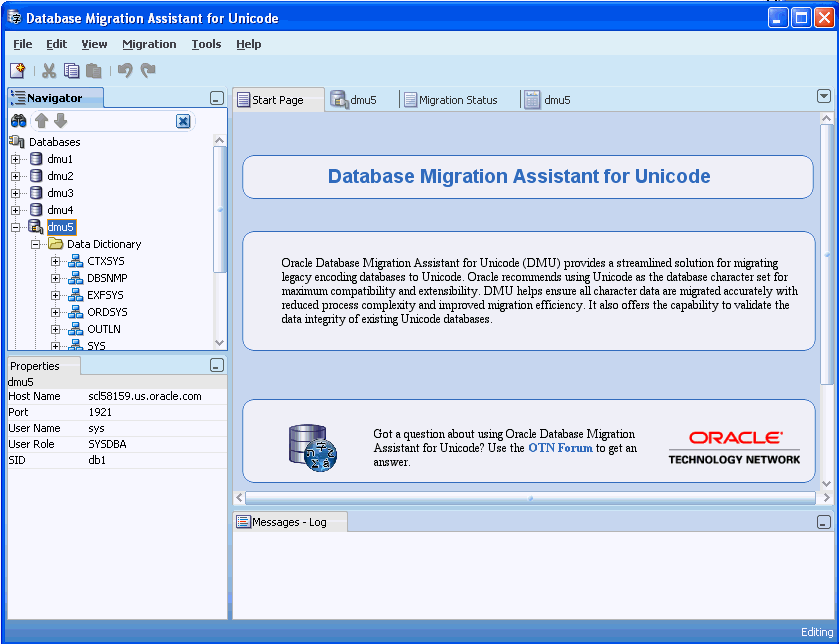
The default layout of the main window of the DMU user interface is shown in Figure 2-6. The window contains a menu bar and a toolbar at the top, and a status bar at the bottom. The remaining area of the window is divided into panes.
The Navigator pane in the top left-hand part of the window shows a tree of database objects on which the DMU operates. The first level of nodes in the tree represents databases to which the DMU can connect. Only one of the database nodes can be associated with an open connection. For further information about connections, see "Creating a Database Connection".
A database node with a currently open connection can be expanded to a subtree of schemas, tables, and columns contained in the database that are relevant to the migration process. Relevant columns are columns that contain character data and might, therefore, require character set conversion when migrated to the Unicode character set. Due to differences in the way the DMU processes them, predefined Oracle schemas comprising the data dictionary are grouped together and displayed separately under the Data Dictionary group node. Remaining schemas are displayed under the Application Schemas group node. Similarly, tables in a schema are grouped into materialized views, under the Materialized Views group node, and other tables, under the Tables group node.
A status icon might be displayed to the left of a node name in the Navigator tree. Table 2-1 shows the possible icons and their meanings for particular node types.
The Client pane in the upper right-hand part of the window is an area in which various tabs are opened in the process of migration. These tabs display object properties, scanning results, cleansing tools, and progress status of tasks. All the tabs are described in the remaining sections of this chapter. When you start the DMU, before a database connection is made, the client pane contains only the Start page, which is a collection of links to various sources of information about the DMU.
The Properties pane in the bottom left-hand part of the window displays selected properties of the most recently clicked node in the Navigator pane or in the Database Scan Report (see "Scanning the Database"). The properties displayed depend on the type of node.
The Log pane in the lower right-hand part of the window displays error and warning messages reported by the DMU during the migration process.
You can customize the layout of the main DMU window by dragging panes and tabs to new positions, but the customized layout is not preserved across program runs.
Table 2-1 Database Migration Assistant for Unicode Icons
| Icon | Column Node | Table, Schema, Database, and Grouping Nodes |
|---|---|---|
|
No icon |
The column has never been scanned. |
No column in the table/schema/database/group has ever been scanned. |
|
Check mark Description of the illustration dumag001f.gif |
The column has been successfully scanned and no issues have been found. |
All columns in the table/schema/database/group have been successfully scanned and no issues have been found. |
|
Red circle with a white X Description of the illustration dumag001d.gif |
The last attempt to scan the column failed. |
A recent attempt to scan one or more columns of the table/schema/database/group failed. |
|
Warning triangle in yellow Description of the illustration dumag001a.gif |
The column has been successfully scanned, but some convertibility issues have been found. |
All columns in the table/schema/database/ group have either been successfully scanned, or they have never been scanned or their scan results have been invalidated; some convertibility issues have been found in the scanned columns. |
|
Round red circle with diagonal line Description of the illustration dumag001e.gif |
The column has been previously scanned, but the scan results have been invalidated due to the containing table being altered or a cleansing action being applied. |
One or more columns in the table/schema/database/group have had their scan results invalidated while all other columns in this table/schema/database/group have never been scanned. |
|
Magnifying glass Description of the illustration dumag001b.gif |
Not applicable. |
Some columns in the table/schema/database/ group have been successfully scanned, and no issues have been found, but other columns have never been scanned or their scan results have been invalidated. |
|
Moving magnifying glass Description of the illustration dumag001c.gif |
The column is being scanned; this status overrides all other statuses. |
One or more columns in the table/schema/ database/group are being scanned; this status overrides all other statuses. |
Overview of Data Preparation
Data preparation ensures that no database data to be migrated will cause problems during or after the actual conversion. The elements of data preparation are scanning and cleansing.
Data Preparation: Scanning
In this step, tables are scanned for problems of various kinds. This scanning assesses the feasibility of migrating the data to Unicode. The most common types of problems are with your data, including issues such as values expanding during conversion beyond column or data type limits, data in a mislabeled character set, or binary data stored in character data types.
During scanning, the DMU reads specified character columns and performs a test conversion of each column value to the target character set, AL32UTF8 or UTF8. Depending on the result of this conversion, the DMU classifies data as follows:
-
Need no conversion
The data is fine, because the binary representation of the data does not change in the conversion.
-
Need conversion
The data must be converted, because the binary representation of the data does change, but no other data issues have been found.
-
Invalid binary representation
The binary representation of the data is invalid under the current database character set. If you do the conversion in this state, the resulting data will usually not make sense to applications and users.
-
Exceed column limit
The data will not fit into a column after migration.
-
Exceed data type limit
The data will exceed a data type limit after migration.
Each column value is assigned to only one of the above categories. Values that have invalid binary representation are classified only as such even if their lengths exceed column or data type limit after conversion. As conversion of invalid character codes usually yields the default replacement character, which has a three-byte representation in AL32UTF8 and UTF8, the length expansion issues are not rare among values with invalid representation. Because the DMU let you ignore invalid representation issues and force conversion of a column (see "Ignoring Convertibility Issues"), you should be aware that forcefully converted values with invalid binary representation may be additionally truncated. You can compare the value of the Maximum Post-Conversion Length property of the column with the column and data type length limits to see if the truncation will take place. See "Column Properties: Scanning" for more information about the property.
This release of the DMU supports Oracle Database 12c extended data type limit where the maximum size limit for VARCHAR2 has been increased to 32767 bytes. The extended type limit guarantees that VARCHAR2 data created in earlier releases up to the original type limit of 4000 bytes can be migrated to Unicode on Database 12.1 with no over data type limit expansion exceptions.
After you have run a scan, the DMU creates a Database Scan Report, which can be found under the Migration drop-down menu. This scan report shows the statistics for the current data under each of the preceding categories. The counts of values are presented for each character data type column, and also summed up at the table, schema, and database levels. The scan report enables you to filter and customize the output, for example, so that only columns with selected potential problems such as exceeding the column limit are displayed.
In addition, you can use the report to iteratively go through the steps of taking the data that is not clean, reviewing this data in the Cleansing Editor, fixing the data, either immediately or at your convenience later, and rescanning to verify that the data is now clean.
You can perform scans on the following objects:
-
All tables in the database
-
All tables in the data dictionary of a database
-
All application schema tables in a database
-
All tables in an application schema
-
A table column in an application schema
-
An arbitrary set of application schema tables and columns in a database
See Also:
"Scanning the Database" for detailsIt is important to remember that, as mentioned in "Overview of Character Set Migration Considerations", there are certain data issues that cannot be discovered automatically. For example, the DMU does not analyze character data in binary data types. Also, some single-byte character sets define almost all byte values as valid codes. For example, the only byte value that is not a valid CL8MSWIN1251 character code is 0x98. Therefore, the test conversion during a scan might not show invalid binary representation problems, if the incorrectly stored data happens not to contain any of the undefined byte values. Even if the database scan reports no issues, collect and analyze information about use of the database by applications and try to identify these types of hidden problems before attempting the database conversion. Creating a test copy of the database, migrating it to Unicode, and thoroughly testing it with your applications is also a way to discover many problems.
Data Preparation: Cleansing
In this step, the data in tables is cleaned based on identified issues. You can define cleansing actions for immediate or for delayed execution (immediate versus scheduled cleansing mode). Certain types of cleansing can be done in a production environment with no side effects to applications, but there are other cleansing operations that involve metadata changes and require applications to be adapted to these changes. The scheduled mode enables you to define a cleansing action at any time but delay its execution to the conversion phase of the migration process. This is usually the most convenient moment to introduce metadata changes because the database is not used in production and new application versions can be easily deployed at the same time.
Immediate changes to metadata are defined in the Modify Column and Modify Attribute dialog boxes. Scheduled changes are defined in the Schedule Column Modification and Schedule Attribute Modification dialog boxes. All these dialog boxes can be invoked from the context menu of a column or attribute in the Cleansing Editor. Immediate editing changes of user data are performed directly in the Cleansing Editor.
In the immediate mode, any change entered is performed immediately after an appropriate Save button is selected. In this case, all SQL statements are issued to the database and the transaction is committed.
In the scheduled mode, clicking Save puts the cleansing action into the DMU repository. The corresponding statements are executed during the conversion step. You can change the scheduled action or remove it, provided the conversion step has not yet been started, by reopening the Schedule Column Modification or Schedule Attribute Modification dialog box and selecting No Modification.
You apply the editing changes performed in the Cleansing Editor on table data to the database by clicking Save on the Cleansing Editor tab. You can revert the changes that have not yet been saved by clicking the Revert button.
The Cleansing Editor can also be used to set the assumed character set of a column. This property tells the DMU to interpret the contents of the column in a character set different from the database character set. The selected character set is applied to the test conversion during scanning, actual conversion occurs in the conversion step, and the set is used to interpret data for display in the Cleansing Editor. If column data in the Cleansing Editor is not legible, the character set of the column might be selected incorrectly.
After cleansing, rescan the database to verify that your changes have successfully handled the potential problems. This is an iterative process where you scan and cleanse until there are no more conversion issues before you proceed to the conversion phase.
See Also:
Chapter 6, "Using the DMU to Cleanse Data" for detailsOverview of Data Conversion
The data conversion phase is where the actual modification of the database contents occurs. After the conversion is complete, the database character set will be Unicode. The conversion consists of the following steps:
Preparing the Conversion
When you tell the DMU to start the conversion phase by selecting Convert Database in the Migration menu, the DMU first executes a conversion feasibility test. This test checks that:
-
All database convertibility requirements listed in "Overview of Database Requirements" are met
-
All data in the database has been scanned and has valid scan results
Cleansing actions might invalidate scan results, so cleansed tables might need to be rescanned.
-
No data in the database has binary representation or length issues
If the test succeeds, the DMU presents a plan for conversion. This plan shows all SQL statements that will be executed to convert the database, including statements to handle auxiliary objects, such as indexes, constraints, and triggers. You can customize the plan as desired. There are various database-level and table-level options that can be used to influence the way DMU converts the database. For example, you can set the conversion method for a given table or the number of processes participating in the conversion step. The conversion plan is generated and displayed in the Conversion Progress tab. You can then modify the available options by clicking Edit Table Conversion Plan or Edit Database Conversion Parameters.
Converting Data
The next step is to actually convert the data into Unicode. You accept the conversion plan and initiate the conversion by clicking the Convert button on the Conversion Progress tab. The DMU repeats the conversion feasibility test to ensure that no issues have been introduced while you worked on the conversion plan. It verifies also that no other sessions are connected to the database and that the database is mounted in exclusive mode. Then, the DMU begins to migrate the data, executing the statements from the conversion plan.
You can monitor the conversion progress on the Conversion Progress tab.
As an overview, the process the DMU uses to convert data is:
-
Put the database into restricted mode.
-
Disable various job queue processes.
-
Drop or disable selected indexes.
-
Disable selected triggers and constraints.
-
Convert the data in user tables and in selected data dictionary tables to Unicode.
-
Convert
CLOBcolumns in the data dictionary. -
Issue the
ALTERDATABASECHARACTERSETstatement. -
Enable triggers and constraints; and re-create indexes and constraints.
-
Restore the database instance parameters.
The conversion of a table is performed either by updating its columns with an UPDATE statement or by converting the columns while re-creating the table using the CREATE TABLE AS SELECT statement. The re-creation of a table is faster that an update if most of the table rows must be converted.
After the conversion has finished, the DMU will re-create or reenable any objects that were dropped or disabled earlier. You can check that no errors have been generated by looking at the Log pane.
See Also:
"Converting the Database" for more information about the conversion GUI