1 Introduction to Oracle RAC
This chapter introduces Oracle Real Application Clusters (Oracle RAC) and describes how to install, administer, and deploy Oracle RAC.
This chapter includes the following topics:
Overview of Oracle RAC
Noncluster Oracle databases have a one-to-one relationship between the Oracle database and the instance. Oracle RAC environments, however, have a one-to-many relationship between the database and instances. An Oracle RAC database can have up to 100 instances,Foot 1 all of which access one database. All database instances must use the same interconnect, which can also be used by Oracle Clusterware.
Oracle RAC databases differ architecturally from noncluster Oracle databases in that each Oracle RAC database instance also has:
-
At least one additional thread of redo for each instance
-
An instance-specific undo tablespace
The combined processing power of the multiple servers can provide greater throughput and Oracle RAC scalability than is available from a single server.
A cluster comprises multiple interconnected computers or servers that appear as if they are one server to end users and applications. The Oracle RAC option with Oracle Database enables you to cluster Oracle databases. Oracle RAC uses Oracle Clusterware for the infrastructure to bind multiple servers so they operate as a single system.
Oracle Clusterware is a portable cluster management solution that is integrated with Oracle Database. Oracle Clusterware is a required component for using Oracle RAC that provides the infrastructure necessary to run Oracle RAC. Oracle Clusterware also manages resources, such as Virtual Internet Protocol (VIP) addresses, databases, listeners, services, and so on. In addition, Oracle Clusterware enables both noncluster Oracle databases and Oracle RAC databases to use the Oracle high-availability infrastructure. Oracle Clusterware along with Oracle Automatic Storage Management (Oracle ASM) (the two together comprise the Oracle Grid Infrastructure) enables you to create a clustered pool of storage to be used by any combination of noncluster and Oracle RAC databases.
Oracle Clusterware is the only clusterware that you need for most platforms on which Oracle RAC operates. If your database applications require vendor clusterware, then you can use such clusterware in conjunction with Oracle Clusterware if that vendor clusterware is certified for Oracle RAC.
See Also:
Oracle Clusterware Administration and Deployment Guide and Oracle Grid Infrastructure Installation Guide for more detailsFigure 1-1 shows how Oracle RAC is the Oracle Database option that provides a single system image for multiple servers to access one Oracle database. In Oracle RAC, each Oracle instance must run on a separate server.
Figure 1-1 Oracle Database with Oracle RAC Architecture
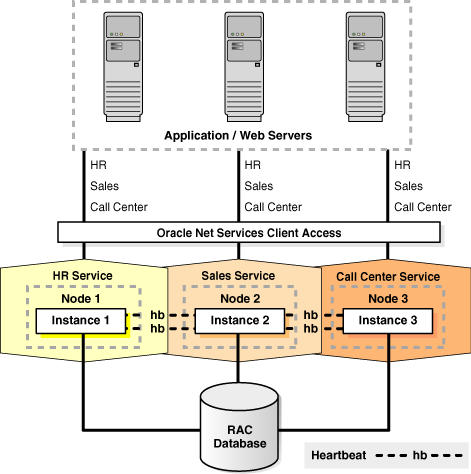
Description of "Figure 1-1 Oracle Database with Oracle RAC Architecture"
Traditionally, an Oracle RAC environment is located in one data center. However, you can configure Oracle RAC on an extended distance cluster, which is an architecture that provides extremely fast recovery from a site failure and allows for all nodes, at all sites, to actively process transactions as part of a single database cluster. In an extended cluster, the nodes in the cluster are typically dispersed, geographically, such as between two fire cells, between two rooms or buildings, or between two different data centers or cities. For availability reasons, the data must be located at both sites, thus requiring the implementation of disk mirroring technology for storage.
If you choose to implement this architecture, you must assess whether this architecture is a good solution for your business, especially considering distance, latency, and the degree of protection it provides. Oracle RAC on extended clusters provides higher availability than is possible with local Oracle RAC configurations, but an extended cluster may not fulfill all of the disaster-recovery requirements of your organization. A feasible separation provides great protection for some disasters (for example, local power outage or server room flooding) but it cannot provide protection against all types of outages. For comprehensive protection against disasters—including protection against corruptions and regional disasters—Oracle recommends the use of Oracle Data Guard with Oracle RAC, as described in the Oracle Database High Availability Overview and on the Maximum Availability Architecture (MAA) Web site at
http://www.oracle.com/technology/deploy/availability/htdocs/maa.htm
Oracle RAC is a unique technology that provides high availability and scalability for all application types. The Oracle RAC infrastructure is also a key component for implementing the Oracle enterprise grid computing architecture. Having multiple instances access a single database prevents the server from being a single point of failure. Oracle RAC enables you to combine smaller commodity servers into a cluster to create scalable environments that support mission critical business applications. Applications that you deploy on Oracle RAC databases can operate without code changes.
Overview of Oracle Real Application Clusters One Node
Oracle Real Application Clusters One Node (Oracle RAC One Node) is an option to Oracle Database Enterprise Edition available since Oracle Database 11g release 2 (11.2). Oracle RAC One Node is a single instance of an Oracle RAC-enabled database running on one node in the cluster, only, under normal operations. This option adds to the flexibility that Oracle offers for database consolidation while reducing management overhead by providing a standard deployment for Oracle databases in the enterprise. Oracle RAC One Node database requires Oracle Grid Infrastructure and, therefore, requires the same hardware setup as an Oracle RAC database.
Oracle supports Oracle RAC One Node on all platforms on which Oracle RAC is certified. Similar to Oracle RAC, Oracle RAC One Node is certified on Oracle Virtual Machine (Oracle VM). Using Oracle RAC or Oracle RAC One Node with Oracle VM increases the benefits of Oracle VM with the high availability and scalability of Oracle RAC.
With Oracle RAC One Node, there is no limit to server scalability and, if applications grow to require more resources than a single node can supply, then you can upgrade your applications online to Oracle RAC. If the node that is running Oracle RAC One Node becomes overloaded, then you can relocate the instance to another node in the cluster. With Oracle RAC One Node you can use the Online Database Relocation feature to relocate the database instance with no downtime for application users. Alternatively, you can limit the CPU consumption of individual database instances per server within the cluster using Resource Manager Instance Caging and dynamically change this limit, if necessary, depending on the demand scenario.
Using the Single Client Access Name (SCAN) to connect to the database, clients can locate the service independently of the node on which it is running. Relocating an Oracle RAC One Node instance is therefore mostly transparent to the client, depending on the client connection. Oracle recommends to use either Application Continuity and Oracle Fast Application Notification or Transparent Application Failover to minimize the impact of a relocation on the client.
Oracle RAC One Node databases are administered slightly differently from Oracle RAC or noncluster databases. For administrator-managed Oracle RAC One Node databases, you must monitor the candidate node list and make sure a server is always available for failover, if possible. Candidate servers reside in the Generic server pool and the database and its services will fail over to one of those servers.
For policy-managed Oracle RAC One Node databases, you must ensure that the server pools are configured such that a server will be available for the database to fail over to in case its current node becomes unavailable. In this case, the destination node for online database relocation must be located in the server pool in which the database is located. Alternatively, you can use a server pool of size 1 (one server in the server pool), setting the minimum size to 1 and the importance high enough in relation to all other server pools used in the cluster, to ensure that, upon failure of the one server used in the server pool, a new server from another server pool or the Free server pool is relocated into the server pool, as required.
Notes:
-
Oracle RAC One Node supports Transaction Guard and Application Continuity for failing clients over.
-
To prepare for all failure possibilities, you must add at least one Dynamic Database Service (Oracle Clusterware-managed database service) to an Oracle RAC One Node database.
See Also:
-
Oracle Real Application Clusters Installation Guide for Linux and UNIX for information about installing Oracle RAC One Node databases
Overview of Oracle Clusterware for Oracle RAC
Oracle Clusterware provides a complete, integrated clusterware management solution on all Oracle Database platforms. This clusterware functionality provides all of the features required to manage your cluster database including node membership, group services, global resource management, and high availability functions.
You can install Oracle Clusterware independently or as a prerequisite to the Oracle RAC installation process. Oracle Database features, such as services, use the underlying Oracle Clusterware mechanisms to provide advanced capabilities. Oracle Database also continues to support select third-party clusterware products on specified platforms.
Oracle Clusterware is designed for, and tightly integrated with, Oracle RAC. You can use Oracle Clusterware to manage high-availability operations in a cluster. When you create an Oracle RAC database using any of the management tools, the database is registered with and managed by Oracle Clusterware, along with the other required components such as the VIP address, the Single Client Access Name (SCAN) (which includes the SCAN VIPs and the SCAN listener), Oracle Notification Service, and the Oracle Net listeners. These resources are automatically started when the node starts and automatically restart if they fail. The Oracle Clusterware daemons run on each node.
Anything that Oracle Clusterware manages is known as a CRS resource. A CRS resource can be a database, an instance, a service, a listener, a VIP address, or an application process. Oracle Clusterware manages CRS resources based on the resource's configuration information that is stored in the Oracle Cluster Registry (OCR). You can use SRVCTL commands to administer any Oracle-defined CRS resources. Oracle Clusterware provides the framework that enables you to create CRS resources to manage any process running on servers in the cluster which are not predefined by Oracle. Oracle Clusterware stores the information that describes the configuration of these components in OCR that you can administer as described in the Oracle Clusterware Administration and Deployment Guide.
Overview of Oracle RAC Architecture and Processing
At a minimum, Oracle RAC requires Oracle Clusterware software infrastructure to provide concurrent access to the same storage and the same set of data files from all nodes in the cluster, a communications protocol for enabling interprocess communication (IPC) across the nodes in the cluster, enable multiple database instances to process data as if the data resided on a logically combined, single cache, and a mechanism for monitoring and communicating the status of the nodes in the cluster.
The following sections describe these concepts in more detail:
Understanding Cluster-Aware Storage Solutions
An Oracle RAC database is a shared everything database. All data files, control files, SPFILEs, and redo log files in Oracle RAC environments must reside on cluster-aware shared disks, so that all of the cluster database instances can access these storage components. Because Oracle RAC databases use a shared everything architecture, Oracle RAC requires cluster-aware storage for all database files.
In Oracle RAC, the Oracle Database software manages disk access and is certified for use on a variety of storage architectures. It is your choice how to configure your storage, but you must use a supported cluster-aware storage solution. Oracle Database provides the following storage options for Oracle RAC:
Oracle RAC and Network Connectivity
All nodes in an Oracle RAC environment must connect to at least one Local Area Network (LAN) (commonly referred to as the public network) to enable users and applications to access the database. In addition to the public network, Oracle RAC requires private network connectivity used exclusively for communication between the nodes and database instances running on those nodes. This network is commonly referred to as the interconnect.
The interconnect network is a private network that connects all of the servers in the cluster. The interconnect network must use at least one switch and a Gigabit Ethernet adapter.
Notes:
-
Oracle supports interfaces with higher bandwidth but does not support using crossover cables with the interconnect.
-
Do not use the interconnect (the private network) for user communication, because Cache Fusion uses the interconnect for interinstance communication.
You must configure User Datagram Protocol (UDP) for the cluster interconnect, except in a Windows cluster. Windows clusters use the TCP protocol. On Linux and UNIX systems, you can configure Oracle RAC to use either the UDP or Reliable Data Socket (RDS) protocols for inter-instance communication on the interconnect. Oracle Clusterware uses the same interconnect using the UDP protocol, but cannot be configured to use RDS.
An additional network connectivity is required when using Network Attached Storage (NAS). Network attached storage can be typical NAS devices, such as NFS filers, or can be storage that is connected using Fibre Channel over IP, for example. This additional network communication channel should be independent of the other communication channels used by Oracle RAC (the public and private network communication). If the storage network communication must be converged with one of the other network communication channels, then you must ensure that storage-related communication gets first priority.
Overview of Using Dynamic Database Services to Connect to Oracle Databases
Applications should use the Dynamic Database Services feature to connect to an Oracle database over the public network. Dynamic Database Services enable you to define rules and characteristics to control how users and applications connect to database instances. These characteristics include a unique name, workload balancing and failover options, and high availability characteristics.
Users can access an Oracle RAC database using a client/server configuration or through one or more middle tiers, with or without connection pooling. By default, a user connection to an Oracle RAC database is established using the TCP/IP protocol but Oracle supports other protocols. Oracle RAC database instances must be accessed through the SCAN for the cluster.
See Also:
"Overview of Automatic Workload Management with Dynamic Database Services" for more informationOverview of Virtual IP Addresses
Oracle Clusterware hosts node virtual IP (VIP) addresses on the public network. Node VIPs are VIP addresses that clients use to connect to an Oracle RAC database. A typical connect attempt from a database client to an Oracle RAC database instance can be summarized, as follows:
-
The database client connects to SCAN (which includes a SCAN VIP on a public network), providing the SCAN listener with a valid service name.
-
The SCAN listener then determines which database instance hosts this service and routes the client to the local or node listener on the respective node.
-
The node listener, listening on a node VIP and a given port, retrieves the connection request and connects the client to the an instance on the local node.
If multiple public networks are used on the cluster to support client connectivity through multiple subnets, then the preceding operation is performed within a given subnet.
If a node fails, then the VIP address fails over to another node on which the VIP address can accept TCP connections, but it does not accept connections to the Oracle database. Clients that attempt to connect to a VIP address not residing on its home node receive a rapid connection refused error instead of waiting for TCP connect timeout messages. When the network on which the VIP is configured comes back online, Oracle Clusterware fails back the VIP to its home node, where connections are accepted. Generally, VIP addresses fail over when:
-
The node on which a VIP address runs fails
-
All interfaces for the VIP address fail
-
All interfaces for the VIP address are disconnected from the network
Oracle RAC 12c supports multiple public networks to enable access to the cluster through different subnets. Each network resource represents its own subnet and each database service uses a particular network to access the Oracle RAC database. Each network resource is a resource managed by Oracle Clusterware, which enables the VIP behavior previously described.
SCAN is a single network name defined either in your organization's Domain Name Server (DNS) or in the Grid Naming Service (GNS) that round robins to three IP addresses. Oracle recommends that all connections to the Oracle RAC database use the SCAN in their client connection string. Incoming connections are load balanced across the active instances providing the requested service through the three SCAN listeners. With SCAN, you do not have to change the client connection even if the configuration of the cluster changes (nodes added or removed). Unlike in previous releases, SCAN in Oracle RAC 12c fully supports multiple subnets, which means you can create one SCAN for each subnet in which you want the cluster to operate.
Restricted Service Registration in Oracle RAC
The valid node checking feature provides the ability to configure and dynamically update a set of IP addresses or subnets from which registration requests are allowed by the listener. Database instance registration with a listener succeeds only when the request originates from a valid node. The network administrator can specify a list of valid nodes, excluded nodes, or disable valid node checking. The list of valid nodes explicitly lists the nodes and subnets that can register with the database. The list of excluded nodes explicitly lists the nodes that cannot register with the database. The control of dynamic registration results in increased manageability and security of Oracle RAC deployments.
By default, valid node checking for registration (VNCR) is enabled. In the default configuration, registration requests from all nodes within the subnet of the SCAN listener can register with the listener. Non-SCAN listeners only accept registration from instances on the local node. Remote nodes or nodes outside the subnet of the SCAN listener must be included on the list of valid nodes by using the registration_invited_nodes_alias parameter in the listener.ora file or by modifying the SCAN listener using SRVCTL.
See Also:
Oracle Database Net Services Administrator's Guide for more information about VNCRAbout Oracle RAC Software Components
Oracle RAC databases generally have two or more database instances that each contain memory structures and background processes. An Oracle RAC database has the same processes and memory structures as a noncluster Oracle database and additional processes and memory structures that are specific to Oracle RAC. Any one instance's database view is nearly identical to any other instance's view in the same Oracle RAC database; the view is a single system image of the environment.
Each instance has a buffer cache in its System Global Area (SGA). Using Cache Fusion, Oracle RAC environments logically combine each instance's buffer cache to enable the instances to process data as if the data resided on a logically combined, single cache.
Note:
See Also:
Oracle Database Concepts for more information about the In-Memory Transaction ManagerTo ensure that each Oracle RAC database instance obtains the block that it requires to satisfy a query or transaction, Oracle RAC instances use two processes, the Global Cache Service (GCS) and the Global Enqueue Service (GES). The GCS and GES maintain records of the statuses of each data file and each cached block using a Global Resource Directory (GRD). The GRD contents are distributed across all of the active instances, which effectively increases the size of the SGA for an Oracle RAC instance.
After one instance caches data, any other instance within the same cluster database can acquire a block image from another instance in the same database faster than by reading the block from disk. Therefore, Cache Fusion moves current blocks between instances rather than re-reading the blocks from disk. When a consistent block is needed or a changed block is required on another instance, Cache Fusion transfers the block image directly between the affected instances. Oracle RAC uses the private interconnect for interinstance communication and block transfers. The GES Monitor and the Instance Enqueue Process manage access to Cache Fusion resources and enqueue recovery processing.
About Oracle RAC Background Processes
The GCS and GES processes, and the GRD collaborate to enable Cache Fusion. The Oracle RAC processes and their identifiers are as follows:
-
ACMS: Atomic Controlfile to Memory Service (ACMS)In an Oracle RAC environment, the
ACMSper-instance process is an agent that contributes to ensuring a distributed SGA memory update is either globally committed on success or globally aborted if a failure occurs. -
GTX0-j: Global Transaction ProcessThe
GTX0-jprocess provides transparent support for XA global transactions in an Oracle RAC environment. The database autotunes the number of these processes based on the workload of XA global transactions. -
LMON: Global Enqueue Service MonitorThe
LMONprocess monitors global enqueues and resources across the cluster and performs global enqueue recovery operations. -
LMD: Global Enqueue Service DaemonThe
LMDprocess manages incoming remote resource requests within each instance. -
LMS: Global Cache Service ProcessThe
LMSprocess maintains records of the data file statuses and each cached block by recording information in a Global Resource Directory (GRD). TheLMSprocess also controls the flow of messages to remote instances and manages global data block access and transmits block images between the buffer caches of different instances. This processing is part of the Cache Fusion feature. -
LCK0: Instance Enqueue ProcessThe
LCK0process manages non-Cache Fusion resource requests such as library and row cache requests. -
RMSn: Oracle RAC Management Processes (RMSn)The
RMSnprocesses perform manageability tasks for Oracle RAC. Tasks accomplished by anRMSnprocess include creation of resources related to Oracle RAC when new instances are added to the clusters. -
RSMN: Remote Slave Monitor manages background slave process creation and communication on remote instances. These background slave processes perform tasks on behalf of a coordinating process running in another instance.
Note:
Many of the Oracle Database components that this section describes are in addition to the components that are described for noncluster Oracle databases in Oracle Database Concepts.Overview of Automatic Workload Management with Dynamic Database Services
Services represent groups of applications with common attributes, service level thresholds, and priorities. Application functions can be divided into workloads identified by services. For example, Oracle E-Business Suite can define a service for each responsibility, such as general ledger, accounts receivable, order entry, and so on. A service can span one or more instances of an Oracle database, multiple databases in a global cluster, and a single instance can support multiple services. The number of instances that are serving the service is transparent to the application. Services provide a single system image to manage competing applications, and allow each workload to be managed as a unit.
Middle tier applications and clients select a service by specifying the service name as part of the connection in the TNS connect string. For example, data sources for Oracle WebLogic Server are set to route to a service. Using Net Easy*Connection, this connection comprises simply the service name and network address, as follows: user_name/password@SCAN/service_name. Server-side work such as Oracle Scheduler, Parallel Query, and Oracle Streams queues set the service name as part of the workload definition. For Oracle Scheduler, jobs are assigned to job classes and job classes execute within services. For Parallel Query and Parallel DML, the query coordinator connects to a service and the parallel query slaves inherit the service for the duration of the parallel execution. For Oracle Streams, streams queues are accessed using services. Work executing under a service inherits the thresholds and attributes for the service and is measured as part of the service.
Oracle Database Resource Manager binds services to consumer groups and priorities. This allows the database to manage the services in the order of their importance. For example, the DBA can define separate services for high priority online users and lower priority internal reporting applications. Likewise, the DBA can define Gold, Silver and Bronze services to prioritize the order in which requests are serviced for the same application. When planning the services for a system, the plan should include the priority of each service relative to the other services. In this way, Oracle Database Resource Manager can satisfy the priority-one services first, followed by the priority-two services, and so on.
See Also:
Oracle Database Administrator's Guide for more information about Oracle Database Resource ManagerWhen users or applications connect to a database, Oracle recommends that you use a service specified in the CONNECT_DATA portion of the connect string. Oracle Database automatically creates one database service when the database is created but the behavior of this service is different from that of database services that you subsequently create. To enable more flexibility in the management of a workload using the database, Oracle Database enables you to create multiple services and specify on which instances (or in which server pools) the services start. If you are interested in greater workload management flexibility, then continue reading this chapter to understand the added features that you can use with services.
Note:
The features discussed in this chapter do not work with the following default database services:DB_NAME, DB_UNIQUE_NAME, PDB_NAME, SYS$BACKGROUND, and SYS$USERS. Oracle strongly recommends that you do not use these services for applications to connect to the database. You must create cluster managed services to take advantage of these features. You can only manage the services that you create. Any service that the database create automatically is managed by the database server.Dynamic database services enable you to manage workload distributions to provide optimal performance for users and applications. Dynamic database services offer the following features:
-
Services: Oracle Database provides a powerful automatic workload management facility, called services, to enable the enterprise grid vision. Services are entities that you can define in Oracle RAC databases that enable you to group database workloads, route work to the optimal instances that are assigned to offer the service, and achieve high availability for planned and unplanned actions.
-
High Availability Framework: An Oracle RAC component that enables Oracle Database to always maintain components in a running state.
-
Fast Application Notification (FAN): Provides information to Oracle RAC applications and clients about cluster state changes and Load Balancing Advisory events, such as
UPandDOWNevents for instances, services, or nodes. FAN has two methods for publishing events to clients, the Oracle Notification Service daemon, which is used by Java Database Connectivity (JDBC) clients including the Oracle Application Server, and Oracle Streams Advanced Queueing, which is used by Oracle Call Interface (OCI) and Oracle Data Provider for .NET (ODP.NET) clients.Note:
In previous releases of Oracle Clusterware, OCI and ODP.NET clients received FAN events through Oracle Streams Advanced Queuing. -
Transaction Guard: A tool that provides a protocol and an API for at-most-once execution of transactions in case of unplanned outages and duplicate submissions.
-
Application Continuity: Provides a general purpose infrastructure that replays the in-flight request when a recoverable error is received, masking many system, communication, and storage outages, and hardware failures. Unlike existing recovery technologies, this feature attempts to recover the transactional and non-transactional session states beneath the application, so that the outage appears to the application as a delayed execution.
-
Connection Load Balancing: A feature of Oracle Net Services that balances incoming connections across all of the instances that provide the requested database service.
-
Load Balancing Advisory: Provides information to applications about the current service levels that the database and its instances are providing. The load balancing advisory makes recommendations to applications about where to direct application requests to obtain the best service based on the management policy that you have defined for that service. Load balancing advisory events are published through Oracle Notification Service.
-
Automatic Workload Repository (AWR): Tracks service-level statistics as metrics. Server generated alerts can be created for these metrics when they exceed or fail to meet certain thresholds.
-
Fast Connection Failover: This is the ability of Oracle Clients to provide rapid failover of connections by subscribing to FAN events.
-
Runtime Connection Load Balancing: This is the ability of Oracle Clients to provide intelligent allocations of connections in the connection pool based on the current service level provided by the database instances when applications request a connection to complete some work.
-
Single Client Access Name (SCAN): Provides a single name to the clients connecting to Oracle RAC that does not change throughout the life of the cluster, even if you add or remove nodes from the cluster. Clients connecting with SCAN can use a simple connection string, such as a thin JDBC URL or EZConnect, and still achieve the load balancing and client connection failover.
You can deploy Oracle RAC and noncluster Oracle database environments to use dynamic database service features in many different ways. Depending on the number of nodes and your environment's complexity and objectives, your choices for optimal automatic workload management and high-availability configuration depend on several considerations that are described in this chapter.
Overview of Server Pools and Policy-Managed Databases
You can create Oracle RAC databases, whether multinode or Oracle Real Application Clusters One Node (Oracle RAC One Node), using the following deployment models:
-
Administrator-managed deployment is based on the Oracle RAC deployment types that existed before Oracle Database 11g release 2 (11.2) and requires that you statically configure each database instance to run on a specific node in the cluster, and that you configure database services to run on specific instances belonging to a certain database using the
preferredandavailabledesignation. -
Policy-managed deployment is based on server pools, where database services run within a server pool as singleton or uniform across all of the servers in the server pool. Databases are deployed in one or more server pools and the size of the server pools determine the number of database instances in the deployment.
This section includes the following topics:
Introduction to Server Pools
Server pools logically apportion a cluster into groups of servers offering database or application services. Server pool properties control the scalability and availability of those databases and applications. You can configure each server pool with a minimum and maximum size, which determines scalability. Oracle Clusterware manages availability between server pools, and you can further regulate availability by configuring the importance value of individual server pools.
Servers are not assigned to server pools by name but by number. Therefore, you must configure any server to run any database. If you cannot configure servers due to, for example, heterogeneous servers or storage connectivity, then you can restrict servers by using server category definitions to determine server pool membership eligibility.
See Also:
Oracle Clusterware Administration and Deployment Guide for more information about creating and managing server poolsExamples of Using Server Pools
This section includes the following examples of using server pools:
Minimum and Maximum Number of Servers
Consider a four-node cluster configured into two server pools named online and backoffice. A database named dbsales runs in the online server pool offering the browse, search, and salescart services. A database named dberp runs in the backoffice server pool and offers the inventory and shipping services, as shown in Figure 1-2. During normal business hours the enterprise requires a minimum of two instances of the dbsales database and one instance of the dberp database to meet normal demand.
Figure 1-2 Server Placement by Minimum and Maximum Limits
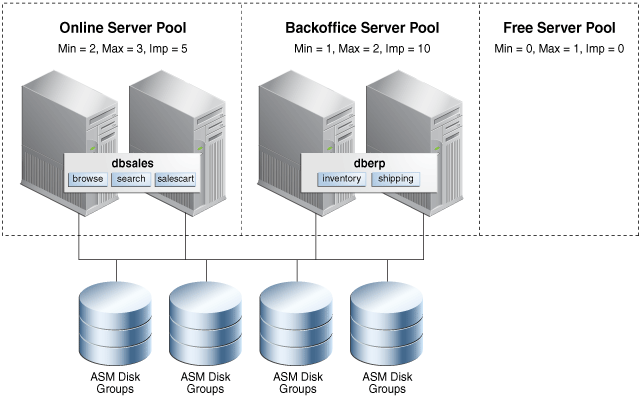
Description of "Figure 1-2 Server Placement by Minimum and Maximum Limits"
In this policy-managed deployment, the value of the MIN_SIZE server pool attribute for the online server pool is 2, while the value of the MIN_SIZE server pool attribute for the backoffice server pool is 1. Configured this way, Oracle Clusterware ensures that there are always two servers in the online server pool and one server in the backoffice server pool. Because this is a four-node cluster, there is one server left not assigned to either server pool. Where that last server gets deployed is determined by the MAX_SIZE server pool parameter of each server pool. If the sum of the values of the MAX_SIZE server pool attribute for each server pool is less than the total number of servers in the cluster, then the remaining servers stay in the Free server pool awaiting a failure of a deployed node.
If the value of MAX_SIZE is greater than that of MIN_SIZE, then the remaining server will be deployed into the server pool whose importance value is greatest, as shown in Figure 1-2, and fully discussed in the next section. In this case, the server is a shareable resource that can be relocated online to join the server pool where it is required. For example, during business hours the server could be given to the online server pool to add an instance of the dbsales database but after hours could be relocated to the backoffice server pool, adding a dberp database instance. All such movements are online and instances are shut down, transactionally.
These two policy-managed databases are running only the instances that are required and they can be dynamically increased or decreased to meet demand or business requirements.
IMPORTANCE Attribute of Server Pools
The IMPORTANCE server pool attribute is used at cluster startup and in response to a node failure or eviction. In contrast to administrator-managed databases, you can configure server pools with different importance levels to determine which databases are started first and which databases remain online in case there is a multinode outage.
Consider a four-node cluster that hosts a database named dbapps in two server pools, sales and backoffice. Two services, orderentry and billing, run in the sales server pool, while two other services, erp and reports, run in the backoffice server pool, as shown in Figure 1-3. By configuring the value of the IMPORTANCE server pool attribute of the sales server pool higher than that of the backoffice server pool, the services in sales start first when the cluster starts and are always available, even if there is only one server left running after a multinode failure. The IMPORTANCE server pool attribute enables you to rank services and also eliminates the requirement to run a service on all nodes in a cluster to ensure that it is always available.
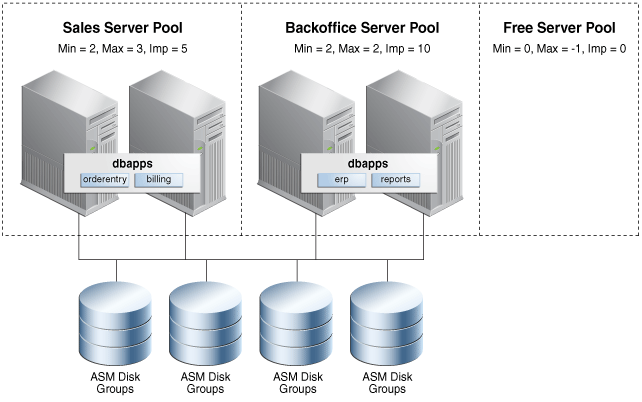
You can use several different approaches, either discretely or combined, to consolidate Oracle databases. Policy-managed deployments facilitate consolidation. In the case of schema consolidation, where multiple applications are being hosted in a single database separated into discrete schemas or pluggable databases (PDBs), you can use server pools to meet required capacity. Because of the dynamic scaling property of server pools, you can increase or decrease the number of database instances to meet current demand or business requirements. Since server pools also determine which services run together or separately, you can configure and maintain required affinity or isolation.
When it is not possible to use schema consolidation because of, for example, version requirements, you can host multiple databases on a single set of servers. Using policy-managed databases facilitates this database consolidation because they can share the same server pool by making use of instance caging, which enables you to dynamically increase or decrease databases, both horizontally (using server pool size) and vertically (using the CPU_COUNT server configuration attribute) to meet demand or business policies and schedules.
See Also:
Oracle Clusterware Administration and Deployment Guide for more information about theCPU_COUNT server configuration attributeBy contrast, with administrator-managed databases, you are required to reserve capacity on each server to absorb workload failing over should a database instance or server fail. With policy-managed databases, however, you can effectively rank server pools by the business necessity of the workloads that they are running using the MIN_SIZE, MAX_SIZE, and IMPORTANCE server pool attributes.
When the failure of a server brings a server pool to below its configured minimum number of servers, another server will move from a less important server pool to take its place and bring the number of servers back up to the configured minimum. This eliminates the risk of cascade failures due to overloading the remaining servers and enables you to significantly reduce or even eliminate the need to reserve capacity for handling failures.
Migrating or converting to policy-managed databases also enables cluster consolidation and creates larger clusters that have greater availability and scalability because of the increased number of servers available to host and scale databases. Because policy-managed databases do not require binding their instance names to a particular server and binding services to particular instances, the complexity of configuring and managing large clusters is greatly reduced.
An example deployment is shown in Figure 1-4 where the previous two cluster examples (shown in Figure 1-2 and Figure 1-3) are consolidated into a single cluster, making use of both database consolidation (using instance caging) and cluster consolidation (using server pools) configured so that workloads are properly sized and prioritized.
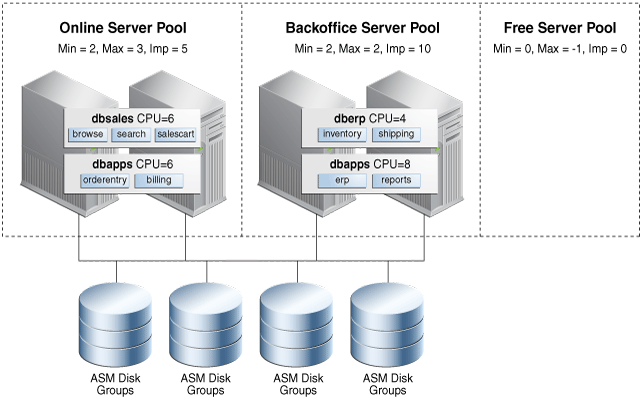
Deploying Policy-Managed Databases
When you deploy a policy-managed database you must first determine the services and their required sizing, taking into account that services cannot span server pools. If you are going to collocate this database with other databases, then you should factor in its CPU requirements relative to the other hosted databases, and also factor in the value of its CPU_COUNT attribute for instance caging, so that you can size the database both vertically and horizontally in one or more server pools.
If you are going to collocate the server pools for this database with other server pools, then consider configuring the server pools to adjust the server pool sizes on a calendar or event basis to optimize meeting demand and business requirements. Once you have determined the sizes of the server pools, and configured the appropriate values for the MIN_SIZE and MAX_SIZE server pool attributes, you can then determine the relative importance of each server pool.
See Also:
Oracle Clusterware Administration and Deployment Guide for more information about server pool attributesYou, as the cluster administrator, create policy-managed database server pools using the srvctl add serverpool command. You can modify the properties of the server pool using the srvctl modify serverpool command in the Oracle Grid Infrastructure home.
See Also:
Oracle Database Quality of Service Management User's Guide for more information about creating server poolsWhile it is possible to create a server pool using DBCA, Oracle recommends this only for small, single server pool deployments, because DBCA will fail if servers are already allocated to other server pools. Additionally, if the cluster is made up of servers with different capacities, such as old and new servers, Oracle recommends that you set up server category definitions defining the minimum server requirements for a server to join each server pool.
See Also:
Oracle Clusterware Administration and Deployment Guide for more information about server categorizationAfter you create the server pools, you can run DBCA from the appropriate database home. Depending on the database type and task, you will be presented with different default options. For all new Oracle RAC and Oracle RAC One Node databases, including container databases (CDBs), the Policy-Managed option is the default and the option that Oracle recommends.
If you are upgrading your database from an administrator-managed database or a database earlier than Oracle Database 11g release 2 (11.2), then you will not have the option to directly upgrade to a policy-managed database. After you upgrade, however, you can convert the database to policy managed using the srvctl modify database command.
When you convert from an administrator-managed database to a policy-managed database, the instance names are automatically updated to include the underscore (for example: orcl1 becomes orcl_1). The underscore is required so that the database can automatically create instances when a server pool grows in size.
Managing Policy-Managed Databases
Managing a policy-managed database requires less configuration and reconfiguration steps than an administrator-managed one with respect to creation, sizing, patching, and load balancing. Also, because any server in the server pools within the cluster can run any of the databases, you do not have to create and maintain database instance-to-node-name mappings. You can perform maintenance tasks such as patching by relocating servers into the Free pool or by adjusting the server pool minimum and maximum sizes, thereby retaining required availability.
Policy-managed databases also facilitate the management of services, because they are assigned to a single server pool and run as singletons or uniform across all servers in the pool. You no longer have to create or maintain explicit preferred and available database instance lists for each service. If a server moves into a server pool because of manual relocation or a high availability event, all uniform services and their dependent database instances are automatically started. If a server hosting one or more singleton services goes down, those services will automatically be started on one or more of the remaining servers in the server pool. In the case of Oracle RAC One Node, the corresponding database instance will also be started automatically.
Managing services relative to each other is improved by making use of the importance attribute of each server pool. Each service running in a server pool inherits the server pool's importance relative to the other server pool-hosted services in the cluster. If the minimum size of the most important server pool is greater than zero, then the services and associated database instances in that server pool are started first on cluster startup and will be the last services and database instances running, as long as there is one server running in the cluster. You can offer services not critical to the business in the least important server pool, ensuring that, should sufficient resources not be available due to demand or failures, those services will eventually be shut down and the more business-critical services remain available.
Because many management tasks may involve making changes that can affect multiple databases, services, or server pools in a consolidated environment, you can use the evaluate mode for certain SRVCTL commands to get a report of the resource impact of a command.
Consider the following example, that evaluates the effect on the system of modifying a server pool:
$ srvctl modify srvpool -l 3 -g online -eval
Service erp1 will be stopped on node test3
Service reports will be stopped on node test3
Service inventory will be stopped on node test3
Service shipping will be stopped on node test3
Database dbsales will be started on node test3
Service orderentry will be started on node test3
Service billing will be started on node test3
Service browse will be started on node test3
Service search will be started on node test3
Service salescart will be started on node test3
Server test3 will be moved from pool backoffice to pool online
As shown in the preceding example, modifying a server pool can result in many resource state changes. You can use a policy set through either Oracle Clusterware or Oracle Database Quality of Service Management.
See Also:
-
"SRVCTL Usage Information" for a list of SRVCTL commands which use the evaluate mode
-
Oracle Clusterware Administration and Deployment Guide for information about the Oracle Clusterware policy set
-
Oracle Database Quality of Service Management User's Guide for information about the Oracle Database Quality of Service Management policy set
Policy-Based Cluster Management
In Oracle Database 12c, Oracle Clusterware supports the management of a cluster configuration policy set as a native Oracle Clusterware feature. A cluster configuration policy contains one definition for each server pool that is defined in the system. A cluster configuration policy also specifies resource placement and cluster node availability. A cluster configuration policy set defines the names of all of the server pools that are configured in a cluster, and contains one or more configuration policies.
There is always only one configuration policy in effect at any one time. However, administrators typically create several configuration policies to reflect the different business needs and demands based on calendar dates or time of day parameters. For instance, morning hours during business days are typically when most users log in and download their email; email-related workloads are usually light at nighttime and on weekends. In such cases, you can use cluster configuration policies to define the server allocation based on the expected demand. More specifically for this example, a configuration policy that allocates more servers to OLTP workloads is in effect during workday mornings, and another configuration policy allocates more servers to batch workloads on weekends and workday evenings.
Using cluster configuration policies can also help manage clusters that comprise servers of different capabilities, such as different computer and memory sizes (heterogeneous). To create management and availability policies for clusters comprised of heterogeneous server types, the cluster administrator can create server categories based on server attributes. These attributes can restrict which servers can be assigned to which server pools. For example, if you have some servers in a cluster that run older hardware, then you can use an attribute to specify that these servers should only be allocated to the server pools that support batch jobs and testing, instead of allocating them to the server pools that are used for online sales or other business-critical applications.
See Also:
Oracle Clusterware Administration and Deployment Guide for more informationOverview of Installing Oracle RAC
Install Oracle Grid Infrastructure and Oracle Database software using Oracle Universal Installer, and create your database with Database Configuration Assistant (DBCA). This ensures that your Oracle RAC environment has the optimal network configuration, database structure, and parameter settings for the environment that you selected.
Alternatively, you can install Oracle RAC using Rapid Home Provisioning.
See Also:
Oracle Real Application Clusters Installation Guide for your platform for more information about installing Oracle RAC using Rapid Home ProvisioningThis section introduces the installation processes for Oracle RAC under the following topics:
-
Oracle RAC Database Management Styles and Database Installation
-
Overview of Extending an Oracle RAC Cluster
Note:
You must first install Oracle Grid Infrastructure before installing Oracle RAC.
See Also:
Oracle Grid Infrastructure Installation Guide for your platformUnderstanding Compatibility in Oracle RAC Environments
To run Oracle RAC in configurations with different versions of Oracle Database in the same cluster, you must first install Oracle Grid Infrastructure, which must be the same version, or higher, as the highest version of Oracle Database that you want to deploy in this cluster. For example, to run an Oracle RAC 11g release 2 (11.2) database and an Oracle RAC 12c database in the same cluster, you must install Oracle Grid Infrastructure 12c. Contact My Oracle Support for more information about version compatibility in Oracle RAC environments.
Note:
Oracle does not support deploying an Oracle9i cluster in an Oracle Grid Infrastructure 12c environment.Oracle RAC Database Management Styles and Database Installation
Before installing the Oracle RAC database software and creating respective databases, decide on the management style you want to apply to the Oracle RAC databases, as described in "Overview of Server Pools and Policy-Managed Databases".
The management style you choose impacts the software deployment and database creation. If you choose the administrator-managed database deployment model, using a per-node installation of software, then it is sufficient to deploy the Oracle Database software (the database home) on only those nodes on which you plan to run Oracle Database.
If you choose the policy-managed deployment model, using a per-node installation of software, then you must deploy the software on all nodes in the cluster, because the dynamic allocation of servers to server pools, in principle, does not predict on which server a database instance can potentially run. To avoid instance startup failures on servers that do not host the respective database home, Oracle strongly recommends that you deploy the database software on all nodes in the cluster. When you use a shared Oracle Database home, accessibility to this home from all nodes in the cluster is assumed and the setup needs to ensure that the respective file system is mounted on all servers, as required.
Oracle Universal Installer will only allow you to deploy an Oracle Database home across nodes in the cluster if you previously installed and configured Oracle Grid Infrastructure for the cluster. If Oracle Universal Installer does not give you an option to deploy the database home across all nodes in the cluster, then check the prerequisite, as stated, by Oracle Universal Installer.
During installation, you can choose to create a database during the database home installation. Oracle Universal Installer runs DBCA to create your Oracle RAC database according to the options that you select.
See Also:
"Oracle RAC Database Management Styles and Database Creation" for more information if you choose this optionNote:
Before you create a database, a default listener must be running in the Oracle Grid Infrastructure home. If a default listener is not present in the Oracle Grid Infrastructure home, then DBCA returns an error instructing you to run NETCA from the Oracle Grid Infrastructure home to create a default listener.See Also:
Oracle Database Net Services Administrator's Guide for more information about NETCAThe Oracle RAC software is distributed as part of the Oracle Database installation media. By default, the Oracle Database software installation process installs the Oracle RAC option when it recognizes that you are performing the installation on a cluster. Oracle Universal Installer installs Oracle RAC into a directory structure referred to as the Oracle home, which is separate from the Oracle home directory for other Oracle software running on the system. Because Oracle Universal Installer is cluster aware, it installs the Oracle RAC software on all of the nodes that you defined to be part of the cluster.
Oracle RAC Database Management Styles and Database Creation
Part of Oracle Database deployment is the creation of the database. You can choose to create a database as part of the database software deployment, as described in "Oracle RAC Database Management Styles and Database Installation", or you can choose to only deploy the database software, first, and then, subsequently, create any database that is meant to run out of the newly created Oracle home by using DBCA. In either case, you must consider the management style that you plan to use for the Oracle RAC databases.
For administrator-managed databases, you must ensure that the database software is deployed on the nodes on which you plan to run the respective database instances. You must also ensure that these nodes have access to the storage in which you want to store the database files. Oracle recommends that you select Oracle ASM during database installation to simplify storage management. Oracle ASM automatically manages the storage of all database files within disk groups. If you plan to use Oracle Database Standard Edition to create an Oracle RAC database, then you must use Oracle ASM to store all of the database files.
For policy-managed databases, you must ensure that the database software is deployed on all nodes on which database instances can potentially run, given your active server pool setup. You must also ensure that these nodes have access to the storage in which you want to store the database files. Oracle recommends using Oracle ASM, as previously described for administrator-managed databases.
Server pools are a feature of Oracle Grid Infrastructure (specifically Oracle Clusterware). There are different ways you can set up server pools on the Oracle Clusterware level, and Oracle recommends you create server pools for database management before you create the respective databases. DBCA, however, will present you with a choice of either using precreated server pools or creating a new server pool, when you are creating a policy-managed database. Whether you can create a new server pool during database creation depends on the server pool configuration that is active at the time.
Notes:
You must configure Oracle ASM separately before you create an Oracle RAC database.See Also:
Oracle Clusterware Administration and Deployment Guide for more information on managing server poolsBy default, DBCA creates one service for your Oracle RAC installation. This is the default database service and should not be used for user connectivity. The default database service is typically identified using the combination of the DB_NAME and DB_DOMAIN initialization parameters: db_name.db_domain. The default service is available on all instances in an Oracle RAC environment, unless the database is in restricted mode.
Note:
Oracle recommends that you reserve the default database service for maintenance operations and create dynamic database services for user or application connectivity as a post-database-creation step, using either SRVCTL or Oracle Enterprise Manager. DBCA no longer offers a dynamic database service creation option for Oracle RAC databases. For Oracle RAC One Node databases, you must create at least one dynamic database service.Overview of Extending an Oracle RAC Cluster
If you want to extend the Oracle RAC cluster (also known as cloning) and add nodes to the existing environment after your initial deployment, then you must to do this on multiple layers, considering the management style that you currently use in the cluster. Oracle provides various means of extending an Oracle RAC cluster. In principle, you can choose from two different approaches to extend the current environment:
-
Cloning using cloning scripts
-
Adding nodes using the
addnode.sh(addnode.baton Windows) scriptSee Also:
Chapter 10, "Adding and Deleting Oracle RAC from Nodes on Linux and UNIX Systems" or Chapter 11, "Adding and Deleting Oracle RAC from Nodes on Windows Systems" depending on your platform
Both approaches are applicable, regardless of how you initially deployed the environment. Both approaches copy the required Oracle software on to the node that you plan to add to the cluster. Software that gets copied to the node includes the Oracle Grid Infrastructure software and the Oracle database homes.
For Oracle database homes, you must consider the management style deployed in the cluster. For administrator-managed databases, you must ensure that the database software is deployed on the nodes on which you plan to run the respective database instances. For policy-managed databases, you must ensure that the database software is deployed on all nodes on which database instances can potentially run, given your active server pool setup. In either case, you must first deploy Oracle Grid Infrastructure on all nodes that are meant to be part of the cluster.
Note:
Oracle cloning is not a replacement for cloning using Oracle Enterprise Manager as part of the Provisioning Pack. When you clone Oracle RAC using Oracle Enterprise Manager, the provisioning process includes a series of steps where details about the home you want to capture, the location to which you want to deploy, and various other parameters are collected.For new installations or if you install only one Oracle RAC database, use the traditional automated and interactive installation methods, such as Oracle Universal Installer, or the Provisioning Pack feature of Oracle Enterprise Manager. If your goal is to add or delete Oracle RAC from nodes in the cluster, you can use the procedures detailed in Chapter 10, "Adding and Deleting Oracle RAC from Nodes on Linux and UNIX Systems".
The cloning process assumes that you successfully installed an Oracle Clusterware home and an Oracle home with Oracle RAC on at least one node. In addition, all root scripts must have run successfully on the node from which you are extending your cluster database.
See Also:
Oracle Enterprise Manager online Help system for more information about the Provisioning PackOverview of Oracle Multitenant with Oracle RAC
Oracle Multitenant is an option with Oracle Database 12c that simplifies consolidation, provisioning, upgrades, and more. It is based on an architecture that allows a multitenant container database (CDB) to hold several pluggable databases (PDBs). You can adopt an existing database as a PDB without having to change the application tier. In this architecture, Oracle RAC provides the local high availability that is required when consolidating various business-critical applications on one system.
When using PDBs with Oracle RAC, the multitenant CDB is based on Oracle RAC. You can make each PDB available on either every instance of the Oracle RAC CDB or a subset of instances. In either case, access to and management of the PDBs are regulated using dynamic database services, which will also be used by applications to connect to the respective PDB, as they would in a single instance Oracle database using Oracle Net Services for connectivity.
If you create an Oracle RAC database as a CDB and plug one or more PDBs into the CDB, then, by default, a PDB is not started automatically on any instance of the Oracle RAC CDB. With the first dynamic database service assigned to the PDB (other than the default database service which has the same name as the database name), the PDB is made available on those instances on which the service runs.
Whether a PDB is available on more than one instance of an Oracle RAC CDB, the CDB is typically managed by the services running on the PDB. You can manually enable PDB access on each instance of an Oracle RAC CDB by starting the PDB manually on that instance.
Overview of In-Memory Column Store with Oracle RAC
Each node in an Oracle RAC environment has its own In-Memory (IM) column store. Oracle recommends that you equally size the IM column stores on each Oracle RAC node. For any Oracle RAC node that does not require an IM column store, set the INMEMORY_SIZE parameter to 0.
It is possible to have completely different objects populated on every node, or to have larger objects distributed across all of the IM column stores in the cluster. It is also possible to have the same objects appear in the IM column store on every node (on engineered systems, only). The distribution of objects across the IM column stores in a cluster is controlled by two additional sub-clauses to the INMEMORY attribute; DISTRIBUTE and DUPLICATE.
In an Oracle RAC environment, an object that only has the INMEMORY attribute specified on it is automatically distributed across the IM column stores in the cluster. The DISTRIBUTE clause can be used to specify how an object is distributed across the cluster. By default, the type of partitioning used (if any) determines how the object is distributed. If the object is not partitioned it is distributed by rowid range. Alternatively, you can specify the DISTRIBUTE clause to over-ride the default behavior.
On an Engineered System, it is possible to duplicate or mirror objects populated in memory across the IM column store in the cluster. This provides the highest level of redundancy. The DUPLICATE clause is used to control how an object should be duplicated across the IM column stores in the cluster. If you specify just DUPLICATE, then one mirrored copy of the data is distributed across the IM column stores in the cluster. If you want to duplicate the entire object in each IM column store in the cluster, then specify DUPLICATE ALL.
Note:
When you deploy Oracle RAC on a non-Engineered System, theDUPLICATE clause is treated as NO DUPLICATE.See Also:
Oracle Database Concepts for more information about IM column storeOverview of Managing Oracle RAC Environments
This section describes the following Oracle RAC environment management topics:
About Designing and Deploying Oracle RAC Environments
Any enterprise that is designing and implementing a high availability strategy with Oracle RAC must begin by performing a thorough analysis of the business drivers that require high availability. An analysis of business requirements for high availability combined with an understanding of the level of investment required to implement different high availability solutions enables the development of a high availability architecture that achieves both business and technical objectives.
See Also:
For help choosing and implementing the architecture that best fits your availability requirements:-
Chapter 12, "Design and Deployment Techniques" provides a high-level overview you can use to evaluate the high availability requirements of your business.
-
Oracle Database High Availability Overview describes how to select the most suitable architecture for your organization, describes several high availability architectures, and provides guidelines for choosing the one that best meets your requirements.
-
Oracle Database High Availability Overview for information about the Oracle Maximum Availability Architecture
About Administrative Tools for Oracle RAC Environments
You administer a cluster database as a single-system image using the Server Control Utility (SRVCTL), Oracle Enterprise Manager, or SQL*Plus
-
Server Control Utility (SRVCTL): SRVCTL is a command-line interface that you can use to manage an Oracle RAC database from a single point. You can use SRVCTL to start and stop the database and instances and to delete or move instances and services. You can also use SRVCTL to manage configuration information, Oracle Real Application Clusters One Node (Oracle RAC One Node), Oracle Clusterware, and Oracle ASM.
-
Oracle Enterprise Manager: Oracle Enterprise Manager Cloud Control GUI interface for managing both noncluster database and Oracle RAC database environments. Oracle recommends that you use Oracle Enterprise Manager to perform administrative tasks whenever feasible.
You can use Oracle Enterprise Manager Cloud Control to also manage Oracle RAC One Node databases.
-
SQL*Plus: SQL*Plus commands operate on the current instance. The current instance can be either the local default instance on which you initiated your SQL*Plus session, or it can be a remote instance to which you connect with Oracle Net Services.
-
Cluster Verification Utility (CVU): CVU is a command-line tool that you can use to verify a range of cluster and Oracle RAC components, such as shared storage devices, networking configurations, system requirements, and Oracle Clusterware, in addition to operating system groups and users. You can use CVU for preinstallation checks and for postinstallation checks of your cluster environment. CVU is especially useful during preinstallation and during installation of Oracle Clusterware and Oracle RAC components. Oracle Universal Installer runs CVU after installing Oracle Clusterware and Oracle Database to verify your environment.
Install and use CVU before you install Oracle RAC to ensure that your configuration meets the minimum Oracle RAC installation requirements. Also, use CVU for verifying the completion of ongoing administrative tasks, such as node addition and node deletion.
-
DBCA: The recommended utility for creating and initially configuring Oracle RAC, Oracle RAC One Node, and Oracle noncluster databases.
-
NETCA: Configures the network for your Oracle RAC environment.
See Also:
-
Chapter 3, "Administering Database Instances and Cluster Databases" for an introduction to Oracle RAC administration using SRVCTL, Oracle Enterprise Manager, and SQL*Plus
-
Appendix A, "Server Control Utility Reference" for SRVCTL reference information
-
Oracle Clusterware Administration and Deployment Guide for information about the Cluster Verification Utility (CVU), in addition to other Oracle Clusterware tools, such as the OIFCFG tool for allocating and deallocating network interfaces and the
OCRCONFIGcommand-line tool for managing OCR -
Oracle Database Net Services Administrator's Guide for more information about NETCA
About Monitoring Oracle RAC Environments
Web-based Oracle Enterprise Manager Cloud Control enables you to monitor an Oracle RAC database. Oracle Enterprise Manager Cloud Control is a central point of control for the Oracle environment that you access by way of a graphical user interface (GUI). See "Monitoring Oracle RAC and Oracle Clusterware" and the Oracle Database 2 Day + Real Application Clusters Guide for detailed information about using Oracle Enterprise Manager to monitor Oracle RAC environments.
Also, note the following recommendations about monitoring Oracle RAC environments:
-
Use Oracle Enterprise Manager Cloud Control to initiate cluster database management tasks.
-
Use Oracle Enterprise Manager Cloud Control to administer multiple or individual Oracle RAC databases.
-
Use the global views (
GV$views), which are based onV$views. Thecatclustdb.sqlscript creates theGV$views. Run this script if you do not create your database with DBCA. Otherwise, DBCA runs this script for you.For almost every
V$view, there is a corresponding globalGV$view. In addition to theV$information, eachGV$view contains an extra column namedINST_ID, which displays the instance number from which the associatedV$view information was obtained. -
Use the sophisticated management and monitoring features of the Oracle Database Diagnostic and Tuning packs within Oracle Enterprise Manager that include the Automatic Database Diagnostic Monitor (ADDM) and Automatic Workload Repository (AWR).
See Also:
-
Oracle Database Performance Tuning Guide for descriptions of the Oracle Database automatic features for performance diagnosing and tuning, including ADDM
-
Oracle Database 2 Day + Real Application Clusters Guide for more information about monitoring performance and troubleshooting
About Evaluating Performance in Oracle RAC Environments
You do not need to perform special tuning for Oracle RAC; Oracle RAC scales without special configuration changes. If your application performs well on a noncluster Oracle database, then it will perform well in an Oracle RAC environment. Many of the tuning tasks that you would perform on a noncluster Oracle database can also improve Oracle RAC database performance. This is especially true if your environment requires scalability across a greater number of CPUs.
Some of the performance features specific to Oracle RAC include:
-
-
Oracle Database dynamically allocates Cache Fusion resources as needed
-
The dynamic mastering of resources improves performance by keeping resources local to data blocks
-
-
Cache Fusion enables a simplified tuning methodology
-
You do not have to tune any parameters for Cache Fusion
-
No application-level tuning is necessary
-
You can use a bottom-up tuning approach with virtually no effect on your existing applications
-
-
More detailed performance statistics
-
More views for Oracle RAC performance monitoring
-
Oracle RAC-specific performance views in Oracle Enterprise Manager
-
Footnote Legend
Footnote 1: With Oracle Database 10g release 2 (10.2) and later releases, Oracle Clusterware supports 100 nodes in an Oracle Clusterware standard Cluster, with the option to run 100 database instances belonging to one production database on these nodes.