5 Advanced Topics in the DMU
This chapter illustrates various advanced topics that you should consider when working with the Database Migration Assistant for Unicode. It includes:
Excluding Columns and Tables From Migration
In certain situations, you may want to exclude selected columns or tables from scanning or conversion steps of the migration process. Situations in which this may be justified are the following:
-
You need to solve a problem of multiple character sets in a single column (see "Working with Multilingual Columns").
-
There is a character column in the database that contains binary data. You cannot migrate the column to a binary data type (
RAW,LONGRAW, orBLOB), because you are unable to modify applications accessing the database, for example, because they are not developed in-house. You want to avoid converting the column so that the applications may continue to access the data in a pass-through configuration. -
There is a very large table in the database, with terabytes of data, which – you are absolutely sure – contains no convertible data. Such tables:
-
Cannot contain
CLOBcolumns, unless the current database character set is multibyte. -
Can contain only character columns with internal application codes, yes/no flags, credit card numbers or other data known to contain only basic ASCII characters.
-
Must not contain data entered by end users from keyboards that support non-ASCII characters even if the users are supposed to enter English text only. Standard keyboards of computers running Microsoft Windows always allow such characters to be entered.
You may want to avoid scanning such a large table to reduce the scanning time of the whole database. Oracle strongly recommends that you scan even very large tables at least once.
-
-
As with the case of very large tables, you may want to avoid scanning archival data stored in read-only tablespaces on slow storage devices, such as DVD-ROM jukeboxes. Again, you should be absolutely sure that the tables contain no data requiring conversion.
-
There are read-only tablespaces or a read-only table that you cannot change to read/write for some important reason. You want to be able to convert the rest of the database to Unicode, even though the tablespace or the table contains convertible data that the DMU will not be able to convert. You accept that data in the tablespace or the table will be unreadable after the conversion unless appropriate workarounds are implemented or the DMU converts the data later in validation mode.
-
As with read-only tablespaces, if you have an offline tablespace or offline data file that you cannot switch back online, the DMU will not be able to scan or convert data in this tablespace or data file. You still want to convert the rest of the database and you accept that the contents of the tablespace or the data file may be unreadable if you later switch the tablespace or the data file back online. You can use the DMU in validation mode to later convert this data.
See "Handling Non-Accessible Data" for further discussion about database objects in read-only and offline mode.
To exclude a table from scanning, simply deselect it on the object selection page of the Scan Wizard.
To exclude a column from conversion, open its Column Properties tab (see "Viewing and Setting Column Properties") and set the Exclude from Conversion property on the Converting subtab to Yes. The DMU does not consider columns excluded from conversion when checking for convertibility issues that prevent you from starting the conversion step. To exclude a table from conversion, exclude all its convertible columns.
Handling Non-Accessible Data
Certain types of data in a database might be inaccessible to applications. The data may be non-updatable or it may be even unreadable. The DMU cannot convert non-updatable data and it can neither convert nor scan unreadable data. Data with access restrictions is data contained in any of the following database objects:
Read-Only Tables Considerations
All Oracle Databases since release 11.1 support the read-only mode for database tables. Thus, users who want table contents to be protected against updates can alter a table to read-only mode. A read-only table can be queried, its constraints modified, its segment moved, shrunk, or expanded, but none of its column values can be modified in any way and no new rows can be added. Users can alter the table back to read/write mode and again to read-only, as many times as required.
Read-only tables cannot be updated and, thus, their contents could not be converted if required by the DMU. Therefore, the DMU automatically alters read-only tables to read/write mode before attempting conversion. After the conversion, the mode is changed back to read-only.
A read-only table may also be re-created, if it is converted using the "Copy data using CREATE TABLE AS SELECT" conversion method.
Read-Only Tablespaces Considerations
A tablespace can be put into read-only mode. This prevents any data stored in it from being updated. Data files of read-only tablespaces could be put on read-only media, such as DVD-ROM, and moved to jukeboxes, which are used as cheaper storage for seldom accessed archived data. The data files might also remain on standard read/write disk storage devices. For example, historical data in very large databases is frequently moved to read-only tablespaces. The tablespaces are backed up only once, just after putting them into read-only mode. As read-only tablespaces cannot change, no further backups are required. This significantly reduces backup time of the very large databases.
If any segment of a table, including partition, CLOB, VARRAY, and IOT overflow segments, contains data that requires conversion, and the segment belongs to a read-only tablespace, the DMU cannot successfully convert the table. The DMU reports this as a convertibility issue on the Migration Status tab and does not allow you to start the conversion step until the problem is resolved.
The approach to resolve this convertibility issue depends on the reason for which the problematic tablespaces have been put into read-only mode. If the reason was to reduce backup time, and the data is still on standard disk devices, put the tablespaces back into read/write mode, convert them with the rest of the database, put into read-only mode again and refresh the backup.
If the tablespaces have been put into read-only mode and moved to read-only media, the possible solutions are:
-
If enough disk storage can be arranged for, permanently or temporarily, to accommodate all read-only tablespaces with convertible data, copy the tablespaces to this storage, make them read/write, convert together with the rest of the database, make read-only again, and either leave on the disk storage, or put back on read-only media. With large number of read-only tablespaces containing convertible data, this may not be a viable solution.
-
Create an auxiliary database in the same character set as the main database, that is, the database to be migrated. Move the read-only tablespaces logically to the new database using the transportable tablespace feature, leaving the data files physically in their current location. Create a database link in the main database pointing to the new database. By creating auxiliary views or through application changes, make the read-only data in the auxiliary database visible to applications connecting to the main database. The data will be converted while being transported over the database link.
Offline Tablespaces and Data Files Considerations
A tablespace or selected data files in a tablespace may be put into offline mode. Any data contained in an offline tablespace or data file is inaccessible for both reading and writing. Offline mode is required by various administrative operations on data files, such as renaming or moving from one storage device to another.
If any segment of a table, including partition, LOB, VARRAY, and IOT overflow segments, contains character data that may require conversion, and the segment belongs to an offline tablespace or data file, the DMU can neither scan nor convert the table. You must put such a tablespace or data file back to online mode before scanning or converting the affected tables. Otherwise, errors, such as ORA-00376, will be reported in the scan and conversion steps.
The DMU will report an error on the Migration Status tab and prevent you from starting the conversion step if convertible data is found in an offline data file.
Working With External Tables
An external table is a table whose data resides in files outside of the database. The database contains definitions of table columns (metadata) but table rows are fetched from external files when a query referencing the table is issued. Oracle Database supports two access drivers that read the external files: ORACLE_LOADER and ORACLE_DATAPUMP. ORACLE_LOADER reads text files that are in the format supported by the SQL*Loader. ORACLE_DATAPUMP supports binary files that are compatible with the Data Pump Export and Import utilities (expdp and impdp).
DML statements modifying external tables are not supported. An ORACLE_DATAPUMP external file may be created and filled with data when an external table is created with the statement CREATE TABLE … ORGANIZATION EXTERNAL … AS SELECT but it cannot be later modified from inside the database. ORACLE_LOADER files must be created and modified outside of the database. The DMU does not convert external files along with the database contents.
When an external table is created, the character set of its data files is established as follows:
-
The character set of an
ORACLE_DATAPUMPfile is stored in the data file itself when the file is created by theORACLE_DATAPUMPdriver or the Data Pump Export utility. -
The character set of an
ORACLE_LOADERfile may be specified in theCHARACTERSETparameter in the access parameters clause of the external table definition. If the parameter is not specified, the database character set is used to interpret the contents of the file.
If the declared character set of an external file differs from the database character set, the database converts the data automatically while reading it. If the database character set changes but the character set of the external file does not change, the database adapts itself to the new configuration and converts external files to the new database character set.
Caution:
If the character set of anORACLE_LOADER file is not declared explicitly in the access parameters clause of an external table definition, a change to the database character set also changes the implicit declaration of the character set of the external file. If the file itself is not converted to the new database character set, the external file declaration no longer corresponds to the real character set of the file and the external table is no longer correctly readable.
Before migrating a database to Unicode, you must either add missing explicit character set declarations to all external table definitions or convert the file contents to the new database character set.
Cleansing External Tables
Even though the DMU does not convert external tables, it does include them in the scanning step of the migration process. The scan results show you, if the file contents will still fit into the declared column lengths after migration, even if data expands in conversion to the new Unicode database character set. The results also warn you if any illegal character codes are present in the external files. These codes will no longer be readable if the file contents must be converted on the fly.
If the scan report shows invalid binary representation issues, you must identify the source of the invalid codes, as discussed in "Invalid Binary Storage Representation of Data" and "Cleansing Scenario 3: Cleansing Invalid Representation Issues".
The following sections describe actions that you can perform to cleanse the external tables from various reported issues.
Cleansing Length Issues
If the scan report shows length issues in external table contents, you can alter the table to lengthen the affected columns or migrate them to character semantics. The DMU does not support cleansing actions on external tables so you must do this in another tool, such as SQL*Plus or SQL Developer. Changing a VARCHAR2 column to CLOB may be necessary, if the data expands above 4000 bytes. To change the column data type to CLOB, you must re-create the external table. This is a fast operation, as only metadata changes are involved, but you must remember to re-create any dependent objects, such as grants.
Correcting Character Set Declaration of ORACLE_LOADER Files
If character values of an external table are read by the ORACLE_LOADER driver in a pass-through configuration, that is, the declared character set of data files and the database character set are the same, but the real character set of data contents is different, you can repair the configuration by declaring the real character set in the access parameters clause of the external table definition. You must not change the declaration in a production database before the database is converted, because this would break the pass-through configuration and make the table unreadable.
Before the database is converted, you should change the Assumed Column Character Set property of the affected external table columns – as described in "Setting the Assumed Character Set" – to the identified real character set of the data files and rescan the table to identify any additional length and invalid binary representation issues that might come up after the data file character set declaration is corrected.
Oracle recommends that you create a script to modify all affected access parameter clauses in the database and run it directly after the conversion phase of the DMU finishes successfully.
Correcting Character Set Declaration of ORACLE_DATAPUMP Files
If character values of an external table are read by the ORACLE_DATAPUMP driver in a pass-through configuration, that is, in the character set configuration described in the previous section, you should ensure that the Data Pump input files are correctly re-tagged with their real character set directly after the database is converted to Unicode.
Unfortunately, the character set declaration is stored internally in Data Pump files and cannot be easily modified. A more complex procedure is needed to fix the declaration. Alternatively, you can arrange for the external table files to be provided in ORACLE_LOADER format, so that you have full control over their character set declaration in the external table's access parameters clause.
If a Data Pump file is used in a pass-through configuration, it means that its source (exported) database also works in this configuration, as otherwise it could not produce an incorrectly tagged file. The recommended approach to fix the character set declaration of a Data Pump file is, therefore, to fix the database character set of its source database.
If you have no control over the character set of the source database, you must:
-
Create an auxiliary, empty database in the character set of the Data Pump files
-
Import the files – this will happen in the pass-through configuration
-
Change the database character set to the real character set of the files
-
Export the files and use them for the external table in the main database (after it is migrated to Unicode)
Contact Oracle Support for information about fixing a pass-through configuration by changing the database character set with the Character Set Scanner utility (csscan) and the csalter.plb script.
The following PL/SQL code enables you to identify the character set of a Data Pump file:
DECLARE
et_directory_name VARCHAR2(30) := '<directory object name>';
-- for example, 'DATA_PUMP_DIR'
et_file_name VARCHAR2(4000) := '<file name>';
-- for example, 'EXPDAT.DMP'
et_file_info ku$_dumpfile_info;
et_file_type NUMBER;
BEGIN
dbms_datapump.get_dumpfile_info
( filename => et_file_name
, directory => et_directory_name
, info_table => et_file_info
, filetype => et_file_type );
FOR i IN et_file_info.FIRST..et_file_info.LAST LOOP
IF et_file_info.EXISTS(i) THEN
IF et_file_info(i).item_code = 11 THEN
dbms_output.put_line( 'Character set of the file is ' ||
et_file_info(i).value );
END IF;
END IF;
END LOOP;
END;
Fixing Corrupted Character Codes
If analysis of invalid binary representation issues in an external table shows that there are only some corrupted character codes in some character values – usually due to a user error, an application defect, or a temporary configuration problem – the values should be corrected in the source database and the affected files re-exported or unloaded again.
With ORACLE_LOADER files, you can fix the invalid codes directly in the files with a text editor. However, the solution is effective only if the files are not regularly replaced with a new version produced from the same source database contents.
Handling Binary Data
Invalid binary representation issues in an external table may also be caused by binary data being declared and fetched as character data by the external table driver. To cleanse this type of issues, you must redefine the external table to use binary data types, such as RAW and BLOB, for the affected columns.
Oracle strongly discourages attempts to continue using the pass-through configuration to fetch the binary data into a database with a multibyte character set, such as UTF8 or AL32UTF8. Such configuration may cause unexpected issues now or in the future.
Performance Considerations for ORACLE_LOADER Files
The Oracle Database Utilities Guide lists several performance hints for the ORACLE_LOADER driver. The following hints are especially relevant in the context of character set migration to Unicode:
-
Single-byte character sets are the fastest to process.
-
Fixed-width character sets are faster to process than varying-width character sets.
-
Byte-length semantics for varying-width character sets are faster to process than character-length semantics.
-
Having the character set in the data file match the character set of the database is faster than a character set conversion.
If you can choose between leaving an ORACLE_LOADER file in its current character set and arranging for the file to be provided in the new Unicode database character set, you should consider the following conclusions drawn from the above hints:
-
If the current character set of the file is multibyte, using UTF8 or AL32UTF8 database character set for the file will not significantly influence the parsing time, that is, time needed to divide the file into records and fields, but it will save on conversion time. Performance of the queries referencing the external table will be better.
-
If the current character set of the file is single-byte, using UTF8 or AL32UTF8 database character set for the file will slow down parsing but it will save on conversion time. You should benchmark both configurations to find out which one is more efficient.
-
If you decide to convert the file from a single-byte character set to UTF8 or AL32UTF8, try to express field lengths and positions in bytes versus characters, if maximizing query performance is important.
Migrating Data Dictionary Contents
The DMU classifies tables as belonging to the data dictionary based on the schema that owns them. Schemas that the DMU considers to be in the data dictionary are those displayed under the Data Dictionary node in the Navigator panel – see "Introduction to the DMU Interface and Navigation". If you create your own table in a data dictionary schema, such as SYS or SYSTEM, the DMU will treat it as other data dictionary tables. Oracle discourages creating user tables in data dictionary schemas.In this release, the DMU supports character set conversion of only a subset of metadata kept in the data dictionary tables. Therefore, the DMU handles data dictionary tables differently from other tables in the database, as described in the following sections.
Scanning Data Dictionary Tables
Most data dictionary tables are scanned in the same way as user-defined tables. The usual convertibility issues – data exceeding column limit, data exceeding data type limit, and data having invalid binary representation – are reported in the same way as well. The difference lies in reporting of data that needs conversion to the target Unicode character set. Because the DMU does not support converting of data dictionary contents in this release, except for a few exceptions, non-convertible columns containing data requiring conversion are marked with the yellow triangle warning icon and are considered a convertibility issue that prevents starting the database conversion step. The Database Scan Report filtering condition "With Some Issues" includes these columns as well – see "Database Scan Report: Filtering".
The View Data tab, described in "Viewing Data", which is a read-only version of the Cleansing Editor for data dictionary and other non-modifiable tables, shows convertible values in non-convertible data dictionary columns in dedicated colors configured on the Cleansing Editor tab in the Preferences dialog box, by default black on orange background.
Convertible data in the few columns that the DMU does convert, which are listed in "Converting Data Dictionary Tables", is not reported as an issue.
For implementation reasons, the tables SYS.SOURCE$, SYS.ARGUMENT$, SYS.IDL_CHAR$, SYS.VIEW$, SYS.PROCEDUREINFO$, and SYS.PLSCOPE_IDENTIFIER$ are always scanned with "Rowids to Collect" parameter set to "All to Convert". See "Converting Data Dictionary Tables" for more details.
Cleansing Data Dictionary Tables
As Oracle neither supports altering structure of data dictionary tables nor updating their contents, the DMU does not allow cleansing actions on such tables. You can set the assumed character set of columns of the data dictionary tables but the selected character set is considered only when displaying the columns on the View Data tab. The source character set used for conversion is always the assumed database character set.
Cleansing Data Length Issues
If data length issues are reported for data dictionary contents, that is, the metadata, the only way to cleanse the issues is to replace the metadata with its shorter version. The same length issues affect all character set migration methods, not only migration with the DMU, so you must cleanse the issues even if you plan to use alternative conversion methods, such as moving data with the Data Pump utilities.
The most common length issues are object names becoming longer than allowed after conversion. As the usual length limit for an identifier is only 30 bytes, longer identifiers containing non-ASCII letters, especially those written in non-Latin scripts, may easily exceed the limit. For example, a Greek or Russian identifier longer than 15 characters will not fit into the 30 bytes limit after conversion from EL8MSWIN1253 or CL8MSWIN1251 to UTF8 or AL32UTF8. Chinese, Japanese, and Korean characters usually expand from 2 to 3 bytes, so identifiers longer than 10 characters become an issue.
To shorten an identifier, you must rename the corresponding database object with an appropriate SQL statement or a PL/SQL package call. Some objects can be just renamed but most have to be dropped and re-created under the new name. When you drop an object, some dependent objects may be dropped along. You must re-create them as well.
For example, you can rename a table, a view, a sequence, or a private synonym using the SQL statement RENAME. You can rename a table column using the SQL statement ALTER TABLE RENAME COLUMN. But you cannot simply rename a cluster. You must drop it and re-create under another name. But before you drop a cluster, you must drop all tables stored in the cluster. As there are many possible auxiliary objects created for tables, such as privileges, indexes, triggers, row-level security policies, outlines, and so on, you may end up re-creating a lot of objects. The Data Pump utilities and the Metadata API may be helpful in such case.
See Also:
Oracle Database Utilities for more information about the Data Pump utilities and the Metadata APIAfter renaming a database object, you must change all application code that references this object to use the new name. This includes PL/SQL and Java code in the database, but also all affected client applications.
Another type of metadata that often expands beyond maximum allowed length is free text comments for various database objects. Similarly, you must update the comments with a shorter version to cleanse any reported length issues. Most comments can be updated with an appropriate SQL statement or PL/SQL package call.
See "Identifying Metadata" for suggestions about identifying right statements to cleanse data dictionary issues.
Cleansing Invalid Binary Representation Issues
A common reason for invalid binary representation of data is the pass-through scenario, described in "Invalid Binary Storage Representation of Data". If SQL statements or PL/SQL calls are issued in such a configuration, it is possible to create and use a database object that is named using or contains characters not valid or not having the expected meaning in the database character set. For example, a seemingly senseless table name in a WE8MSWIN1252 database might be interpreted as appearing correct on a Japanese JA16SJIS client, or, a PL/SQL module might contain comments that are not legible in the database character set but that make sense when viewed in another character set.
Invalid binary representation of database object names is a seldom encountered issue as restrictions on characters allowed in non-quoted identifiers make it visible from the very beginning. Invalid binary representation of object comments is more probable but also easier to fix.
To cleanse the invalid binary representation issues caused by the pass-through configuration, if they are common to the application data as well, set the assumed database character set property of the database to the real character set of the database contents – see "Database Properties: General". Otherwise, use the same approach that is described in "Cleansing Data Dictionary Tables" to update the affected metadata with a version that does not have convertibility issues.
To fix invalid representation issues in PL/SQL and Java source code or in view definitions, use Metadata API to retrieve the DDL statements creating the objects, correct the problematic characters in the statement text and execute the statements to re-create the objects. If object names are not affected, use the CREATE OR REPLACE syntax to change the code without having to re-create related objects, such as privileges.
Identifying Metadata
A difficult step in the process of resolving data dictionary convertibility issues is to map the issues shown in a database scan report to the type of metadata that is stored in the affected tables and columns. The data dictionary tables, presented in the DMU interface, are generally not documented. The documented way to view their contents is through data dictionary views such as DBA_TABLES, DBA_TAB_COLUMNS, DBA_RULES, DBA_SCHEDULER_JOBS, and many others.
To identify the type of metadata that has convertibility issues, try one of the methods below, in the presented order:
-
Look at the problematic character value on the View Data tab – see "Viewing Data". The value itself may already tell you the metadata that it belongs to. For example, the value may be "This column keeps customer e-mail", which suggests that it is a column comment, or it may be "HR_EMPLOYEE_V", which may correspond to a common convention to name views, thus showing the value is a view name.
-
Search for the name of the table in which the issues are reported in SQL script files named
cat*.sqlandcd*.sqland located in therdbms/admin/subdirectory of your database Oracle home directory. These scripts define data dictionary views that are documented in Oracle Database Reference. By mapping the table and its columns to the right documented view, you can find out which metadata has the reported issues. -
Contact Oracle Support or post a question on the globalization forum on the Oracle Technology Network Web site.
Once you identified the metadata that has the reported convertibility issues, refer to Oracle documentation to identify the right procedure to change this metadata.
Converting Data Dictionary Tables
The DMU converts only the following data in the data dictionary:
-
CLOBcolumns – this is necessary only in a single-byte database -
Binary XML token manager tables, with names like
XDB.X$QN%andXDB.X$NM% -
PL/SQL source code (text of
CREATEPROCEDURE,CREATEFUNCTION,CREATEPACKAGE,CREATEPACKAGEBODY,CREATETYPEBODY,CREATETRIGGER, andCREATELIBRARY); type specifications (CREATETYPE) are not converted -
View definitions (text of
CREATEVIEW) -
The columns:
-
SYS.SCHEDULER$_JOB.NLS_ENV– NLS environment for Database Scheduler jobs (DBMS_SCHEDULER) -
SYS.SCHEDULER$_PROGRAM.NLS_ENV- NLS environment for Database Scheduler job programs (DBMS_SCHEDULER) -
SYS.JOB$.NLS_ENV– NLS environment for legacy jobs (DBMS_JOB) -
CTXSYS.DR$INDEX_VALUE.IXV_VALUE- attribute values of Oracle Text policies -
CTXSYS.DR$STOPWORD.SPW_WORD- all stopwords in all stoplists of Oracle -
over 50 different columns in
SYS,SYSTEM, andCTXSYSschemas that contain user comments for various database objects
The PL/SQL source code and the view source text are kept in multiple tables. The DMU checks the following columns when processing the source code and view definitions:
-
SYS.VIEW$.TEXT– view definition text -
SYS.SOURCE$.SOURCE– PL/SQL and Java source code -
SYS.ARGUMENT$.PROCEDURE$– PL/SQL argument definitions: procedure name -
SYS.ARGUMENT$.ARGUMENT– PL/SQL argument definitions: argument name -
SYS.ARGUMENT.DEFAULT$– PL/SQL argument definitions: default value -
SYS.PROCEDUREINFO$.PROCEDURENAME- names of procedures and functions declared in packages -
SYS.IDL_CHAR$.PIECE- internal representation of PL/SQL -
SYS.PLSCOPE_IDENTIFIER$.SYMREP- internal representation of PL/SQL; this table did not exist before version 11.1 of Oracle Database
The DMU does not report convertible character data in the tables and columns listed above as a convertibility issue. Any convertible data in the remaining tables and columns of the data dictionary is flagged as a convertibility issue in scan reports and on the Migration Status tab. The database conversion step cannot be started before the flagged data is removed.
-
Data Dictionary Tables That Are Ignored
The DMU does not scan the following tables:
-
SYS.HISTGRM$, which contains column histogram statistics -
Automatic Workload Repository object statistics history kept in tables with names such as
SYS.WRI$_OPTSTAT_OPRandSYS.WRI$_OPTSTAT_%_HISTORY -
DMU repository tables in the
SYSTEMschema -
CSSCANrepository tables in theCSMIGschema
The contents of these tables are also not considered when the DMU decides if the database conversion is allowed to start.
The SYS.HISTGRM$ table is not scanned because its EPVALUE column (storing end-point values) may contain binary data. As histograms and other table statistics depend on binary representation of data in character columns, you should anyway re-gather statistics for all converted tables in the database after migration. Collection of statistics refreshes the contents of the SYS.HISTGRM$ table and revalidates it in the new database character set. If you do not refresh the statistics, the optimizer may exhibit incorrect behavior.
Similarly, the historical object statistics kept in Automatic Workload Repository become stale after the migration because they also depend on binary representation of character data. The DMU does not migrate those statistics. You should purge them manually after migration by calling DBMS_STATS.PURGE_STATS(SYSTIMESTAMP).
See Also:
-
Oracle Database PL/SQL Packages and Types Reference for more information about the package
DBMS_STATSand the procedurePURGE_STATS -
Oracle Database Concepts for more information about optimizer statistics
The DMU and CSSCAN repository data becomes invalid after the database is migrated to a new database character set. Therefore, there is no point in migrating it along with the database. After the migration, you should drop the repositories and re-create them, if you still need them. If you re-create the DMU repository after migration, choose the validation mode – see "Validating Data as Unicode".
Handling Automatic Workload Repository Tables
The SYS schema contains a number of tables with names beginning with WRI$, WRH$%, and WRR$_, which comprise the Automatic Workload Repository (AWR). In addition to historical object statistics, mentioned in "Data Dictionary Tables That Are Ignored", this repository stores snapshots of vital system statistics, such as those visible in various fixed views, for example, V$SYSSTAT and V$SQLAREA.
If non-ASCII characters are used in object names or in SQL statements, such as character literals or comments, they may get captured into the AWR tables. The DMU scan will report such characters as convertible data dictionary content, which prevents conversion of the database. To remove this data completely, re-create the Automatic Workload Repository by logging into SQL*Plus with SYSDBA privileges and running:
SQL> @?/rdbms/admin/catnoawr.sql SQL> @?/rdbms/admin/catawr.sql
As the catawr.sql script is not present in Oracle Database versions 10.2.0.4 and earlier, Oracle recommends that you install the Oracle Database patch set 10.2.0.5 before purging AWR contents.
Working with Multilingual Columns
As mentioned in "Cleansing Incorrect Character Set Declaration", you may find out while analyzing contents of a column in the Cleansing Editor that none of the assumed character sets set for the column makes all values in the column appear correctly at the same time, but each of the values does seem to be correct in one of the selected character sets. This indicates that the column contains a mixture of data in different character sets. You might also gather this information from analysis of data sources for your database.
Multiple character sets in a single column are possible in the pass-through scenario, if clients working in various character sets all store data in this column.
This release of the DMU does not contain any feature dedicated to cleansing this type of convertibility issue. The following procedure is recommended when you must deal with multiple character sets in a single CHAR or VARCHAR2 column:
To work with multiple character sets in a single CHAR or VARCHAR2 column:
-
Find any auxiliary data that can help you identify the real character set of a single value in an affected column. Examples of such data are:
-
a country code associated with the value
-
an identifier of the operator who entered the value
-
an identifier of a subsidiary responsible for entering the value
-
-
Create a mapping table that maps auxiliary data to possible character sets of the values. If your company standardizes on a certain type of workstations, the source country of the analyzed value usually defines the client character set used to enter the value.
-
Mark columns that contain data in multiple character sets for exclusion from conversion – see "Column Properties: Converting".
-
Verify that there are no length issues with the columns. If required, cleanse them by making longer or by shortening problematic values. Do not migrate to
CLOB. See Example 5-1 below for information about how to check for length issues. -
Convert the database.
-
Using the mapping table, convert the affected columns with the SQL function
CONVERTspecifying the target Unicode character set in its second argument and the identified value character set in its third argument.
Example 5-1 Multilingual Column Considerations
Assume your database contains the table CUSTOMERS, with columns CUSTOMER_NAME_ORIGINAL and CREATED_BY. The column CUSTOMER_NAME_ORIGINAL, defined as VARCHAR2(80 BYTE), contains the names of customers in their mother tongue in multiple character sets. The column CREATED_BY contains system IDs of employees who entered the customer data. You want to migrate the database to the character set AL32UTF8.
To solve the issue of multiple character sets in the CUSTOMER_NAME_ORIGINAL column start with creating a mapping table that maps employees' system IDs to client character sets of the employees' workstations. A table in your application that defines the system IDs may be helpful in locating the country in which the employee works and thus determining the character set of the client workstation that the employee uses. Further assume the created mapping table is named CREATED_BY_TO_CHARSET_MAPPING and has the columns CREATED_BY and CHARACTER_SET. The contents of such a table might resemble the following:
CREATED_BY CHARACTER_SET ---------- ------------- ... JSMITH WE8MSWIN1252 JKOWALSKI EE8MSWIN1250 SKUZNETSOV CL8MSWIN1251 WLI ZHS16GBK ...
Now, set the Exclude from Conversion property of the CUSTOMER_NAME_ORIGINAL column to Yes to prevent data from being corrupted while the rest of the database is converted.
Check for possible length issues in CUSTOMER_NAME_ORIGINAL by running the following SQL:
SELECT c.ROWID
FROM customers c, created_by_to_charset_mapping csm
WHERE VSIZE(CONVERT(c.customer_name_original,
'AL32UTF8',
csm.character_set)) > 80
AND c.created_by = csm.created_by
If no rows are returned, there are no length issues. Otherwise, the returned rowids will help you locate the problematic values.
When the database is ready, convert it to AL32UTF8. Change the application configuration as required for the new database character set.
After the database conversion, run the following update statement:
UPDATE customers c
SET c.customer_name_original =
(SELECT CONVERT(c.customer_name_original,
'AL32UTF8',
csm.character_set)
FROM created_by_to_charset_mapping csm
WHERE csm.created_by = c.created_by)
This will convert the individual values of the column according to their assumed character set. Let employees who entered the customer data or who speak the relevant languages verify the post-conversion values for correctness.
Advanced Convertibility Issues
This section describes less frequently encountered convertibility issues that are not currently handled automatically by the DMU and might require that you perform additional scanning and cleansing steps outside of the tool.
It contains these topics:
Convertibility Issues: Uniqueness Validation
There are two situations when some rows in a table might no longer satisfy a unique or primary key constraint after database contents have been converted to Unicode:
-
A unique or primary key column has data with length issues, that is, some values expand in conversion beyond the column or data type length limit, and you set the property "Allow Conversion of Data with Issues" of this column to Yes. In such a case, the DMU will automatically truncate column values during the conversion step so that they fit into the existing length constraint. However, a truncated value may become identical with another value already in the column from which it differed only be the truncated suffix.
-
In various Oracle character sets, there are multiple character codes that map to a single Unicode code point. This is usually a result of:
-
an attempt to provide compatibility mapping for historical changes to a character set definition or to its interpretation by different vendors
-
an attempt to provide simplified mapping for codes that cannot be exactly mapped to Unicode, for example, because the actual mapping consists of a sequence of Unicode codes, and this is not supported by Oracle's conversion architecture
-
Unicode Standard unification rules, which cause certain groups of Han (Chinese) characters to get a single code point assigned, even though characters in such a group may be separately encoded in legacy East Asian character sets
If two character values in a single column differ only by characters that have the same mapping to Unicode in the assumed character set of the column, they become identical after conversion to Unicode.
The following character sets supported by the DMU have multiple codes that map to the same Unicode code point:
-
BG8PC437S
-
IW8MACHEBREW
-
IW8MACHEBREWS
-
JA16EUCTILDE
-
JA16MACSJIS
-
JA16SJIS
-
JA16SJISTILDE
-
JA16SJISYEN
-
JA16VMS
-
KO16KSCCS
-
LA8ISO6937
-
ZHS16MACCGB231280
-
ZHT16BIG5
-
ZHT16CCDC
-
ZHT16HKSCS
-
ZHT16HKSCS31
-
ZHT16MSWIN950
You can use the Oracle Locale Builder utility to check which character codes are affected. See Oracle Database Globalization Support Guide for more information about this utility.
If you suspect that a unique or primary key constraint might be affected by one of the above two issues, you can verify if you indeed have a problem by attempting to create an appropriate unique functional index. For example, if you have a unique or primary key constraint on character columns
tab1.col1andtab1.col2and a numeric columntab1.col3, attempt to create the following index:CREATE UNIQUE INDEX i_test ON tab1(SYS_OP_CSCONV(col1,'AL32UTF8','<assumed character set of col1>'), SYS_OP_CSCONV(col2,'AL32UTF8','<assumed character set of col2>'), col3) TABLESPACE ...Substitute
'UTF8'for'AL32UTF8', if this is the actual target character set. The third parameter toSYS_OP_CSCONVmay be omitted, if the assumed character set of a column is the same as the database character set (default). If the statement fails reporting "ORA-01452: cannot CREATE UNIQUE INDEX; duplicate keys found", there is a uniqueness problem in the column.The
CREATEINDEXstatement above assumes that you do not plan any scheduled lengthening of the columns and the columns are not defined using character length semantics. If you plan to extendcol1to n1 bytes andcol2to n2 bytes, use the following statement:CREATE UNIQUE INDEX i_test ON tab1(SYS_OP_CSCONV(SUBSTRB(RPAD(col1,n1,' '),1,n1), 'AL32UTF8','<assumed character set of col1>'), SYS_OP_CSCONV(SUBSTRB(RPAD(col2,n2,' '),1,n2), 'AL32UTF8','<assumed character set of col2>'), col3) TABLESPACE ...;Substitute
'UTF8'for'AL32UTF8', if the target character set is UTF8.If
col1andcol2are defined using character length semantics and their character lengths are, respectively, n1 and n2, use the following statement:CREATE UNIQUE INDEX i_test ON tab1(SYS_OP_CSCONV(SUBSTRB(RPAD(col1,4*n1,' '),1,4*n1), 'AL32UTF8','<assumed character set of col1>'), SYS_OP_CSCONV(SUBSTRB(RPAD(col2,4*n2,' '),1,4*n2), 'AL32UTF8','<assumed character set of col2>'), col3) TABLESPACE ...;Substitute
'UTF8'for'AL32UTF8'and 3* for 4*, if the target character set is UTF8. -
Convertibility Issues: Index Size
The maximum size of an index key in an Oracle database index – that is, the sum of maximum byte lengths of all key columns plus rowid length plus the number of length bytes – cannot exceed the data block size in the tablespace of the index minus around 25% overhead.
If the maximum byte length of a character column belonging to an index key increases during database conversion, either because:
-
it is being recalculated from the column character length for the new database character set
or
-
a lengthening cleansing action is defined on the column
The maximum byte length may cause the index key to exceed its allowed maximum length.
In this release, the DMU does not proactively verify index key lengths that change in the conversion step. Therefore, "ORA-01450: maximum key length (maximum) exceeded" or "ORA-01404: ALTER COLUMN will make an index too large" may be reported during conversion from an ALTER TABLE, CREATE INDEX, or ALTER DATABASE CHARACTER SET statement.
Before attempting conversion, you should review all indexes defined on VARCHAR2 and CHAR columns that have a lengthening cleansing actions scheduled or that use character length semantics to verify that they are not affected by this issue. The easiest approach is to test the migration on a copy of the original database. The copy should include the DMU repository with all planned cleansing actions. The actual application data does not affect the test so you can truncate all large convertible tables to shorten the test time.
Convertibility Issues: Partition Range Integrity
While the DMU does not support converting a database in which any partition bounds require conversion, you may want to migrate such a database using Data Pump utilities. While preparing for the migration process, you should consider the following potential issues with partition integrity.
Oracle Database distributes table rows among range partitions by comparing values of the partitioning key columns with partition bounds. This comparison uses binary sort order, that is, the byte representations of values, as stored on disk, are compared byte by byte. With character columns, the representation depends on the database character set and may change in conversion to Unicode. If the binary representation of partition bounds changes, the partitions might get reordered and the distribution of rows among partitions might change significantly.
You should analyze all range partitioned tables with convertible data in partitioning columns and, if required, adjust their partition definitions, so that rows are still distributed according to your expectations after the database migration to Unicode.
While very improbable, partition range bounds and partition list values may also suffer from the uniqueness issue described in "Convertibility Issues: Uniqueness Validation". If such an issue is encountered for a partitioned table, the table cannot be imported successfully without partition definitions being adjusted accordingly.
Convertibility Issues: Objects in the Recycle Bin
The DMU scans character columns in tables that have been dropped and are in the recycle bin like normal tables. Their scan results are included in the database scan report. Unlike the normal application tables, the dropped tables in recycle bin are not allowed to contain data that requires conversion. You cannot start the conversion step until tables with convertible data are removed from the recycle bin.
No cleansing actions are supported on dropped tables.
Convertibility Issues: PL/SQL Local Identifiers Greater Than 30 Bytes
While the DMU does not support converting names of PL/SQL stored modules, that is, stored procedures, stored functions and packages, it does automatically convert PL/SQL source code and view definitions including non-ASCII characters in:
-
names of procedures, functions, and types defined in packages
-
local identifiers, such as variable names and type names
-
character literals
-
comments
In the conversion step, the DMU fetches the relevant CREATE OR REPLACE PACKAGE|PACKAGE BODY|PROCEDURE|FUNCTION|TYPE|TYPE BODY|VIEW statements from the data dictionary, converts them to the target character set and, after the database character set has been changed to UTF8 or AL32UTF8, executes them.
The DMU does not check if any converted identifier exceeds its length constraint (usually 30 bytes). If an identifier becomes longer than allowed after conversion to Unicode, the resulting PL/SQL module will be created but its compilation will fail, usually reporting "PLS-00114: identifier '<identifier>' too long". The status of the module will be "invalid".
You should verify the status of all PL/SQL stored modules after the database conversion. If any module is in the invalid state because of an identifier being too long, you must manually shorten the identifier – in its definition and in all places where it is referenced.
Adapting Applications for Unicode Migration
The migration of a database to Unicode always impacts applications connecting to this database. The scale of the impact depends on multiple factors, such as the following:
-
Do you want the applications to process new languages, which the database will now be able to store?
Support for new languages usually entails the need to adapt applications to process Unicode data. Applications that have been programmed to process only single-byte character sets will need significant changes to be able to process the full Unicode character repertoire. On the other hand, applications that will work with the same limited number of characters as before may require only minimal changes, taking advantage of Oracle client/server character set conversion.
-
Will languages with complex scripts require GUI support from the applications?
Complex script-rendering capabilities are necessary to display and accept text written in complex scripts, such as Arabic or Indian. Complex rendering includes, among other requirements, combining adjacent characters, where some fragments read from right-to-left, while some are left-to-right, as well as changing character shape depending on the character's position in a word.
-
What technologies are the applications built with?
Depending on the development framework in which the applications have been developed, modifying them to accept new languages may be relatively easy or very difficult. Fortunately, most modern environments, such as Java or Microsoft Windows, offer built-in or installable support for complex script rendering and Unicode processing. Applications can take advantage of this support, which simplifies the adaptation process, but does not eliminate it.
-
Are the applications developed in-house or by a third-party vendor?
Obviously, you can adapt only those applications of which you have the source code. Applications developed by vendors must be adapted by those vendors. If this turns out to be impossible, you may have to replace your applications with another software solution.
In addition to these considerations, requirements to make migration-related changes to applications can result from:
-
Table structure changes coming from cleansing actions, columns being lengthened or migrated to another data type.
-
Changed characteristics of the database character set, such as higher maximum byte width of a character.
-
Additional requirements of the new languages to be processed. This might include new sorting rules, new date or number formatting rules, non-Gregorian calendar support, and so on.
-
Changed binary sort order of strings in Unicode compared to the old legacy character set.
Details of adapting applications for new languages exceed the scope of this guide, but the following sections describe the minimal changes that may be required to continue running existing applications with a migrated database.
Running Legacy Applications Unchanged
You might want to run some of your existing applications unchanged after migration of their back-end database to Unicode. For example, you might not have access to the source code of the applications to adapt them for Unicode or modifying the applications may be economically unjustified.
The main requirement for running an application unchanged after migration of its back-end database to Unicode is that all Unicode characters that the application may encounter also exist in a legacy character set for which the application was originally written. That is, if the application was written, for example, to process only the ISO 8859-1 standard character set (WE8ISO8859P1), then only the corresponding Unicode characters U+0000 - U+007F and U+00A0 - U+00FF are allowed in the subset of database contents accessed by the application.
If this requirement is fulfilled, the client character set for the application, as specified in the NLS_LANG environment setting, shall be set to the above legacy character set (in practice, it usually means that NLS_LANG remains the sam before and after the migration) and the client/server communication protocol will take care of converting character data between the legacy encoding used by the application and the Unicode encoding used by the database.
If the only characters processed by an application are standard US7ASCII characters, the application does not require any modification at all, because UTF8 and AL32UTF8 binary codes of all ASCII characters are identical to US7ASCII. Therefore, the processed bytes do not differ before and after the database character set migration.
Binary codes of characters outside of the ASCII range - for example, accented Latin letters - remain the same on the client side but change on the database side after the database character set change. The most important difference is usually the number of bytes in the character codes. While accented Latin letters, and also Cyrillic or Greek letter, occupy one byte each in single-byte legacy character sets, such as WE8MSWIN1252 or CL8MSWIN1251, they occupy two bytes in UTF8 and AL32UTF8. Certain special characters, such as the Euro currency symbol, occupy three bytes. Therefore, any affected columns, PL/SQL variables and user-defined data type attributes on the database side whose lengths are expressed in bytes need to be adjusted to accommodate additional bytes that are added in the client/server character set conversion when data comes from the application to the database.
If an application does not rely on the database to control data lengths, controlling the length limits itself, and if all data processed by the application is entered into the database only through the application, byte lengths of affected columns, PL/SQL variables, and user-defined data types attributes may be adjusted by increasing them appropriately, usually by multiplying by three. If an application relies on the database to control data lengths, by handling the returned errors (such as ORA-12899), or if data for the application may come from external sources, the recommended way of adjusting lengths in SQL and PL/SQL is to keep the original absolute length number and to change the length semantics from bytes to characters. That is, a VARCHAR2(10 [BYTE]) column or PL/SQL variable should become a VARCHAR2(10 CHAR) column or variable.
As the above length issues obviously affect the existing database contents as well, the column and attribute lengths usually have to be increased already as part of the cleansing step of the database character set migration process. The PL/SQL variables must be adjusted independently, unless their data type is expressed using the %TYPE attribute.
A significant problem exists because of absolute length limits of basic character data types. A VARCHAR2 value stored in a database cannot exceed 4000 bytes and a CHAR value cannot exceed 200 types. Therefore, you can expand VARCHAR2 columns and attributes only up to 1333 (in UTF8) or 1000 (in AL32UTF8) characters to have a guarantee that they can really store that number of random character codes without hitting the data type limit. If longer values are already commonly processed by an application, it may be impossible to continue running the application without modifying it, for example, to use the CLOB data type instead of VARCHAR2.
Independently of the above length issues, some applications may rely on a specific binary sorting order of queried character values coming from the database. Characters of the US7ASCII and WE8ISO8859P1 character sets keep the same order in UTF8 and AL32UTF8 but characters from other character sets do not. You may need to create custom linguistic definitions using the Oracle Local Builder utility to simulate the binary order of a legacy character set in an UTF8 or AL32UTF8 database. In general, Oracle recommends that you modify the application to not rely on a specific binary sort order instead of creating custom linguistic definitions, which increase complexity and cost of database administration and may impact query performance.
In addition to these changes, the database side of the application code might require further changes required by the new Unicode character encoding, as described in the next section.
See Also:
Oracle Database Globalization Support Guide for more information about creating custom linguistic definitionsChanges to SQL and PL/SQL Code
Because SQL and PL/SQL code runs inside the database, its processing character set, that is, the character set in which the processed data is encoded - in this case, the database character set - always changes after a database migration to Unicode. This is different from the client-side application code, which can retain its processing character set after migration if NLS_LANG setting is left unchanged.
Most PL/SQL statements, expressions, functions, and procedures work independently of the database character set and require no adaptation. However, there are still of number of functions that provide different results for different processing character sets. SQL and PL/SQL code containing the following functions must be reviewed and modified as required to account for the migration to Unicode:
-
Functions depending on specific binary character codes:
CHR,ASCII, andDUMP -
Functions depending on character code widths in bytes:
LENGTHB,VSIZE -
Functions working with byte offsets:
INSTRB,SUBSTRB -
Character set conversion functions:
CONVERT -
String-to-binary casting:
UTL_RAW.CAST_TO_VARCHAR2,UTL_RAW.CAST_TO_RAW,UTL_I18N.STRING_TO_RAW,UTL_I18N.RAW_TO_CHAR
Also, the standard package UTL_FILE allows character data to be stored in external files in the database character set. Consumers of those files may need to be adapted to deal with the new file encoding.
The SQL and PL/SQL expressions must be reviewed in view definitions, PL/SQL stored modules, user-defined data type methods, triggers, check constraints, but also event rule conditions (see DBMS_RULE_ADM), row-level security (RLS/VPD) policies (see DBMS_RLS), fine-grained auditing policies (see DBMS_FGA) and any other auxiliary database objects definitions that may reference SQL or PL/SQL expressions.
Caution:
While uncommon, row-level security or fine-grained auditing policies may be defined using SQL expressions that are sensitive to character encoding. Ensure that you review all such policies to verify that protection of sensitive data is not compromised because of the database character set change.Repairing Database Character Set Metadata
If your database has been in what is commonly called a pass-through configuration, where the client character set is defined (usually through the NLS_LANG client setting) to be equal to the database character set, the character data in your database could be stored in a different character set from the declared database character set. In this scenario, the recommended solution is to migrate your database to Unicode by using the DMU assumed database character set feature to indicate the actual character set for the data. In case migrating to Unicode is not immediately feasible due to business or technical constraints, it would be desirable to at least correct the database character set declaration to match with the database contents.
With Database Migration Assistant for Unicode, release 1.2, you can repair the database character set metadata in such cases using the CSREPAIR script. The CSREPAIR script works in conjunction with the DMU client and accesses the DMU repository. It can be used to change the database character set declaration to the real character set of the data only after the DMU has performed a full database scan by setting the Assumed Database Character Set property to the target character set and no invalid representation issues have been reported, which verifies that all existing data in the database is defined according to the assumed database character set. Note that CSREPAIR only changes the database character set declaration in the data dictionary metadata and does not convert any database data.
You can find the CSREPAIR script under the admin subdirectory of the DMU installation. The requirements when using the CSREPAIR script are:
-
You must first perform a successful full database scan in the DMU with the Assumed Database Character Set property set to the real character set of the data. In this case, the assumed database character set must be different from the current database character set or else nothing will be done. The
CSREPAIRscript will not proceed if the DMU reports the existence of data with invalid binary representation. It will, however, proceed if data that is changeless, convertible or exceeding length limits is reported in the scan results. -
The target character set in the assumed database character set must be a binary superset of US7ASCII.
-
Only repairing from single-byte to single-byte character sets or multi-byte to multi-byte character sets is allowed as no conversion of
CLOBdata will be attempted. -
If you set the assumed character set at the column level, then the value must be the same as the assumed database character set. Otherwise,
CSREPAIRwill not run. -
You must have the
SYSDBAprivilege to runCSREPAIR. To runCSREPAIRon a pluggable database (PDB) in Oracle Database 12c, you must be either theSYSuser or a common user with theSYSDBAprivilege in both the local PDB and the CDB.
Example: Using CSREPAIR
A typical example is storing WE8MSWIN1252 data in a WE8ISO8859P1 database via the pass-through configuration. To correct the database character set from WE8ISO8859P1 to WE8MSWIN1252, perform the following steps:
-
Set up the DMU and connect to the target WE8ISO8859P1 database.
-
Open the Database Properties tab in the DMU.
-
Set the Assumed Database Character Set property to WE8MSWIN1252.
-
Use the DMU to perform a full database scan.
-
Open the Database Scan Report and verify there is no data reported under the Invalid Representation category.
-
Exit from the DMU client.
-
Start the SQL*Plus utility and connect as a user with the
SYSDBAprivilege. -
Run the
CSREPAIRscript:SQL> @@CSREPAIR.PLBUpon completion, you should get the message:
The database character set has been successfully changed to WE8MSWIN1252. You must restart the database now.
-
Shut down and restart the database.
Updating the DMU Version
You can check for and install the latest version of the DMU by using the DMU live update feature. It enables you to find out if a new version of the DMU is available from the DMU update center. If you decide to upgrade to the new version, the live update feature can download the software package and upgrade the existing installation for you automatically.
The DMU can detect new version availability at startup. If a new version is found, a message will be shown at the lower-right corner of the main window.
To check for updates to the DMU version:
-
To start the live update feature, click on the message at the bottom of the main window or choose Check for Updates under the Help menu.
Figure 5-1 Check for Updates Wizard - Welcome
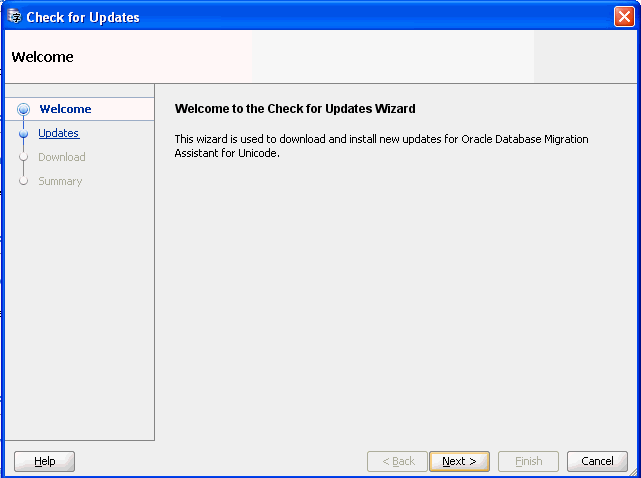
Description of "Figure 5-1 Check for Updates Wizard - Welcome"
The Check For Updates wizard appears. The wizard checks for the availability of DMU updates from the DMU update center and helps you download and install the updates automatically.
-
Click Next. The wizard displays the available DMU updates. If there is no newer version available than the currently installed version, then the message will indicate your DMU version is up-to-date.
Figure 5-2 Check for Updates Wizard - Available Versions
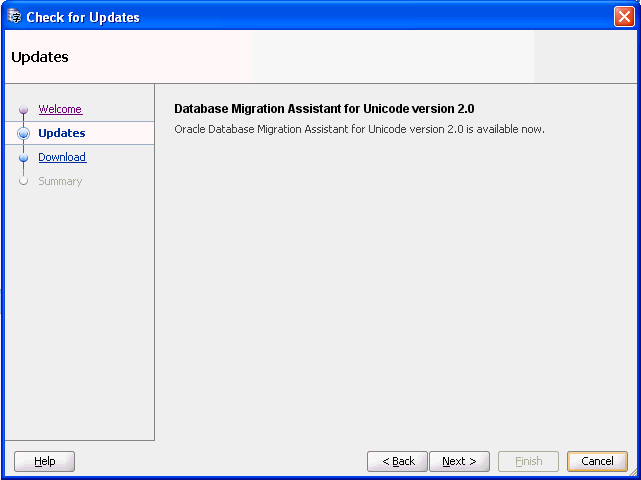
Description of "Figure 5-2 Check for Updates Wizard - Available Versions"
-
Click Next. The Wizard begins to download the new DMU package from the update center. Wait for the download to complete.
Figure 5-3 Check for Updates Wizard - Downloading New DMU Version
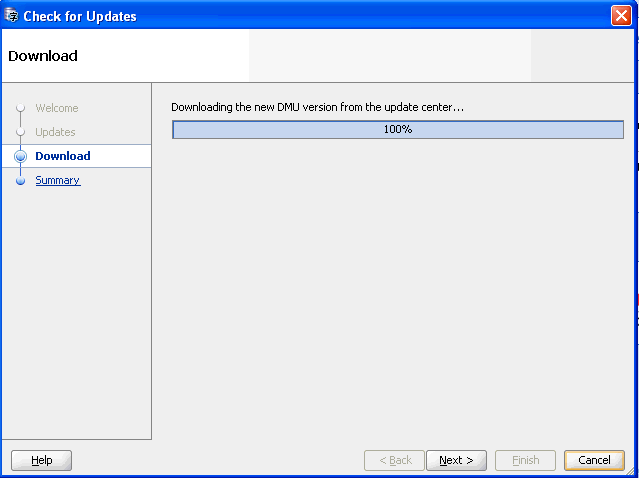
Description of "Figure 5-3 Check for Updates Wizard - Downloading New DMU Version"
-
Click Next. The Summary page is displayed. On this page, you have the option of either exiting the DMU and installing the new version immediately or completing the installation later. If you choose Yes, the DMU will exit and start the installation process in the background. After the installation is complete, the DMU restarts in the new version.
Figure 5-4 Check for Updates Wizard - Summary
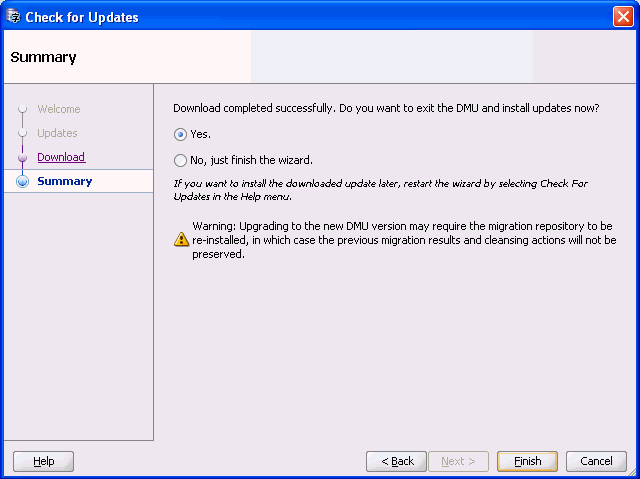
Description of "Figure 5-4 Check for Updates Wizard - Summary"
Note that upgrading to a new DMU version may require the migration repository to be re-installed. As a result, the previous scan results and scheduled cleansing actions will not be preserved after the upgrade.
-
If you are behind a firewall or use a proxy to access web pages, you may need to configure your proxy settings on the Auto Update page of the Preferences dialog box before you can connect to the DMU update center.
To configure your proxy settings, choose Preferences under the Tools menu. The Preferences dialog appears.
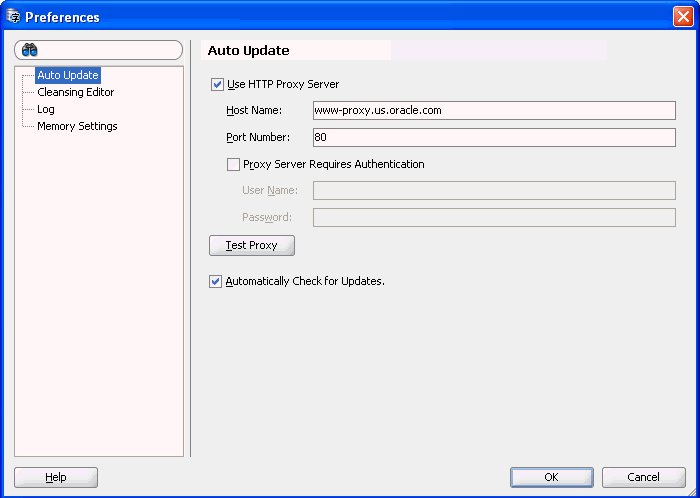
If you select Use HTTP Proxy Server, enter the values into the Host Name and Port Number fields.
If you select Proxy Server Requires Authentication, enter the values into the User Name and Password fields.
If you select Automatically Check for Updates, the DMU checks to see if there is a new DMU version during startup.
Click OK to close the Preferences dialog and finish setting the proxy server.
DMU Accessibility Information
It is our goal to make Oracle Products, Services, and supporting documentation accessible to the disabled community. Oracle Database Migration Assistant for Unicode supports accessibility features.
For additional accessibility information for Oracle products, see the Oracle Accessibility Program page at: http://www.oracle.com/accessibility/.
Using a Screen Reader and Java Access Bridge with the DMU
In order for assistive technologies, like screen readers, to work with Java-based applications and applets, the Windows-based computer must also have Sun's Java Access Bridge installed.
To make the best use of our accessibility features, Oracle Corporation recommends the following minimum configuration:
-
Windows XP, Windows Vista
-
Java J2SE 1.6.0_24
-
Java Access Bridge 2.0.1
-
JAWS 12.0.522
-
Microsoft Internet Explorer 7.0 or later
-
Mozilla Firefox 3.5 or later
Please refer to the following procedures to set up a screen reader and Java Access Bridge.
-
Install the screen reader, if it is not already installed.
Refer to the documentation for your screen reader for more information about installation.
-
Install the DMU.
-
Download Java Access Bridge for Windows version 2.0.1. The file you will download is
accessbridge-2_0_1.zip. It is available from:http://www.oracle.com/technetwork/java/javase/tech/index-jsp-136191.htmlRefer to the Java Access Bridge documentation available from this web site for more information about installation and the Java Access Bridge.
-
Extract (unzip) the contents to a folder, for example,
accessbridge_home. -
Install Java Access Bridge by running
Install.exefrom the<accessbridge_home>\installerfolder.The installer first checks the JDK version for compatibility, then the Available Java virtual machines dialog displays.
-
Click Search Disks. Then select to search only the drive that contains the JDK version in the program files directory (if it exists).
The search process can take a long time on a large disk with many instances of JDK, or when searching multiple disks. However, unless you complete an exhaustive search of your disk, Access Bridge will not be optimally configured, and will not be correctly installed to all of the Java VMs on your system. After selecting the disk to search, click Search.
-
Confirm that you want to install the Java Access Bridge into each of the Java virtual machines displayed in the dialog, by clicking Install in All.
-
Click OK when you see the Installation Completed message.
-
Confirm that the following files have been installed in the
Winnt\System32directory (o the equivalent Windows XP or Vista directory), or copy them from<accessbridge_home>\installerfilesas they must be in the system path in order to work with the DMU:-
JavaAccessBridge.dll -
JAWTAccessBridge.dll -
WindowsAccessBridge.dll
Note that the system directory is required in the
PATHsystem variable. -
-
Confirm that the following files have been installed in the
jdk\jre\lib\extdirectory, or copy them from<accessbridge_home>\installerfiles:-
access-bridget.jar -
jaccess-1_4.jar
-
-
Confirm that the file
accessibility.propertieshas been installed in thejdk\jre\libdirectory, or copy it from\installerfiles. -
Start your screen reader.
-
Start the DMU.
The steps above assume you are running Windows and using a Windows-based screen reader. A console window that contains error information (if any) will open first and then the main DMU window will appear, once the DMU has started. Any messages that appear will not affect the DMU functionality.